


Your room looks like it's been hit by El Niño, but you have a presentation in five minutes. Do you Marie Kondo it, or flip on a virtual background and pretend you're calling from a 1920s Parisian cafe?
Background removal is a standard feature now. Zoom, Google Meet, and Teams all ship it. If you're building a video product, you either get it from the SDK or add it yourself.
The "add it yourself" path usually means a browser-side segmentation model running in the user's tab - small enough to ship to every client, which means the cleaned video only exists in the local preview. Recordings and downstream consumers don't see it.
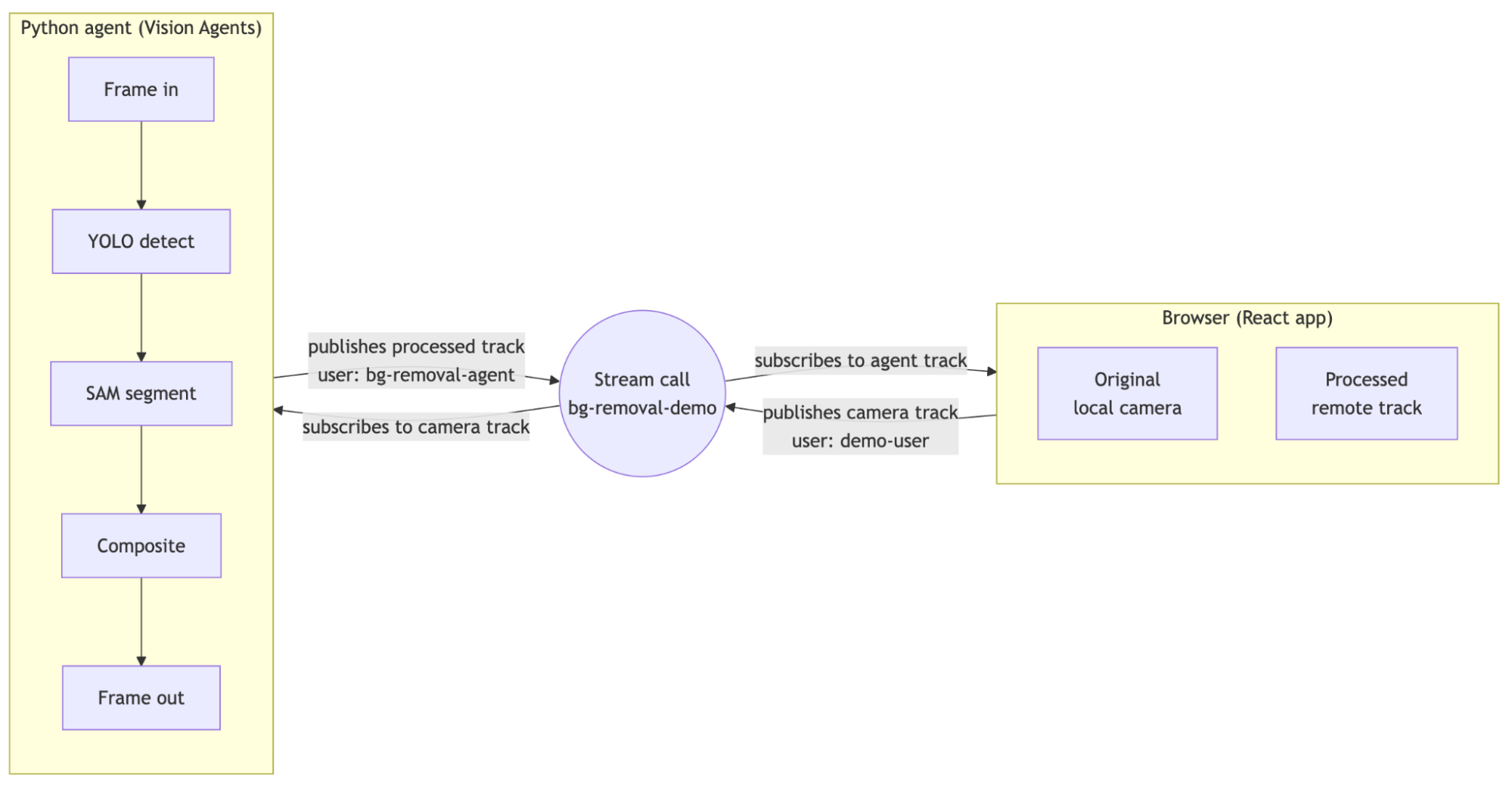
Vision Agents and Stream Video remove that requirement. An agent joins a Stream call as a participant, subscribes to the tracks it cares about, processes each frame, and publishes the result back. We'll use that pattern to build a real-time background removal tool with SAM 2 and YOLO11n, running on a CPU.
