

TL;DR
- Ranking adds latency in three places: a wider candidate pool, per-item scoring that scales linearly, and slow feature joins across multiple stores.
- Move expensive work off the read path with write-time scoring for normal accounts and read-time scoring only for accounts with very large followings.
- Put a cheap retrieval stage in front of your expensive ranking model, so adding more items doesn't slow the feed down.
- Fetch features in parallel, not in series. This single change often cuts more latency than any model optimization.
Chronological feeds are fast because the read path does almost nothing: query an index, sort by timestamp, return the results.
You introduce feed ranking without increasing latency by moving scoring to write time, putting a cheap retrieval stage in front of your ranking model, and fetching features in parallel rather than in series.
The challenge is that somewhere in the pipeline, a model has to score items, and scoring takes time. So, the question isn't whether to pay that cost, but when and where.
Why Does Ranking Add Latency in the First Place?
It helps to be specific about where the time actually goes, because the fixes map directly onto the causes. There are three.
The first is that your candidate pool grows. A chronological feed pulls maybe 30 recent items per page and returns exactly those. A ranked feed needs options to choose from, so it pulls a much wider net, scores everything, and keeps the best handful. To put a number on it: showing the best 30 posts might mean reading 2,000 candidates and discarding 1,970. Both a chronological feed and a ranked feed return 30 items, but the ranking requires more than 60 times as many rows to be read and shipped to the ranker.
The second is that scoring runs per-item and scales linearly. Even a fast model is doing substantial work for each candidate: a feature join, an embedding lookup, and a forward pass. At 0.1ms per item, the cost climbs in step with the pool you just widened:
| Candidate pool | Scoring time |
|---|---|
| 100 | 10ms |
| 1,000 | 100ms |
| 5,000 | 500ms |
A model that feels instant on a single item becomes half a second once you fan it across 5,000, which is why the candidate pool can't grow unchecked.
The third is slow feature joins. This is where most latency hides. A single, ranked request for 1,000 candidates might need four different things from four different systems:
- What this user tends to engage with, learned from their past behavior.
- How popular each candidate post already is, based on its current like and comment counts.
- What the user did in the last few minutes, the posts they tapped, and how long they stayed on each.
- How closely the user is connected to each post's author, determined from the follow graph.
Each lives in its own store, and the model can't start scoring until the slowest one comes back. Teams blame the model for being slow, when the spread across these stores is often the real cost.
Where Should the Ranking Work Happen?
This is the single biggest architectural decision, and the one most teams get wrong on the first pass. The scoring can live in three places, and the right answer is usually a mix.
| Approach | Read latency | Freshness | Cost model | Best fit |
|---|---|---|---|---|
| Read-time | High. Scoring sits on the request path | Full. Any signal available at request | Paid per read | Low-traffic feeds, highly dynamic signals |
| Write-time | Low. Read is a sorted lookup | Frozen at write, no session context | Paid per recipient at publish | Active users, stable signals |
| Async re-rank | Low first paint, sharpens after | Full, computed in the background | Paid per read, off the critical path | Clients with a WebSocket or render-then-update flow |
The choice between read-time and write-time usually comes down to fan-out. Write-time scoring costs roughly one computation per recipient, paid whether or not anyone reads. The asymmetry shows up the moment you compare a typical user to a popular one:
- 300 followers: one post triggers about 300 score computations. Cheap, and most of those feeds get opened.
- 50M followers: one post triggers about 50M computations at publish, most for feeds nobody opens that day.
The fix is to precompute scores on write for normal accounts, and score on read for the rare account with a huge following.
Async re-ranking avoids the choice entirely. You return a fast feed right away, then run the full model in the background and push the reordered version over a websocket. The catch is that items can visibly reorder, so teams usually only re-rank what the user hasn't scrolled to yet.
What Is Two-Stage Ranking?
Two-stage ranking keeps the scoring cost flat, no matter how many items the feed could show. You do the work in two passes. The first is fast and narrows that huge set down to a few hundred candidates. The second runs your expensive scoring model, but only on those candidates, never on the full set.

Each stage hands a smaller set to the next, so the expensive model never runs over every item.
