


In late 2025, like many Community Sift customers, a top-5 mobile gaming publisher began searching for a replacement as the product was being deprecated. Their team has spent years tuning policies specifically in Community Sift, and by mid-2026, they needed to be completely migrated off the platform.
The migration target: Stream's AI moderation stack covering 750M+ monthly active users, and a multilingual moderation operation spanning more than a dozen languages across multiple regional teams. The timeline: six months. The constraint: no degradation in moderation quality during the cutover, and no operational disruption for their moderation team that had been running the same workflow for years.
Stream's AI Moderation covers text, image, video, and audio across 50+ languages from a single API, the same global backbone that runs Stream Chat, Video, and Feeds. The product exists to do one thing: help teams build safer communities without rebuilding their trust and safety infrastructure.
This is a look at what that migration actually looked like. The RFP process includes testing methodology, infrastructure requirements, workshops with the trust and safety team, shadow testing, and more.

Why are gaming companies migrating off Community Sift in 2026?
For more than a decade, Community Sift (acquired by Microsoft via Two Hat) has been the default content moderation layer for large gaming platforms. It is being sunsetted. That single fact has put dozens of trust & safety teams into vendor evaluation cycles they did not plan for, on timelines they did not choose.
The publisher we worked with is one of the more sophisticated trust & safety operations in the industry. Their team manages policy and quality assurance across more than a dozen languages, with regional specialists, weekly review cadences, and severity bands tuned game-by-game. Migrating that operation is not a vendor swap. It is a full rebuild of the tooling layer underneath a mature human workflow without breaking the workflow.
That framing shaped everything else in the deal.
How does a top-5 publisher evaluate a content moderation vendor?
The publisher ran a structured RFP.
Selection criteria:
- Detection quality across their specific language mix. English is a minority of traffic for a global mobile gaming publisher. The languages that matter for player safety include Arabic, Turkish, Russian, Hindi (often written in Latin script), Chinese, Japanese, Korean, Indonesian, and several European languages, many of which are mixed inline within the same message.
- Latency under production load. A moderation API that adds 300ms to a chat send is unusable at gaming scale. The RFP set explicit latency budgets for both chat and username moderation surfaces, and required vendor benchmarks at the publisher's expected peak of 4,000-5,000 requests per second.
- Willingness to iterate during the evaluation. Any vendor can produce a polished demo. The publisher specifically tested whether vendors would tune to their data, on their schedule, against their known-failure cases, a proxy for what the post-contract relationship would actually look like.
- Cross-surface coverage in a single contract. Chat, usernames, and more. The fewer vendors in the moderation stack, the fewer integrations to maintain and the fewer accountability gaps when something slips through.
- Compliance posture and security maturity. Subprocessor list, data residency, DPA depth, incident response, the table-stakes layer that gets you to a contract conversation but rarely wins one.
We won on the combination of points 1 through 4. Detection quality came out competitive in the structured testing, latency was provable at scale, and the iteration loop during the RFP itself demonstrated what the partnership would feel like in production.
See moderation in action. Take a guided tour of Stream's moderation dashboard and detection capabilities. Watch the demo
How do you actually test a content moderation system at scale?
During the RFP process, two tests were run:
- A primary benchmark set of approximately 3 million chat messages and usernames covering all relevant harm topics, all supported languages, and all severity bands. The benchmark was structured to mirror real production distribution, not a synthetic balanced corpus.
- A targeted "known failure" set of approximately 1,500 lines across 15 languages, content where their incumbent system was known to misclassify or mis-filter. This set existed explicitly to surface where vendors performed better than the baseline, not just where they matched it.
That second set matters. A migration evaluation that only measures parity with the incumbent gives you a worse version of the system you already have. The known-failure set is how you find improvement.
