

Not long ago, text-to-speech (TTS) was a laughing stock. Robotic, obviously synthetic output that made customer service jokes write themselves and relegated TTS to accessibility contexts where users had no alternative.
Now, you may have listened to text-to-speech today without even realizing. AI-generated podcasts, automated customer service calls, voice assistants that actually sound like assistants. The gap between synthetic and human speech has narrowed to the point where they aren’t even in the uncanny valley: distinguishing them requires active effort.
This shift matters because TTS has become the last-mile interface between software and humans in contexts where audio is faster, safer, or more accessible than reading. For developers building voice assistants, accessibility tools, AI agents, or any application where users need to hear rather than read, understanding how modern TTS systems work is a necessity.
This article goes under the hood to explain how neural TTS pipelines are structured, what architectural choices drive quality and latency trade-offs, and how to deploy TTS in production systems.
What is Text-to-Speech?
Text-to-speech (TTS), also called speech synthesis, converts written text into spoken audio. It's the inverse of speech-to-text (STT) and a core component of any voice interface.

Why TTS Matters Now
TTS serves three distinct categories of applications, each with different requirements.
- Accessibility. Screen readers convert on-screen text into speech and support navigation patterns (headings, links, image alternatives) that make digital content usable for people with visual impairments. The W3C maintains standards for how TTS should integrate with web accessibility requirements.
- Real-time voice experiences. Assistants, agents, games, and IVR systems depend on low-latency speech output and fine control over pronunciation and prosody. These applications often use SSML (Speech Synthesis Markup Language) to control pauses, rate, pitch, and pronunciation.
- AI agents. Modern agent architectures position streaming TTS as a building block for real-time conversational experiences. The requirement here is bidirectional streaming: sending text while receiving audio simultaneously to minimize perceived latency.
What changed isn't just quality. Two thresholds were crossed simultaneously: synthesis became good enough that users accepted it as a default interface (not just a fallback), and fast enough that real-time conversation became possible. Add LLMs that can actually hold a conversation, and suddenly, voice interfaces are useful in ways they weren't five years ago.
For developers, this means TTS is no longer something you bolt on at the end. It's infrastructure that shapes product decisions: how you chunk LLM output, how you handle interruptions, what latency budgets you can hit, and whether your app works offline.
How TTS Works
Most practical TTS systems follow a two-stage pipeline: a frontend that transforms text into a linguistic representation, and a backend that transforms that representation into audio.

Frontend: Making Text Speakable
The frontend is where raw text becomes something a speech model can handle reliably. This stage involves several transformations.
Text normalization converts non-standard written forms into their spoken equivalents. Numbers become words, abbreviations expand, and symbols translate to speech:
"$12.50" → "twelve dollars and fifty cents"
"Jan. 24th" → "January twenty-fourth"
"Dr. Smith" → "Doctor Smith"
"3:30 PM" → "three thirty PM"The normalization step is invisible when you're using a TTS API. You pass in raw text with numbers, dates, and abbreviations, and the system handles the conversion internally before synthesis begins.
12345const response = await openai.audio.speech.create({ model: "gpt-4o-mini-tts", voice: "nova", input: "The meeting is scheduled for 12/25/2025 at 3:30 PM.", });
You never see "December twenty-fifth, twenty twenty-five" in your code, but that's what the model actually processes. This works well for common formats, though edge cases (unusual abbreviations, domain-specific notation) sometimes require preprocessing on your end.
Tokenization and segmentation break text into sentences, phrases, and words while handling punctuation and formatting. This matters for prosody: a period triggers falling intonation, a question mark triggers rising intonation, and commas create brief pauses.
Grapheme-to-phoneme (G2P) conversion maps letters to speech sounds. English makes this particularly challenging because spelling and pronunciation often diverge:
"hello" → /h ə l oʊ/ (4 phonemes)
"through" → /θ r uː/ (3 phonemes from 7 letters)
"read" → /r iː d/ (present) or /r ɛ d/ (past)That last example illustrates homograph disambiguation: "read" has two pronunciations depending on context. Neural TTS models learn these contextual mappings from training data, using surrounding words to select the correct pronunciation.