What We're Building
A demo that shows two video tiles side by side: your raw camera feed, and you on a flat green background (or any image you point it at). Both come from the same Stream call. You can change the background color via an environment variable and restart the agent to see the change take effect.
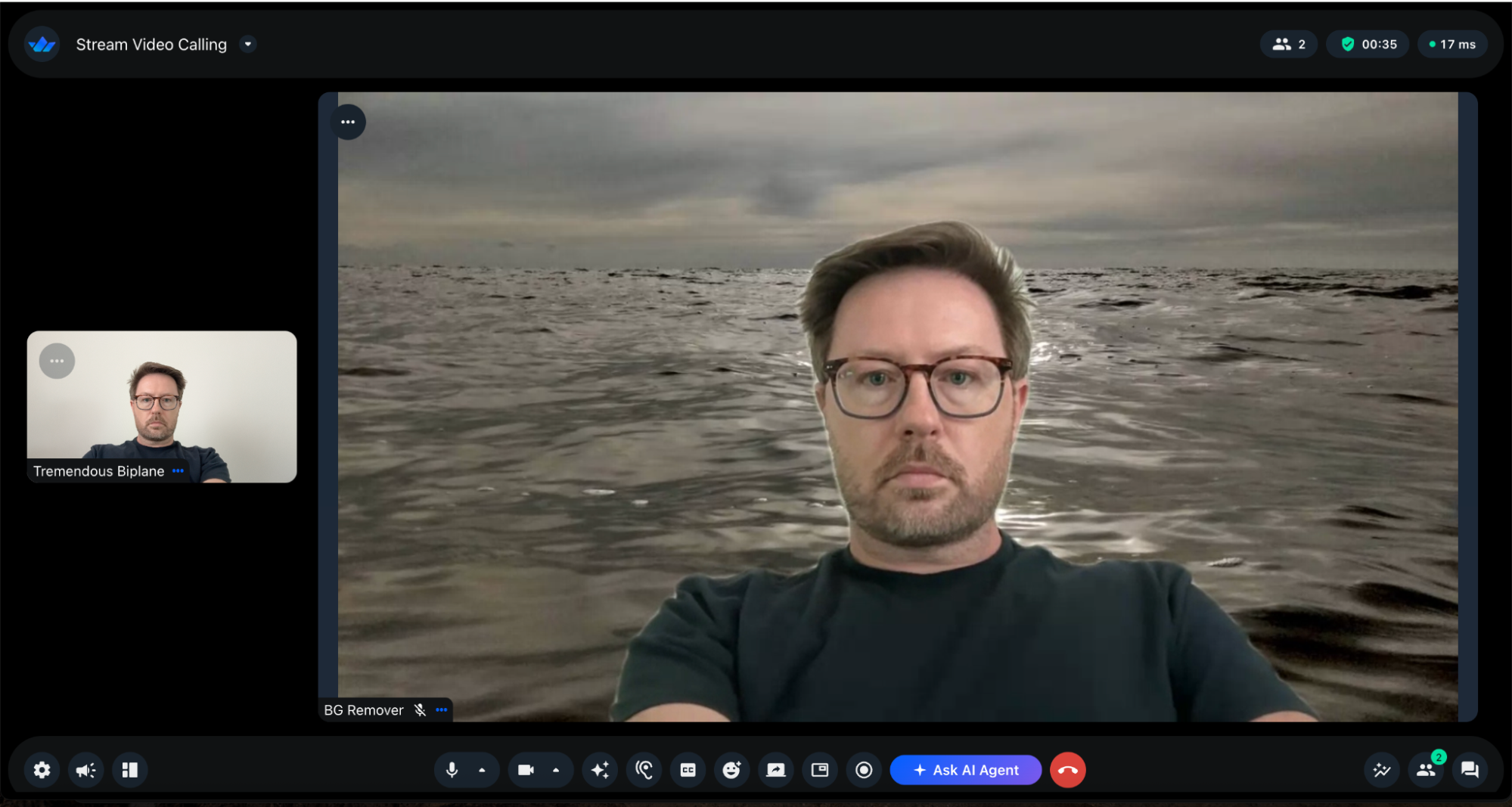
Underneath, a Python agent joins that call, subscribes to your camera track, runs each frame through YOLO11n for person detection and SAM 2 for segmentation, alpha-composites the result onto a replacement background, and publishes the processed video back to the call as its own track. The browser renders that track next to the raw one.