Evaluation ran on three parallel tracks:
-
Quantitative analysis measured per-language, per-topic, per-severity match rates against the baseline. False negatives (violating content allowed through) and false positives (non-violating content filtered) were tracked separately at the language level, which is important because aggregate accuracy can mask the fact that a model can be excellent at English and 30 points worse at Turkish.
-
Qualitative review put the publisher's trust and safety specialists in the loop on every disagreement between vendor and baseline. The point was not to mechanically agree with the incumbent. The point was for human language experts to judge whether the filtering outcome was appropriate from a safety and player-experience perspective. The incumbent was a baseline, not ground truth.
-
Performance measurement ran latency benchmarks on every test run, not as a separate phase. Latency under load is not something you measure once at the end.
Where our model under-performed in the first pass, we ran focused iteration cycles with our linguist team. The two-day rounds we ran during the RFP produced these gains:
- Latin Hindi (Hindi written in Roman script): detection from 0.1% to 85% in a single day, by training the language ID layer on a script it had not previously been exposed to at production scale.
- Arabic classification precision: +30.9% (from 59.2% to 77.5%).
- Turkish: +16.2% (from 53.6% to 62.3%).
- Russian: +13.1% (from 59.4% to 67.2%).
- Chinese, Japanese, Korean: averaging +7% after two-hour sprints per language.