Prosody planning determines the rhythm, stress, and intonation of the output. Prosody is what makes speech sound natural rather than robotic. It encompasses how long each phoneme lasts (duration), the pitch contour over time (intonation), and which syllables receive emphasis (stress).
Modern neural TTS models learn prosody implicitly from data, but higher-quality systems may use explicit prosody features as additional conditioning signals.
Backend: Acoustic Model and Vocoder
The backend takes the frontend's linguistic representation and generates actual audio.
The acoustic model predicts an intermediate representation of speech, typically a mel-spectrogram. A mel-spectrogram is a 2D representation where one axis is time (frames, usually 50-100 per second) and the other is frequency (typically 80 mel-frequency bins). The mel scale approximates human auditory perception: we're more sensitive to differences at lower frequencies than higher ones.

The vocoder converts mel-spectrograms into actual waveform samples. This is where the audio becomes playable. Several vocoder architectures exist, each with different speed/quality tradeoffs:
| Vocoder Type | Examples | Characteristics |
|---|---|---|
| Autoregressive | WaveNet | High quality, very slow (generates sample-by-sample) |
| Flow-based | WaveGlow | Parallel sampling, moderate speed, good quality |
| GAN-based | HiFi-GAN, Parallel WaveGAN | Very fast, high quality, widely deployed |
| Diffusion-based | DiffWave, WaveGrad | Tunable quality/speed via iteration count |
GAN-based vocoders like HiFi-GAN dominate production deployments because they achieve both high quality and speeds exceeding 100x real-time on a GPU. HiFi-GAN also has small-footprint variants that run faster than real time on the CPU, which matters for edge deployment.
Neural TTS Models Explained
When developers discuss "modern neural TTS," they're typically referring to neural architectures for the acoustic model and vocoder. Four architectural approaches dominate the field.
1. Autoregressive Sequence-to-Sequence
The breakthrough architecture was Tacotron 2 (2017), which predicts mel-spectrogram frames step-by-step using attention to align text tokens with audio frames.

The key insight was that attention mechanisms can learn text-to-audio alignment without explicit duration labels. The model figures out which input tokens correspond to which output frames during training.
- Strengths: strong naturalness and prosody, implicit alignment learning.
- Weaknesses: inference is slower because frames are generated sequentially, and attention can fail in edge cases (leading to repeated or skipped words).
2. Non-Autoregressive (Parallel Generation)
FastSpeech (2019) and FastSpeech 2 (2020) took a different approach: predict phoneme durations explicitly, then generate the entire spectrogram in parallel.

Because generation is parallel rather than sequential, FastSpeech achieves large speedups versus autoregressive systems, e.g., the original FastSpeech reports ~270× faster mel generation and ~38× faster end-to-end synthesis in its evaluation setup. They also offer straightforward control over speaking rate by scaling predicted durations.
This matters operationally. When you need to hit real-time latency constraints or want predictable inference times, non-autoregressive models are easier to work with.
3. End-to-End Single-Stage
VITS (2021) combined the acoustic model and vocoder into a single end-to-end model that directly outputs waveforms from text.