Setting Up Segment Anything and Vision Agents
The conceptual move that makes this whole thing workable is that the agent participates in the call the same way you do. It uses Stream's server SDK via Vision Agents to join the room, subscribe to a video track, and publish its own video track. From the call's perspective, it's another user.
You could run a separate processing server that the browser sends frames to over WebSocket, but then you've signed up for transport, codec handling, backpressure, and reconnect logic. You could run everything in the browser with WebGL or WebAssembly, but you're back to the constraints from the intro. The participant pattern keeps everything within a single transport that already handles the hard parts.
Here's the stack:
- Vision Agents provides the Agent class, the VideoProcessorPublisher base, and the VideoForwarder plumbing that hands you frames at a target FPS
- Stream Video handles WebRTC transport on the server side and gives us the React SDK for the viewer
- YOLO11n from Ultralytics runs person detection in around 2ms per frame and produces bounding boxes
- SAM 2 tiny from Ultralytics turns those bounding boxes into precise segmentation masks
- OpenCV and NumPy handle mask cleanup and alpha compositing
Vision Agents wraps the Stream server SDK, provides the processor base class we'll extend, and handles the video-forwarder plumbing that passes frames to your code at the target FPS. It's pip-installable with extras for the integrations you need. We use two:
1234567dependencies = [ "vision-agents[getstream,ultralytics]", "python-dotenv>=1.0", "opencv-python>=4.8.0", "numpy>=1.24.0", "onnxruntime>=1.24,<1.26", ]
- The
getstreamextra pulls in the Stream Video server SDK and theEdgeclass that the agent uses to join calls. - The
ultralyticsextra adds the Ultralytics package, which is the unified Python API for both YOLO and SAM 2. - The
onnxruntimepin matters because the underlying inference goes through ONNX, and the Ultralytics version we want is tied to that range.
The model weights for SAM 2 tiny and YOLO11n download automatically from Ultralytics the first time you reference them. There's no separate setup step. The defaults (SAM_MODEL=sam2_t.pt, YOLO_MODEL=yolo11n.pt) point at the smallest variant of each model:
- YOLO11n is about 6MB and runs in 2-3ms per frame on CPU
- SAM 2 tiny is about 40MB and takes 50-80ms per call on CPU
If you have a GPU available, swap sam2_t.pt for sam2_b.pt (base) or sam2_l.pt (large) for sharper masks.
Stream credentials come from the dashboard at dashboard.getstream.io. Create an app if you don't have one, open its overview page, and copy the API key and secret into .env:
12STREAM_API_KEY=your_api_key STREAM_API_SECRET=your_api_secret
The rest of the environment variables control how the agent runs:
123456SAM_MODEL=sam2_t.pt YOLO_MODEL=yolo11n.pt PROCESSING_FPS=10 IMGSZ=256 BG_MODE=color BG_COLOR=#00B041
SAM_MODELandYOLO_MODELpick the model variants we covered above.PROCESSING_FPSis how often the agent runs the pipeline per second, since the camera publishes faster than CPU inference can keep up.IMGSZis the input resolution YOLO uses for detection (lower values mean faster detection but a higher chance of missed detections).BG_MODEtoggles between a solid color and a background image, andBG_COLORis the hex value used whenBG_MODE=color. The default is the standard chroma-key green, which gives you a clean key in post if you ever want to composite the output against something else. We'll get to what each setting does in more detail as it comes up.
The project has a Python half and a JavaScript half:
1234567agent.py # Vision Agents entrypoint processor.py # SAM 2 + YOLO pipeline pyproject.toml # uv deps src/App.tsx # React viewer server/index.ts # Express token server package.json # Node deps + dev scripts .env # Stream credentials, model config
The agent runs in one terminal. The token server and the Vite dev server run together in another.