The first pass, retrieval, gathers candidates using fast methods that don't score anything: recent posts, posts from accounts the user follows, and a quick similarity lookup for items close to the user's interests (more on that below). It also hides anything the user shouldn't see, such as blocked accounts or posts they've already read. These are all fast index reads, so retrieval holds up even with millions of items.
The second pass, ranking, runs the expensive model on that candidate set and nothing else. Because it only ever sees a few hundred items, its cost doesn't grow with the total number of items. Twice as many items make the retrieval index slightly bigger, but the ranking step takes exactly as long as before.
That similarity lookup is usually where machine learning comes in, most often as a two-tower model. Both items and users get turned into embeddings: lists of numbers arranged so that similar things land close together.
An item tower encodes every item offline and stores them in an index built for fast nearest-match lookups, called an approximate nearest neighbor (ANN) index. HNSW, ScaNN, and FAISS are common implementations. A user tower encodes the current user at request time, and retrieval finds the items whose embeddings sit closest. Since the items were encoded offline, the only request-time work is one user encoding and one lookup.
How Much Does Feature Caching Matter?
By the time your stages are well structured, feature access is usually what's left between you and low latency.
The trap is fetching features in series. Each await blocks the next, so four sequential lookups stack their latencies before the ranker does any work:
1234567// Serial: each await blocks the next. ~25ms before scoring. const user = await getUserFeatures(userId); const items = await getItemFeatures(candidateIds); const interactions = await getInteractionFeatures(userId, candidateIds); const graph = await getGraphFeatures(userId); const scored = rank(user, items, interactions, graph);
Firing them all at once collapses that to a single wait, as long as the fetches don't depend on each other:
123456789// Parallel: fire everything at once. ~5ms, bound by the slowest fetch. const [user, items, interactions, graph] = await Promise.all([ getUserFeatures(userId), getItemFeatures(candidateIds), getInteractionFeatures(userId, candidateIds), getGraphFeatures(userId), ]); const scored = rank(user, items, interactions, graph);
The only change is that the parallel version waits once instead of four times, and that single change often reduces latency more than any model optimization.
From there, a few patterns push it lower:
- Use an online feature store. Purpose-built systems like Feast or Tecton, or a carefully structured Redis layout, give you sub-millisecond lookups. The keyword is precomputed: the heavy aggregation runs on a schedule, and the request path only reads.
- Co-locate features with candidates. If the features the ranker needs travel alongside the candidate set out of retrieval, two round-trips collapse into one. This is one of the quieter wins in feed infrastructure.
- Serve stale-while-revalidate for slow-moving features. User embeddings, content embeddings, and graph features change slowly. Serve a slightly stale copy and refresh it in the background rather than blocking a request while waiting for a fresh computation.
Fast feature access helps quality, not just speed.
A simpler model with good features almost always beats a complex one that can't get its data in time because the joins are slow. In other words, spend your latency budget on getting good features into a simple model, not on running an elaborate model with poor inputs.
It also pays to have a fallback: if the ranker times out, drop to a simple ordering, like recency plus one strong signal, instead of failing the request.
What Does a Practical Ranked Feed Architecture Look Like?
A production-ranked feed keeps the expensive work off the read path, so each request runs through a short, predictable sequence of steps.