- Overall language detection accuracy: from 75.3% to an expected 80.3% on production traffic.
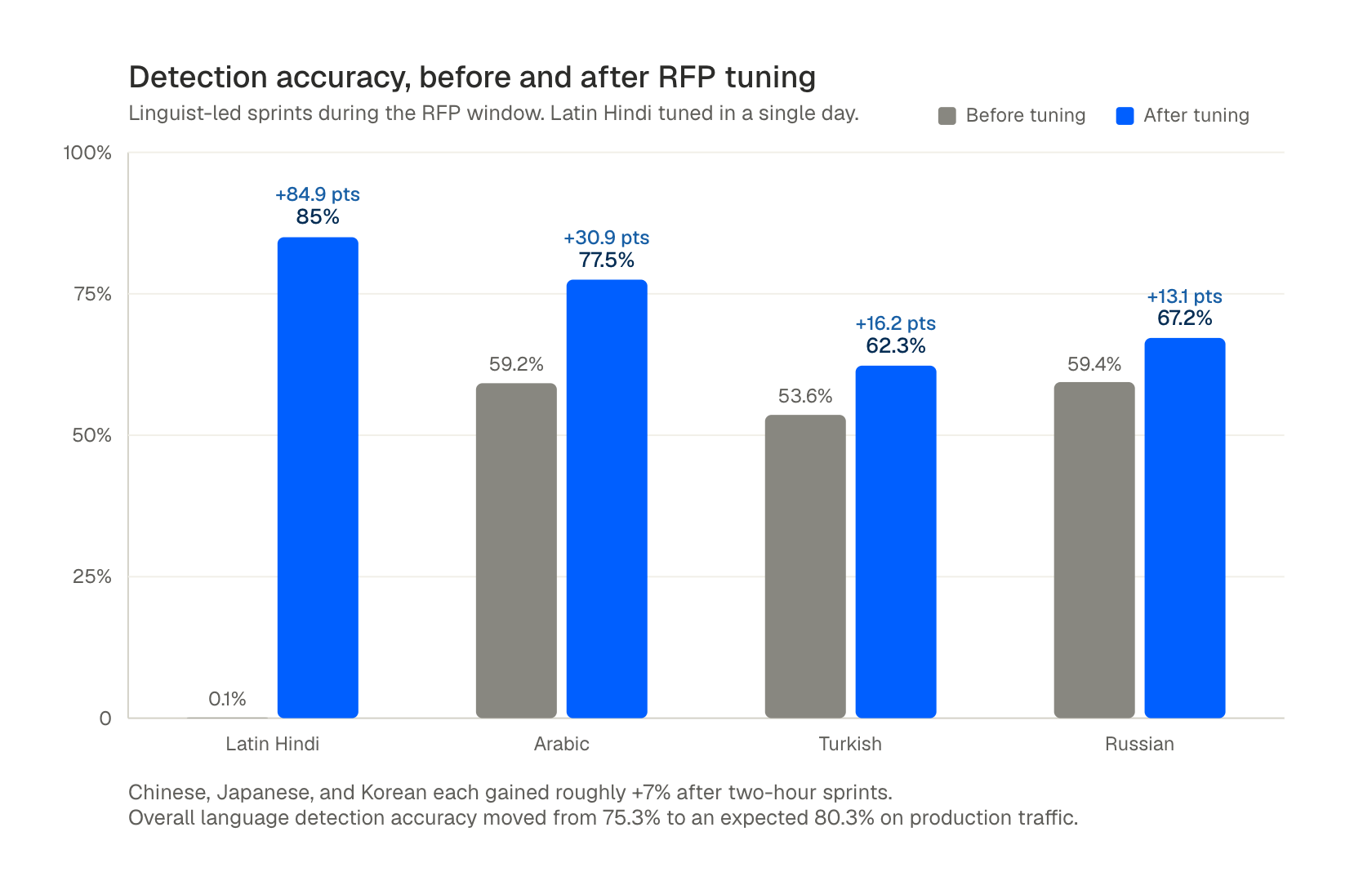
What the iteration loop demonstrated was not the absolute numbers, which keep moving, but the speed. The publisher had been told by other vendors that this kind of tuning takes weeks. We ran multiple rounds during the RFP window.
Infrastructure Needs
In order to support this RFP process, we quickly spun up a dedicated US shard in 48 hours so that they could run their benchmarks from a Databricks i3.4xlarge instance with HTTP keep-alive properly configured (default Python SDK behavior was the original bottleneck, not the moderation API itself).
The results from the dedicated US shard, sustained over a one-million-request run at 4,000 RPS:
- p50: 37.6ms
- p90: 167.4ms
- p95: 186.9ms
- p99: 237.1ms
- 0 errors across 1,000,000 requests
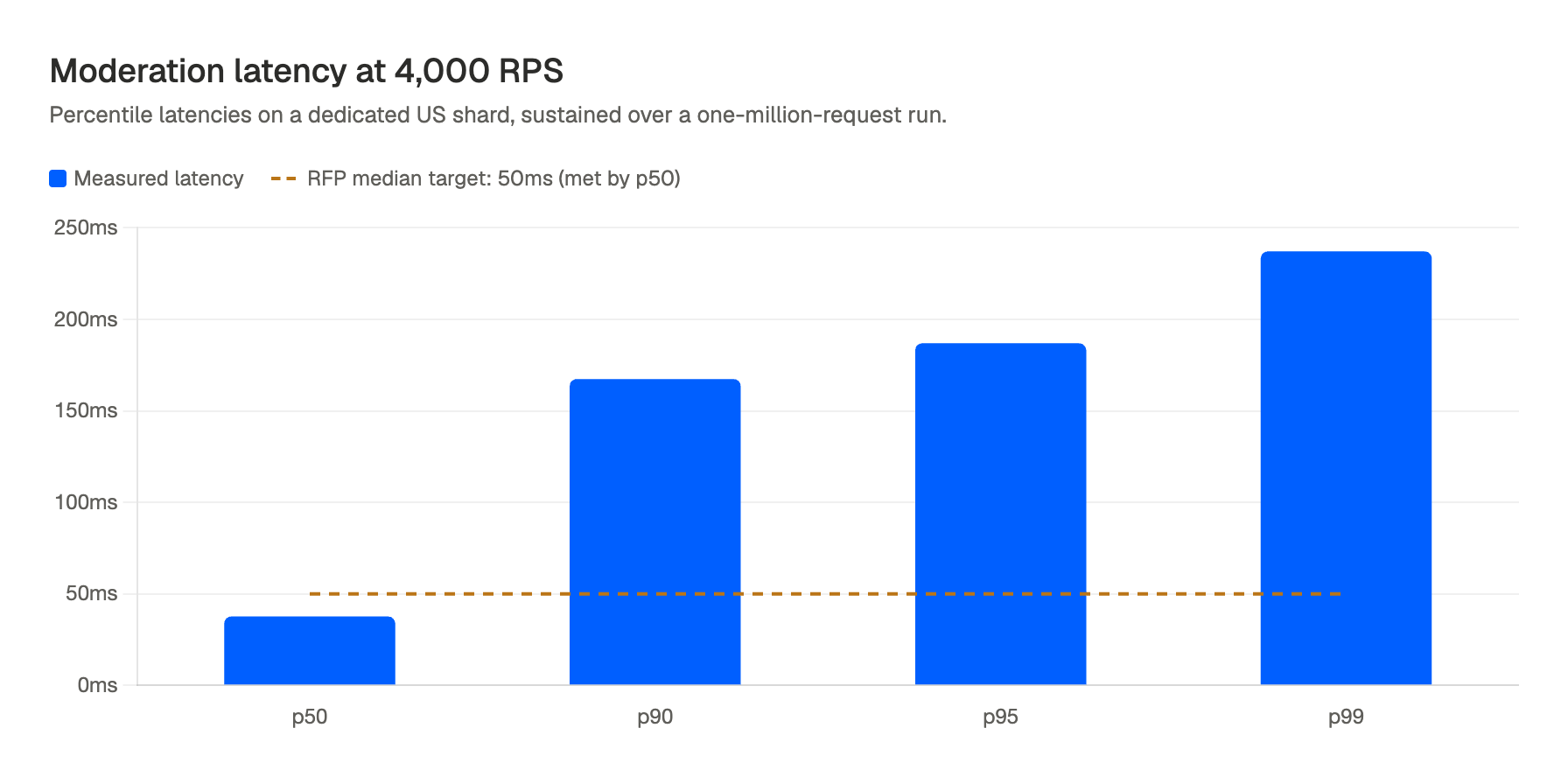
At the lower 1,000 RPS sanity-check load, p99 sat at 51ms. Latency degrades predictably under load, which is what you want, no cliff, no error rate spike, no 429s.
The publisher's RFP target was 50ms median latency for chat moderation. The dedicated shards cleared it. Translation caching (which was disabled for the initial benchmark) brought the average down further on subsequent runs once the most common message patterns were warm.
For teams evaluating moderation vendors: the question to ask is not "what's your typical latency." The question is "can you stand up dedicated infrastructure in our cloud region, and can you prove sustained p99 under our peak load?" The default-shared answer is fine for most workloads. It is not fine at 750M MAU.
What does a content moderation workshop actually look like?
In April 2026, we spent two days on-site at the publisher's office. Twenty-plus moderators across Trust & Safety, Policy & Management, Training, and QA. The goal was straightforward: understand what their team actually does every day, and find every gap in our tooling that would slow them down post-migration.
Day one was shadowing. We watched their existing workflow end-to-end. The weekly report review cadence. Language-aware word and report analysis. How they investigate harmful content and bad actors. How false negatives surface, get triaged, and feed back into policy. How they pull samples to QA the system itself, moderating the moderation.
What we learned in eight hours of shadowing reshaped our roadmap. The biggest single gap: their incumbent system has a live "Moderation Log" view that lets them spot disruptive content that made it past the filter in real time. Our dashboard had no equivalent. That is the primary mechanism their team uses to catch false negatives, content that should have been flagged but was not. Without it, the team would be operationally blind to a category of errors that matters more than any other in player safety.
Day two was hands-on training plus structured feedback capture. We ran the team through our dashboard, our filter configuration UI, and our feedback mechanisms. They tested. They broke things. They told us, with the kind of specificity that only comes from people who do this work every day, what was missing.