The Stream Token Server
The browser can't generate Stream user tokens directly because that would require shipping the API secret to every client (and shipping API secrets is AI's job). So we can build a small Express service as a token server that holds the secret and mints user-scoped tokens on request:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849// server/index.ts import express from "express"; import cors from "cors"; import { StreamClient } from "@stream-io/node-sdk"; const app = express(); app.use(cors()); app.use(express.json()); const apiKey = process.env.STREAM_API_KEY; const apiSecret = process.env.STREAM_API_SECRET; if (!apiKey || !apiSecret) { console.error( "Missing STREAM_API_KEY or STREAM_API_SECRET environment variables.\n" + "Copy .env.example to .env and fill in your Stream credentials." ); process.exit(1); } const serverClient = new StreamClient(apiKey, apiSecret); app.post("/auth/token", async (req, res) => { const { userId } = req.body; if (!userId || typeof userId !== "string") { res.status(400).json({ error: "userId is required" }); return; } try { await serverClient.upsertUsers([{ id: userId }]); const token = serverClient.generateUserToken({ user_id: userId, validity_in_seconds: 24 * 60 * 60, }); res.json({ token, apiKey }); } catch (err) { console.error("Token generation failed:", err); res.status(500).json({ error: "Failed to generate token" }); } }); const PORT = process.env.PORT || 3001; app.listen(PORT, () => { console.log(`Token server running on http://localhost:${PORT}`); });
upsertUsers makes sure the user record exists before we mint a token for them. Otherwise, the user wouldn't be known to Stream, and the token would fail validation when the browser tries to join the call. In production, you'd want to put auth in front of this endpoint so only your authenticated users can request tokens.
The React Frontend Video Viewer
Our App.tsx is all we need for the viewer. It handles getting a token from the Express server, joining the Stream call, rendering the raw camera and the agent's processed feed side by side, and tearing everything down cleanly when the user leaves.
Fetching the Token
The browser can't generate a Stream user token (the API secret lives on the server), so it asks the Express service we covered earlier:
12345678910111213async function fetchToken( userId: string ): Promise<{ token: string; apiKey: string }> { const res = await fetch(`${SERVER_URL}/auth/token`, { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ userId }), }); if (!res.ok) { throw new Error(`Token request failed: ${res.status}`); } return res.json(); }
The response carries both the token and the API key, which the StreamVideoClient needs to connect.
The Raw Camera Tile
LocalVideo calls navigator.mediaDevices.getUserMedia() and pipes the result into a plain <video> element. It deliberately stays outside the Stream SDK so the "Original" side keeps working even when the agent hasn't joined yet, or when you've stopped the agent to iterate on the processor. The raw preview also has zero round-trip latency, since the pixels never leave the browser.
123456789101112131415161718192021222324252627function LocalVideo() { const videoRef = useRef<HTMLVideoElement>(null); const streamRef = useRef<MediaStream | null>(null); const initCamera = useCallback(async () => { const stream = await navigator.mediaDevices.getUserMedia({ video: true }); streamRef.current = stream; if (videoRef.current) videoRef.current.srcObject = stream; }, []); useEffect(() => { initCamera(); return () => { streamRef.current?.getTracks().forEach((t) => t.stop()); }; }, [initCamera]); return ( <video ref={videoRef} autoPlay playsInline muted style={{ /* ... */ transform: "scaleX(-1)" }} /> ); }
ProcessedVideo watches the call's remote participants and looks for one with the agent's user ID:
123456789101112131415161718192021function ProcessedVideo() { const { useRemoteParticipants } = useCallStateHooks(); const remoteParticipants = useRemoteParticipants(); const agentParticipant = remoteParticipants.find( (p) => p.userId === "bg-removal-agent" ); if (!agentParticipant) { return <Placeholder />; // shows the agent run command } return ( <ParticipantView participant={agentParticipant} mirror={true} muteAudio={true} ParticipantViewUI={null} /> ); }
That's the "agent as remote participant" pattern. The browser doesn't need to know there's a Python process on the other end of the call. It renders whoever has the matching user ID, and the Stream SDK subscribes to the track and pushes frames into a <video> element under the hood.
ParticipantViewUI={null} tells the SDK not to render its default overlays (name badge, audio indicator) so the video tile stays clean. If the agent hasn't joined yet, the placeholder renders the exact command needed to start it, with the configured call ID interpolated so the reader can copy and paste without thinking.
The App Component
App ties everything together: it requests a token, builds a StreamVideoClient, joins the call, and renders the UI inside the Stream providers.
1234567891011121314151617181920212223242526272829303132333435useEffect(() => { let cancelled = false; async function init() { try { const { token, apiKey } = await fetchToken(USER_ID); if (cancelled) return; const videoClient = new StreamVideoClient({ apiKey, token, user: { id: USER_ID }, }); const videoCall = videoClient.call("default", CALL_ID); await videoCall.join({ create: true }); await videoCall.camera.enable(); await videoCall.microphone.disable(); if (cancelled) { videoCall.leave().catch(console.error); videoClient.disconnectUser().catch(console.error); return; } setClient(videoClient); setCall(videoCall); } catch (err) { if (!cancelled) setError(/* ... */); } } init(); return () => { cancelled = true; }; }, []);
create: true makes the call if it doesn't exist yet. Both the viewer and the agent use this flag, so whoever joins first creates the call, and whoever joins second walks into the existing one.