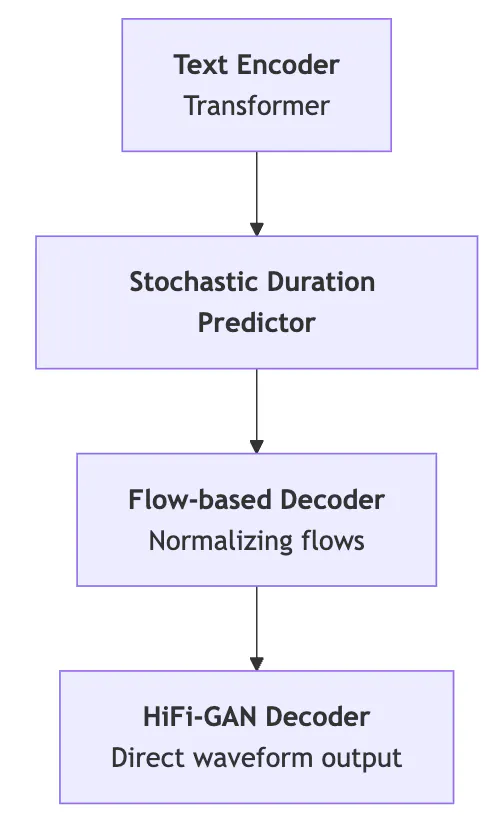
VITS uses a conditional VAE with normalizing flows and adversarial training. The stochastic duration predictor is particularly clever: it models the one-to-many nature of speech (the same text can be spoken many valid ways) rather than predicting a single deterministic duration.
For teams building TTS into products, VITS-style architectures simplify the pipeline. One model, one training process, one inference call. The Coqui TTS library provides VITS models you can run locally:
1234567from TTS.api import TTS tts = TTS(model_name="tts_models/en/ljspeech/vits") tts.tts_to_file( text="Neural text to speech converts text into audio using deep learning.", file_path="output.wav" )
This particular model uses the VITS architecture trained on the LJSpeech dataset, a standard single-speaker English corpus. First run downloads the model weights; subsequent calls use the cached version.
4. Diffusion-Based Acoustic Models
Grad-TTS (2021) and similar models generate mel-spectrograms through iterative denoising, starting from noise and gradually refining toward the target.
The practical benefit is a tunable trade-off between quality and speed. More denoising steps produce higher quality but take longer. Fewer steps are faster but may sacrifice some fidelity. This lets you configure the same model differently for batch processing (more steps, higher quality) versus real-time applications (fewer steps, acceptable quality).
Architecture Comparison
| Architecture | Speed | Quality | Key Characteristic |
|---|---|---|---|
| Autoregressive (Tacotron 2) | Slow | Excellent | Implicit alignment via attention |
| Non-autoregressive (FastSpeech 2) | Fast | Very Good | Explicit duration, parallel generation |
| End-to-end (VITS) | Fast | Excellent | Single model, stochastic variation |
| Diffusion (Grad-TTS) | Configurable | Excellent | Quality/speed tradeoff via steps |
Real-Time vs. Batch TTS
The distinction between real-time and batch TTS is less about model architecture and more about product requirements and systems design.
Real-Time TTS
The goal is responsiveness. Users should feel like they're having a conversation, not waiting for a computer to think.
Two metrics dominate real-time TTS:
- Time-to-first-audio (TTFA) measures how quickly the user hears anything. For conversational applications, TTFA under 200ms feels responsive; under 100ms feels instant.
- Real-time factor (RTF) is synthesis_time divided by audio_duration. RTF \< 1 means the system generates audio faster than it plays back, which is necessary for streaming.
Real-time systems need several capabilities beyond fast synthesis:
- Streaming synthesis means receiving audio chunks while text is still being processed. You don't wait for the entire utterance to synthesize before starting playback.
- Interruptibility (barge-in) means stopping speech immediately when the user starts talking. This requires canceling in-progress synthesis and clearing audio buffers.
- Stable prosody under partial context is the hard part. When streaming LLM output to TTS, you're often speaking before you know how the sentence ends. Systems manage this with sentence-boundary buffering and prosody heuristics.
Human perception thresholds provide useful targets: under 100ms feels instant, 100-300ms feels responsive, 300-500ms is noticeable but acceptable, and over 500ms disrupts conversational flow.
Batch TTS
Batch processing prioritizes throughput, cost efficiency, and long-form coherence over low latency.
Use cases include audiobook generation, video narration, podcast production from scripts, and pre-generated IVR prompts. These applications can tolerate seconds or minutes of processing time because users aren't waiting interactively.