We left with roughly 30 product requests, sorted into tiers. The ones we committed to deliver before or shortly after go-live:
- A live moderation log view for false-negative discovery on production traffic.
- A sandbox UI for batch testing up to 1,000 rows of text against filter configuration changes, so they can predict the impact of a policy update before shipping it.
- More granular filter log views: by game, by filter profile, by language.
- Improved feedback capture inside the dashboard, so they can submit issues on test cases (not just live content) without leaving the tool.
- An additional feedback button surface to make it easier to flag specific moderation decisions to our linguist team.
For any vendor running a migration of this shape: the two-day workshop is the highest-ROI activity in the entire deal. It is the only place where you find out what the spec missed.
Moderate every format. Stream's AI detects harmful text, images, video, and audio from a single API. Read the docs
How do you migrate without flying blind? Shadow testing on production traffic
Shadow testing, running the new system in parallel with the incumbent on live production traffic, logging every decision, and comparing is the only safe way to migrate a moderation operation of this scale.
The methodology the publisher ran:
- Start with the lowest-traffic title in the portfolio. A smaller game means a smaller blast radius if something is miscalibrated, and fewer messages means tighter feedback loops on tuning.
- Route 100% of live messages through both systems. Every chat message and every username, scored by both the incumbent and Stream's stack. No production user-facing impact, only the incumbent's decision is enforced, but every Stream decision is logged.
- Use an LLM-as-judge to classify every disagreement between the two systems. The judge produces a recommended action (block / allow) with reasoning, surfacing the disagreement set for human review.
- T&S team validates a sample of the disagreement set across 15 languages (en, ar, zh, fi, fr, de, id, it, ja, ko, pt, ru, es, tr, pl) and produces the actual ground-truth label.
- Feed validated disagreements back into linguist-led fine-tuning, rerun the shadow test, and iterate until the disagreement curve flattens.
Storage architecture matters here. Shadow testing generates enormous volumes of decision data, every score, every category, every model output, for every message and username. We built the logging pipeline on daily partitioning with S3 backup and a 7-day retention window. Enough to catch the false-negative tail, not so much that compliance becomes a problem.
The first round of shadow analysis surfaced an honest finding worth saying out loud: Stream's stack tends to over-block compared to the incumbent, concentrated in PII and sexual content categories. That is not a flaw to hide. It is a calibration point. Over-blocking is recoverable through threshold tuning and policy refinement. Under-blocking, letting actual harm through, is much harder to claw back, both technically and in player trust. We would rather start tight and tune toward the publisher's tolerance than start loose and chase missed content.
The second iteration of shadow testing is where the workshop's product gaps stop being abstract. The live moderation log we committed to building is what makes shadow testing -> fine-tuning -> re-test work as a continuous loop instead of a one-time exercise.
What this migration taught us
Five takeaways, for any trust & safety leader running this play in 2026:
- The incumbent is a baseline, not ground truth. A migration evaluation that measures only parity gives you a worse version of what you already have. Build a known-failure set on day one.
- Test methodology matters more than headline accuracy numbers. A 3-million-message benchmark with an LLM judge and human validation across 15 languages is a different evaluation than a 10,000-message demo with a vendor-supplied test set. Run the harder version.
- Dedicated infrastructure is not optional at scale. If your traffic is concentrated in a region, your moderation API should run there. Ask vendors for regional shard timelines in the RFP.
- The T&S workshop is the highest-ROI activity in the deal. Two days on-site with the operators surfaced thirty product gaps that a written spec would never have caught. Budget for it before vendor selection, not after.
- Shadow testing is the only safe migration methodology at this scale. Start with the smallest title, run both systems in parallel, classify disagreements with a judge, validate with humans, iterate, expand. Anything faster is a player-safety risk.
If you are running a migration off Community Sift, or evaluating any AI moderation vendor at gaming scale, we would be glad to share more detail on any section of this, the testing scripts, the shadow-testing pipeline, workshop format. Get in touch with the Stream Moderation team.