A second useEffect handles teardown when the user navigates away:
123456useEffect(() => { return () => { if (call) call.leave().catch(console.error); if (client) client.disconnectUser().catch(console.error); }; }, [client, call]);
Leaving the call releases the camera and the WebRTC connection; disconnecting the user closes the Stream WebSocket.
Once the client and call are ready, the component renders the UI under three Stream providers:
123456789return ( <StreamVideo client={client}> <StreamTheme> <StreamCall call={call}> <CallUI /> </StreamCall> </StreamTheme> </StreamVideo> );
StreamVideo puts the client in React context, StreamTheme applies Stream's default video styles (overridable via CSS variables), and StreamCall puts the active call in context. Hence, hooks like useCallStateHooks work inside child components. Before that's ready, the component shows a "Connecting..." message. If the token request fails, it shows an error with a hint about the token server and where to get Stream credentials.
The Python Agent Entrypoint
agent.py is the file you run to start the agent. It reads config from .env, builds a processor, wraps the processor in an Agent, and exposes a CLI that joins a call and keeps processing until the call ends.
A No-Op LLM
Vision Agents is designed around the idea that most agents have a language model somewhere in the loop, since most of what people want agents to do involves understanding speech or text. Background removal doesn't, so we stub the LLM with a class that does nothing:
12345class NoOpLLM(LLM): async def simple_response( self, text: str, participant=None ) -> LLMResponseEvent: return LLMResponseEvent(text="")
This is a useful pattern beyond this specific demo. Anytime you want a processor-only agent (transcoding, watermarking, transcription that ships to a database without speaking back), a NoOpLLM keeps the construction tidy without forcing you to wire up an API key you'll never call.
Building the Agent
create_agent reads every setting out of the environment, applies the defaults we covered in the configuration section, and uses the values to instantiate a BackgroundRemovalProcessor:
1234567891011121314151617181920async def create_agent(**kwargs) -> Agent: sam_model = os.environ.get("SAM_MODEL", "sam2_t.pt") yolo_model = os.environ.get("YOLO_MODEL", "yolo11n.pt") fps = int(os.environ.get("PROCESSING_FPS", "10")) imgsz = int(os.environ.get("IMGSZ", "256")) bg_mode = os.environ.get("BG_MODE", "color") bg_color_hex = os.environ.get("BG_COLOR", "#00B041") bg_image_path = os.environ.get("BG_IMAGE", "") or None bg_color = hex_to_rgb(bg_color_hex) processor = BackgroundRemovalProcessor( sam_model_path=sam_model, yolo_model_path=yolo_model, fps=fps, imgsz=imgsz, bg_color=bg_color, bg_image_path=bg_image_path if bg_mode == "image" else None, ) ...
Two small details worth flagging.
- The
os.environ.get("BG_IMAGE", "") or Noneline falls back toNoneif the variable is unset or set to an empty string, since the processor expectsNonerather than""when no background image is configured. - The
bg_image_path if bg_mode == "image" else Noneternary at the bottom means the path only gets passed through whenBG_MODEisimage, which keeps the two background modes from interfering with each other.
With the processor built, the function returns an Agent out of four pieces:
123456return Agent( edge=getstream.Edge(), llm=NoOpLLM(), agent_user=User(name="BG Remover", id="bg-removal-agent"), processors=[processor], )
Edgeis the Stream transport, the same one a regular Stream server SDK call would use under the hood.agent_useris the identity the agent appears as on the call, with the ID matching what the React side filters on.processorsis where the actual work plugs in: a list because an agent can run several processors against the same incoming track if you want it to (a noise suppressor and a background removal pass, for example).
Joining the Call
join_call joins the call and waits for it to end:
1234async def join_call(agent, call_type, call_id, **kwargs): call = await agent.create_call(call_type, call_id) async with agent.join(call): await agent.finish()
The async with agent.join(call): context manager handles the lifecycle: it joins the call, runs the processors, and leaves the call cleanly when the block exits. agent.finish() blocks until the call ends, so the agent process remains alive for as long as the call.