Batch systems typically use HD/high-quality models (since latency doesn't matter), split large documents into segments, run synthesis in parallel to improve throughput, and apply post-processing steps such as audio normalization and crossfades.
TTS APIs typically have character limits per request (4096 for OpenAI), and even without limits, processing long text in chunks improves reliability and lets you implement progress feedback. The challenge is splitting at natural boundaries rather than arbitrary character counts.
1234567891011121314151617181920212223242526272829303132function splitIntoSegments(text: string, maxLength: number = 4000): string[] { const segments: string[] = []; const paragraphs = text.split(/\n\n+/); let currentSegment = ""; for (const paragraph of paragraphs) { if (currentSegment.length + paragraph.length > maxLength && currentSegment.length > 0) { segments.push(currentSegment.trim()); currentSegment = ""; } if (paragraph.length > maxLength) { // Split long paragraphs by sentence const sentences = paragraph.match(/[^.!?]+[.!?]+/g) || [paragraph]; for (const sentence of sentences) { if (currentSegment.length + sentence.length > maxLength && currentSegment.length > 0) { segments.push(currentSegment.trim()); currentSegment = ""; } currentSegment += sentence + " "; } } else { currentSegment += paragraph + "\n\n"; } } if (currentSegment.trim()) { segments.push(currentSegment.trim()); } return segments; }
This function tries paragraphs first, then falls back to sentence-level splits for paragraphs that exceed the limit. Splitting mid-sentence produces awkward prosody at segment boundaries, so sentence boundaries are the minimum viable split point.
TTS in AI Agents and Voice Apps
A practical voice agent loop follows this pattern:

Why Is TTS a Core Building Block for AI Agents?
- Voice is an interface layer for intelligence. Agents need a way to express decisions and explanations naturally. Text output works for chatbots; voice output is required for phone systems, accessibility, hands-free interfaces, and embodied AI.
- Low latency changes interaction patterns. Streaming TTS enables conversational backchannels ("Got it…", "One moment…") and partial responses rather than waiting for complete paragraphs. This makes interactions feel more natural.
- Production apps need control and observability. You need explicit control over pauses, pronunciations, speaking rate, and sometimes timing events (like visemes for avatar animation). SSML provides this control surface.
The key insight is buffering LLM tokens until you hit a sentence boundary, then immediately dispatching that sentence to TTS. You don't wait for the full response, and you don't send partial sentences that would produce unnatural prosody.
123456789101112131415161718192021222324252627282930async function streamLLMToTTS(userMessage: string, ttsQueue: TTSQueue) { const stream = await openai.chat.completions.create({ model: "gpt-4o-mini", messages: [ { role: "system", content: "You are a helpful voice assistant. Keep responses concise." }, { role: "user", content: userMessage } ], stream: true, max_tokens: 150, }); let sentenceBuffer = ""; const sentenceEnders = /[.!?]\s*$/; for await (const chunk of stream) { const token = chunk.choices[0]?.delta?.content || ""; sentenceBuffer += token; // Send complete sentences to TTS immediately if (sentenceEnders.test(sentenceBuffer)) { ttsQueue.push(sentenceBuffer.trim()); sentenceBuffer = ""; } } // Don't forget remaining text if (sentenceBuffer.trim()) { ttsQueue.push(sentenceBuffer.trim()); } }
The regex /[.!?]\s*$/ catches sentence-ending punctuation at the end of the buffer. This is a simplified heuristic; production systems might use more sophisticated sentence boundary detection to handle abbreviations (Dr., Mrs.) and decimal numbers correctly.
The effect on perceived latency is significant. If the LLM generates three sentences and each takes 200ms to synthesize:
- Without streaming: User waits 600ms (all sentences) before hearing anything.
- With streaming: User hears audio after ~200ms (first sentence). Sentences 2-3 synthesize while sentence 1 plays.
Interruption handling requires coordinating two cancellations: stopping the TTS stream so you don't waste synthesis on audio that won't be played, and stopping the audio player so the user isn't talking over the AI.