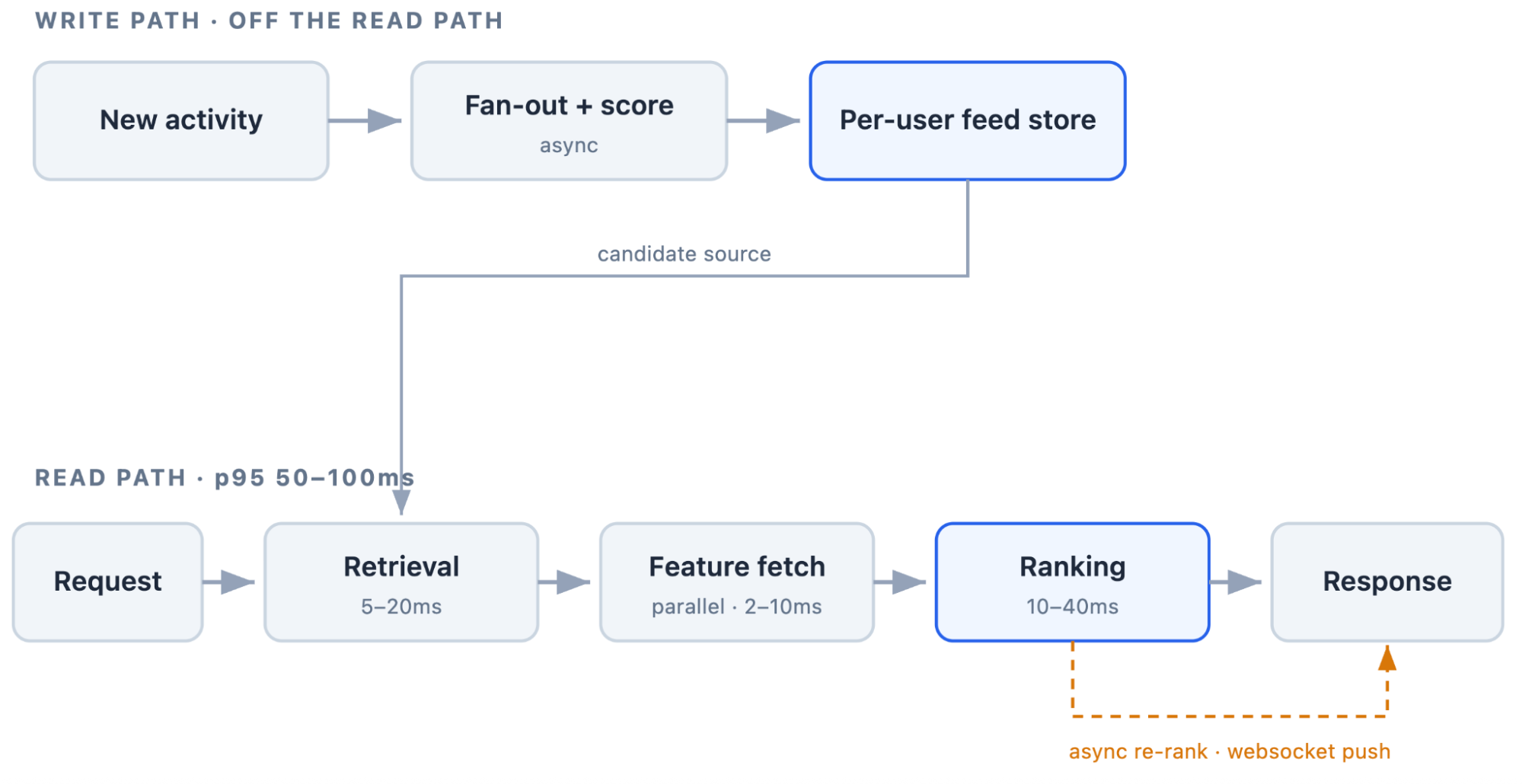
Scoring happens at write time, into each user's own feed store. The read path then retrieves candidates, fetches their features in parallel, ranks them, and responds. An optional second pass can re-rank in the background and push the new order to the app.
The fan-out step determines whether a ranked feed scales or falls over under load. If every read instead triggers a full retrieval and ranking pass over every item, the read path is doing work it shouldn't have to, on every single request.
Precomputing each user's candidate set ahead of time, either when content is published or on a schedule, is what keeps the read path cheap. In a mature feed system, most of the engineering effort goes into that precomputation and the feature infrastructure behind it, not into the ranking model.
What Keeps a Ranked Feed Fast?
The teams that ship fast-ranked feeds tend to do the same handful of things. They move the expensive work off the read path with write-time scoring and precomputed candidate sets. They put a cheap retrieval stage in front of the expensive model, so adding more items doesn't slow the feed down. They treat feature access as real infrastructure: fetching in parallel, keeping features next to the candidates, and caching the slow-changing ones.
The exception is the handful of signals that change too fast to precompute. Those get scored on read, or added in afterward with async re-ranking.
A managed feeds service like Stream's Activity Feeds handles the fan-out and feed storage server-side, which leaves you to add ranking on top rather than rebuild the storage layer.
None of it depends on a fancier model. It comes down to moving as much work as you can off the read path, so the user waits on as little as possible.