Finally, we wire up create_agent and join_call to a Vision Agents launcher:
12if __name__ == "__main__": Runner(AgentLauncher(create_agent=create_agent, join_call=join_call)).cli()
That gives you uv run python agent.py run --call-type default --call-id bg-removal-demo for free, along with help text and other CLI niceties from Vision Agents.
The Processor
This is where the actual work happens. BackgroundRemovalProcessor extends VideoProcessorPublisher, Vision Agents' base class for processors that both consume and publish video tracks.
We're going to start by looking at the imports and class declaration. This might be a little 101, but there is a lot here that will show what we're going to do with the processor:
123456789101112131415import asyncio import logging from concurrent.futures import ThreadPoolExecutor import av import cv2 import numpy as np from typing import Optional from vision_agents.core.processors.base_processor import VideoProcessorPublisher from vision_agents.core.utils.video_track import QueuedVideoTrack from vision_agents.core.utils.video_forwarder import VideoForwarder from ultralytics import SAM, YOLO class BackgroundRemovalProcessor(VideoProcessorPublisher): name = "background_removal"
av is PyAV, the Python binding for FFmpeg. Vision Agents uses this for video frames. Every frame we touch is an av.VideoFrame. The Vision Agents imports give us the base class and two utilities: QueuedVideoTrack for the output side and VideoForwarder for the input side. The name class attribute identifies the processor in Vision Agents' internal registry and in log output.
YOLO and SAM are our models. Because inference is blocking CPU operations, if we ran them directly inside the async frame handler, the asyncio event loop would stall, causing the Stream connection's heartbeats and ICE updates to back up and the call to degrade. We push every per-frame call onto a ThreadPoolExecutor so the loop stays responsive.
BackgroundRemovalProcessor has a constructor that takes the agent's config and sets up state for everything the processor will need:
123456789101112131415161718192021222324252627282930def __init__( self, sam_model_path: str = "sam2_t.pt", yolo_model_path: str = "yolo11n.pt", fps: int = 10, imgsz: int = 256, bg_color: tuple[int, int, int] = (0, 176, 65), bg_image_path: Optional[str] = None, device: str = "cpu", ): # Config self._sam_model_path = sam_model_path self._yolo_model_path = yolo_model_path self._fps = fps self._imgsz = imgsz self._bg_color = bg_color self._bg_image_path = bg_image_path self._device = device # State self._sam: Optional[SAM] = None self._yolo: Optional[YOLO] = None self._bg_image: Optional[np.ndarray] = None self._forwarder: Optional[VideoForwarder] = None self._video_track = QueuedVideoTrack() self._shutdown = False self._last_mask: Optional[np.ndarray] = None self.executor = ThreadPoolExecutor( max_workers=2, thread_name_prefix="bg_removal" )
Most of this is straightforward. The models (_sam, _yolo, _bg_image) start as None, so we can load them lazily on the first frame rather than blocking the constructor. And _video_track = QueuedVideoTrack() is the output track that publish_video_track will hand back to Vision Agents. The agent's outbound video comes from frames we push onto this queue.
To load the models, _load_models runs once on the first video frame:
12345678910def _load_models(self): self._yolo = YOLO(self._yolo_model_path) self._yolo.to(self._device) self._sam = SAM(self._sam_model_path) if self._bg_image_path: img = cv2.imread(self._bg_image_path) if img is not None: self._bg_image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
The Ultralytics constructors download model weights on first use, so the very first call here can take 10-20 seconds. After that, the cached weights load in a second or two. The .to(self._device) call moves YOLO to the target device (CPU here, but the same call works for "cuda" if you have a GPU).
The Frame Stream
process_video runs once when a participant's video track becomes available:
123456789101112131415161718192021222324252627async def process_video( self, incoming_track, participant_id: Optional[str] = None, shared_forwarder: Optional[VideoForwarder] = None, ): if self._sam is None: self._load_models() if self._forwarder is not None: await self._forwarder.remove_frame_handler(self._process_frame) self._forwarder = ( shared_forwarder if shared_forwarder else VideoForwarder( incoming_track, max_buffer=self._fps, fps=self._fps, name="bg_removal_forwarder", ) ) self._forwarder.add_frame_handler( self._process_frame, fps=float(self._fps), name="background_removal", )
- First, we lazy-load the models if we haven't already.
- Second, if a forwarder is already attached (which can happen when a participant rejoins the call after a brief drop), we remove the old handler before wiring up the new one.