12345678910111213141516171819202122232425262728class VoiceAgent { private currentStream: TTSStream | null = null; private speaker: AudioPlayer; async speak(text: string) { // Cancel any ongoing speech if (this.currentStream) { this.currentStream.cancel(); this.speaker.stop(); } this.currentStream = await tts.stream(text); this.currentStream.on('chunk', (audio) => { if (this.interrupted) { this.currentStream?.cancel(); return; } this.speaker.play(audio); }); } handleUserSpeechDetected() { this.interrupted = true; this.currentStream?.cancel(); this.speaker.stop(); } }
The handleUserSpeechDetected method would be called by your voice activity detection (VAD) system when it detects the user starting to speak. The interrupted flag prevents queued audio chunks from playing after cancellation.
Voice selection should match the agent's role and personality. A customer support agent benefits from warmth and patience; a technical assistant can be more direct. The voice choice is just one part of persona design, but it's the part users perceive most immediately.
1234567891011121314const personas = { customerSupport: { voice: "nova", // Female, friendly systemPrompt: "You are a helpful customer support agent. Be patient and professional." }, technicalExpert: { voice: "onyx", // Male, deep systemPrompt: "You are a senior technical expert. Be precise and direct." }, wellnessCoach: { voice: "shimmer", // Female, warm systemPrompt: "You are a wellness coach. Use a calming tone and gentle advice." } };
These OpenAI voice names map to specific speaker identities, but the pattern applies to any TTS provider. The system prompt and voice should reinforce the same character rather than creating dissonance (a wellness coach with an aggressive speaking style, for instance).
For frequently repeated phrases, caching avoids redundant API calls and reduces synthesis latency. Agent greetings, confirmation phrases, and error messages are good candidates. The tradeoff is memory usage, so capping cache eligibility by text length keeps it bounded.
123456789101112131415161718const phraseCache = new Map<string, Buffer>(); async function synthesizeWithCache(text: string): Promise<Buffer> { const normalized = text.toLowerCase().trim(); if (phraseCache.has(normalized)) { return phraseCache.get(normalized)!; } const audio = await tts.synthesize(text); // Cache short, common phrases if (text.length < 100) { phraseCache.set(normalized, audio); } return audio; }
Normalization (lowercase, trim) ensures that "Hello!" and "hello!" hit the same cache entry. In production, you'd likely add cache expiration, size limits, and possibly persistence across restarts for high-value phrases.
SSML for Pronunciation and Prosody Control
Speech Synthesis Markup Language (SSML) is an XML-based markup language that enables developers to fine-tune TTS output. Most production TTS APIs support SSML or a subset of it.
SSML is valuable when default synthesis doesn't produce the desired output. Common scenarios include proper nouns and brand names that are mispronounced, acronyms that should be spelled out rather than spoken as words, technical terms with domain-specific pronunciations, and deliberate prosodic effects (pauses, emphasis, rate changes).
Pronunciation control with <phoneme> specifies exact pronunciation using IPA (International Phonetic Alphabet) or other phonetic systems:
1234<speak> Welcome to <phoneme alphabet="ipa" ph="təˈmɑːtoʊ">tomato</phoneme> farm. <!-- Forces American pronunciation --> </speak>
Pauses with <break> insert silence of specified duration:
12345<speak> Please hold. <break time="500ms"/> Your call is important to us. <break time="1s"/> A representative will be with you shortly. </speak>
Rate, pitch, and volume with <prosody> modify speaking characteristics:
12345678<speak> <prosody rate="slow" pitch="-10%"> This is important information. Please listen carefully. </prosody> <prosody rate="fast" volume="loud"> Act now! Limited time offer! </prosody> </speak>
Spelling out with \<say-as> controls interpretation of numbers, dates, and abbreviations:
12345<speak> Your confirmation code is <say-as interpret-as="characters">ABC123</say-as>. The price is <say-as interpret-as="currency">$19.99</say-as>. Call us at <say-as interpret-as="telephone">1-800-555-1234</say-as>. </speak>
Here's a complete example for an IVR greeting:
123456789101112131415<speak> <prosody rate="95%"> Thank you for calling Acme Corporation. <break time="300ms"/> For sales, press <say-as interpret-as="cardinal">1</say-as>. <break time="200ms"/> For support, press <say-as interpret-as="cardinal">2</say-as>. <break time="200ms"/> For billing, press <say-as interpret-as="cardinal">3</say-as>. <break time="500ms"/> To repeat these options, press <say-as interpret-as="cardinal">9</say-as>. </prosody> </speak>
SSML support varies by provider. OpenAI's TTS API doesn't support SSML markup directly. Google Cloud TTS and Amazon Polly have comprehensive SSML support.