- Third, we either use the
shared_forwarderVision Agents hands us (which happens when multiple processors run against the same track) or create our ownVideoForwarderthat pulls frames off the incoming track and dispatches them at our configured FPS.
We default to 10 FPS for processing, even though the camera publishes at 30. Doing person segmentation 30 times per second on a CPU is asking too much: SAM tiny takes around 50-80ms per call on a modern laptop, and even with the cascade we'll describe below, you'd quickly fall behind. At 10 FPS, the budget per frame is 100ms, which fits comfortably and still looks natural for a video call. If we fall behind on processing, VideoForwarder drops older frames instead of letting the queue grow unbounded. That's the right behavior for real-time work, since a stale processed frame is worse than a slightly skipped one.
_process_frame is the handler the forwarder calls. It's the boundary between the async event loop and the CPU-bound work:
12345678910111213async def _process_frame(self, frame: av.VideoFrame): if self._shutdown: return try: loop = asyncio.get_running_loop() new_frame = await loop.run_in_executor( self.executor, self._process_frame_sync, frame ) await self._video_track.add_frame(new_frame) except Exception: logger.exception("Frame processing failed") await self._video_track.add_frame(frame)
The async wrapper hands the frame off to the thread pool, awaits the processed result, and pushes it onto the output QueuedVideoTrack. That queued track is what becomes the agent's outbound video, the one the React side renders as the "Background Removed" tile.
_process_frame_sync runs in the thread pool. It converts the frame to a NumPy array, runs the pipeline, and converts back:
123456789def _process_frame_sync(self, frame: av.VideoFrame) -> av.VideoFrame: img = frame.to_ndarray(format="rgb24") h, w = img.shape[:2] mask = self._segment_person(img, h, w) self._last_mask = mask output = self._apply_background(img, mask, h, w) return av.VideoFrame.from_ndarray(output, format="rgb24")
After processing, we wrap the result back up as an av.VideoFrame so the rest of Vision Agents can route it. The _last_mask assignment feeds the cache we'll use in _build_mask when a frame's segmentation fails.
Detect, Then Segment
Each frame goes through three steps:
- Detect the person
- Segment within that detection
- Composite the segmented person onto the replacement background
The detect-then-segment architecture is an important design decision. SAM 2 is a powerful segmentation model, but it's a prompted one. You give it a hint about what you want segmented (a bounding box, one or more clicked points, or a text prompt with the right model variant), and it returns a precise mask within that hint.
123456789101112131415161718192021222324def _segment_person(self, img, h, w): yolo_results = self._yolo( img, classes=[0], imgsz=self._imgsz, verbose=False ) boxes = [] if yolo_results and len(yolo_results) > 0: result = yolo_results[0] if result.boxes is not None and len(result.boxes) > 0: boxes = result.boxes.xyxy.cpu().numpy().tolist() if boxes: sam_results = self._sam( img, bboxes=boxes, device=self._device, verbose=False ) else: # Fallback: center-column point prompts points = [[w // 2, h // 3], [w // 2, h // 2], [w // 2, 2*h // 3]] labels = [1, 1, 1] sam_results = self._sam( img, points=points, labels=labels, device=self._device, verbose=False, ) return self._build_mask(sam_results, h, w)
classes=[0] tells YOLO to only return person detections. result.boxes.xyxy.cpu().numpy().tolist() pulls the bounding boxes off the GPU/tensor representation into a plain Python list, since SAM's input API wants a list rather than a tensor.
The fallback path matters. YOLO occasionally misses a frame, especially if the subject is partially out of frame, turning sharply, or briefly occluded. Without the fallback, SAM would get called with no prompts and return nothing, which would blank the subject for a frame and make the output look strobed. With three-point prompts down the center column, we still get a usable mask in the common case where the person is roughly centered (which is almost always true for a video call). The label value of 1 tells SAM these points are foreground hints rather than background ones.
Cleaning the Mask
Raw SAM output is binary and slightly ragged at the edges. Compositing that directly produces a stamped-on look with visible jaggies along the silhouette. _build_mask cleans it up in two passes:
1234567891011121314151617181920212223242526272829303132def _build_mask(self, results, h, w): combined = np.zeros((h, w), dtype=np.float32) if not results or len(results) == 0: if self._last_mask is not None: return self._last_mask return combined for result in results: if result.masks is None or len(result.masks) == 0: continue masks_data = result.masks.data.cpu().numpy() for mask in masks_data: if mask.shape != (h, w): mask = cv2.resize( mask.astype(np.float32), (w, h), interpolation=cv2.INTER_LINEAR, ) combined = np.maximum(combined, mask.astype(np.float32)) if combined.max() == 0: if self._last_mask is not None: return self._last_mask return combined combined = (np.clip(combined, 0, 1) * 255).astype(np.uint8) kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5)) combined = cv2.morphologyEx(combined, cv2.MORPH_CLOSE, kernel) combined = cv2.GaussianBlur(combined, (7, 7), 2) return combined.astype(np.float32) / 255.0
The first half merges whatever SAM returned. SAM can return multiple results (one per prompt), and each result can contain multiple mask predictions, so we walk the structure and combine them using np.maximum. The two if self._last_mask is not None branches are the last-good-mask cache: if a frame comes back with nothing usable, we reuse the previous mask. The cache gets overwritten on the next successful segmentation, so a stale mask never lasts long enough to be visible.
The second half cleans up the merged mask. Morphological close fills small holes (hair gaps, glasses frames, the space between an arm and a torso). The Gaussian blur softens the edge into a gradient, so the alpha composite produces a smooth transition instead of a hard cutout. We scale to 0-255 before both operations because OpenCV expects integer pixel values, then back to 0-1 for compositing.
Compositing
The composite itself is a one-liner with NumPy:
12345678910111213def _apply_background(self, img, mask, h, w): alpha = np.stack([mask] * 3, axis=-1) if self._bg_image is not None: bg = cv2.resize(self._bg_image, (w, h)) else: bg = np.full((h, w, 3), self._bg_color, dtype=np.uint8) output = ( img.astype(np.float32) * alpha + bg.astype(np.float32) * (1.0 - alpha) ) return output.astype(np.uint8)
Each pixel of the output is the foreground weighted by the mask plus the background weighted by its complement. The mask gets stacked across three channels, so the math broadcasts cleanly across RGB. The background is either a resized image or a solid color that matches the frame dimensions, depending on the configuration.
Publishing the Track and Cleanup
The remaining methods handle the connection to Vision Agents' track plumbing and the lifecycle of the processor:
123456789101112def publish_video_track(self): return self._video_track async def stop_processing(self): if self._forwarder is not None: await self._forwarder.remove_frame_handler(self._process_frame) self._forwarder = None async def close(self): self._shutdown = True await self.stop_processing() self.executor.shutdown(wait=False)
publish_video_trackreturns theQueuedVideoTrackwe set up in__init__. Vision Agents calls this to find out where the processor's output goes, and routes that track back into the Stream call as the agent's published video.stop_processingruns when a participant's track goes away (they leave the call, drop, or stop sharing video). It removes our frame handler from the forwarder, so we no longer receive frames for that participant.closeruns on agent shutdown. It flips the_shutdownflag so_process_framereturns early on any frames still in flight, then tears down the forwarder and the thread pool. Thewait=Falseon the executor means we don't block shutdown waiting for in-flight frames to finish. Those get abandoned, which is fine for video processing, where individual frame loss has no consequence.
Running Our Demo
We can get this up and running in five steps:
uv syncto install the Python depsnpm installto install the Node deps- Copy
.env.exampleto.envand fill in your Stream credentials npm run devto start the token server and the Vite dev server togetheruv run python agent.py run --call-type default --call-id bg-removal-demoin a second terminal
Open http://localhost:5173, grant camera access, and you should see your raw feed on the left and yourself on a green background on the right.
The first run downloads two models from Ultralytics, about 6MB for YOLO11n and around 40MB for SAM 2 tiny, so the agent takes 10-20 seconds to come online. Subsequent runs use the cached weights and start in a couple of seconds. If you change the background color or any other setting in .env, restart the agent for it to pick up the new value, since the config is read once at startup.
Beyond Background Removal
Anything you'd want to do per-frame - blur, virtual try-on, gesture recognition, real-time captions - fits the same shape: a Vision Agents processor that subscribes to a participant's track, runs whatever per-frame code you want, and publishes a transformed track back to the call. Stream Video handles the transport on both ends, so the only code that changes between use cases is the transformation itself.
The Vision Agents docs cover the rest of the processor API, the LLM integrations we skipped here, and the audio side of the framework. Most of the more interesting agents in the wild use both: a video pipeline for what they see, a language model for what they say.
If you're building real-time video features, the Stream Video and Vision Agents pairing handles most of the infrastructure for you. Swap the models in the processor, change the composite, and you've got a working agent for whatever pipeline you want next.