Deployment Patterns
Three deployment models exist, each with distinct tradeoffs.
Cloud API
Cloud APIs offer the fastest path to production. A few lines of code give you access to high-quality voices without managing models, GPUs, or scaling infrastructure.
12345678// OpenAI TTS - minimal setup const response = await openai.audio.speech.create({ model: "gpt-4o-mini-tts", voice: "nova", input: text, response_format: "mp3", }); const buffer = Buffer.from(await response.arrayBuffer());
The response returns an ArrayBuffer containing encoded audio. From here, you can stream it to a client, save it to disk, or pipe it to an audio player. The tradeoff is that every request incurs network latency and API costs.
- Advantages: high-quality voices, global scaling, continuous improvements without code changes, and no infrastructure to manage.
- Disadvantages: latency includes network round-trips; usage-based costs can grow significantly; data leaves your infrastructure (privacy/compliance implications); dependent on third-party availability.
Self-Hosted / On-Premises
Self-hosting gives you predictable latency and keeps data within your infrastructure. Open-source libraries make this accessible without building models from scratch.
1234567from TTS.api import TTS # Load a VITS model tts = TTS(model_name="tts_models/en/ljspeech/vits", gpu=True) # Synthesize tts.tts_to_file(text="Self-hosted TTS gives you control.", file_path="output.wav")
The gpu=True flag enables CUDA acceleration if available. Without it, inference runs on CPU, which is slower but still viable for low-throughput applications. You're responsible for model updates, scaling, and monitoring, while avoiding per-request costs and external dependencies.
- Advantages: predictable latency (no network variability), data stays within your infrastructure, can fine-tune or customize voices, and fixed infrastructure cost regardless of volume.
- Disadvantages: you own model optimization, scaling, monitoring, and updates. Requires ML infrastructure expertise. Initial setup is more complex.
On-Device / Edge
Running TTS directly on user devices eliminates network latency. Edge TTS requires aggressive model optimization, including quantization, pruning, and architecture choices that favor small models (e.g., small VITS variants or specialized edge vocoders).
- Advantages: works offline, lowest possible end-to-end latency, complete privacy (no data transmitted), no per-request costs.
- Disadvantages: constrained compute and memory budgets, model size must fit on the device, quality may be lower than that of cloud models, and deployment across device variants is complex.
In practice, engineering concerns often matter more than which neural architecture you choose:
- Chunking and segmentation. Split text at sentence or phrase boundaries to maintain prosody stability. Arbitrary sentence splits can cause awkward pauses or unnatural intonation.
- Audio encoding. PCM is simple but large. MP3 is broadly compatible. Opus provides excellent quality-to-size ratio and is preferred for streaming over networks.
- Model optimization. Quantization (INT8, FP16) reduces model size and speeds inference. Batching multiple requests improves GPU utilization. CPU-optimized vocoders matter for edge deployment.
- Observability. Track TTFA, RTF, error rates, and quality metrics. Monitoring for quality regressions is particularly important, whether due to model updates (cloud APIs) or shifts in input distribution (your text patterns changing).
The Future of TTS
Several trends are reshaping what TTS systems can do and how developers will use them.
More Expressive and Controllable Speech
Current TTS models are improving at capturing the one-to-many nature of speech: the same text can be spoken in many valid ways. Better models allow control over emotion, emphasis, and pacing without requiring separate training runs.
Style control is becoming more intuitive. Some systems accept reference audio ("speak like this clip"), while others accept natural language descriptions ("speak with excitement"). Diffusion and flow-based methods enable explicit quality-latency tradeoffs, letting the same model serve both real-time and batch use cases with different configurations.
Speech-Native AI Systems
Agent experiences are pushing toward deeper integration between language models and speech. Current architectures are "text-first": the LLM generates text, then TTS converts it to speech. Future architectures may be "speech-native," in which the model directly outputs speech tokens or waveforms without an intermediate text representation.
This matters because text-first pipelines lose information. The LLM can't express "say this word with emphasis" or "pause here for effect" except through explicit markup. Speech-native models could make these decisions implicitly, the way humans do.
Efficiency and Scalability
Research is explicitly targeting scalability and efficiency improvements. Work on architectures like SupertonicTTS to improve frame efficiency as a first-class research goal rather than an afterthought. Expect smaller models that match current quality levels, faster inference on commodity hardware, and better support for on-device deployment.
Safety, Provenance, and Consent
As voice quality improves, the risks of voice cloning and misuse increase. A high-quality TTS system can generate convincing audio of anyone given a few seconds of reference audio. This creates real risks: fraud, misinformation, harassment.
Expect more emphasis on consent-based voice creation (proving you have permission to clone a voice), provenance and watermarking (detecting synthetic audio), and product-side disclosure and policy enforcement.
For developers, this means building with these concerns in mind. Even if your use case is legitimate, consider how your systems might be misused and what safeguards are appropriate.
FAQs
- What's the difference between TTS models like tts-1 and tts-1-hd?
Standard models (tts-1) prioritize speed and lower latency, making them suitable for real-time applications. HD models (tts-1-hd) use more compute to produce higher-fidelity audio, better for batch processing where latency doesn't matter. The quality difference is audible but not dramatic; choose based on your latency requirements.
- Can I clone a specific voice?
Yes, with caveats. Services like ElevenLabs and Coqui XTTS support voice cloning from short audio samples. Quality varies with sample quality and length. The legal and ethical landscape is evolving: most providers require consent verification, and using cloned voices for deception or impersonation violates terms of service and potentially laws depending on jurisdiction.
- What's the minimum latency I can achieve?
Cloud APIs typically deliver 100-300ms time-to-first-audio depending on text length and network conditions. Self-hosted GPU models can hit 50-100ms. On-device inference eliminates network latency but requires model optimization to fit device constraints. For conversational AI, aim for under 200ms TTFA to feel responsive.
- Do I need SSML?
Not always. Modern neural TTS handles most text well by default, including numbers, dates, and common abbreviations. SSML becomes necessary when you need precise control: specific pronunciations for proper nouns, deliberate pauses for pacing, or explicit handling of ambiguous formats. Start without it, and add SSML when default synthesis doesn't meet your needs.
TTS is Now AI Infrastructure
TTS has evolved from an accessibility feature into core infrastructure for voice interfaces, AI agents, and real-time applications. Understanding how modern neural TTS works, from frontend text processing through acoustic models and vocoders, helps you make informed decisions about architecture, deployment, and tradeoffs.
The key takeaways for developers:
- Latency matters differently for different use cases. Real-time applications need streaming and sub-200ms TTFA. Batch applications can prioritize quality.
- The pipeline has multiple optimization points. Frontend, acoustic model, vocoder, encoding, and network all contribute to total latency and quality.
- Integration patterns matter. Streaming LLM output to TTS sentence-by-sentence dramatically reduces perceived latency compared to waiting for complete responses.
- Control surfaces like SSML exist for a reason. When default synthesis isn't right, explicit pronunciation and prosody control solve problems that model improvements can't.
- Deployment choice affects more than cost. Cloud, self-hosted, and edge deployments have different latency profiles, privacy implications, and operational requirements.
TTS is no longer about whether machines can speak. It's about how AI systems should sound now that they do.