

There are two ways to build conversational voice agents for enterprise and production use cases. Developers can use a real-time API or speech-to-speech (STS), that takes audio input from a user and sends it to a large language model (LLM) to return a voice output. Or they can use a turn-based architecture, which consists of a speech-to-text (STT) → LLM → text-to-speech (TTS) pipeline.
For each of these architectures, there are several APIs you can use to create a voice agent or service. The following sections will focus on real-time (STS) platforms and discuss the top five APIs developers can use to make AI-powered audio and video applications.
Build Voice Agents: Choose the Right Architecture and Models
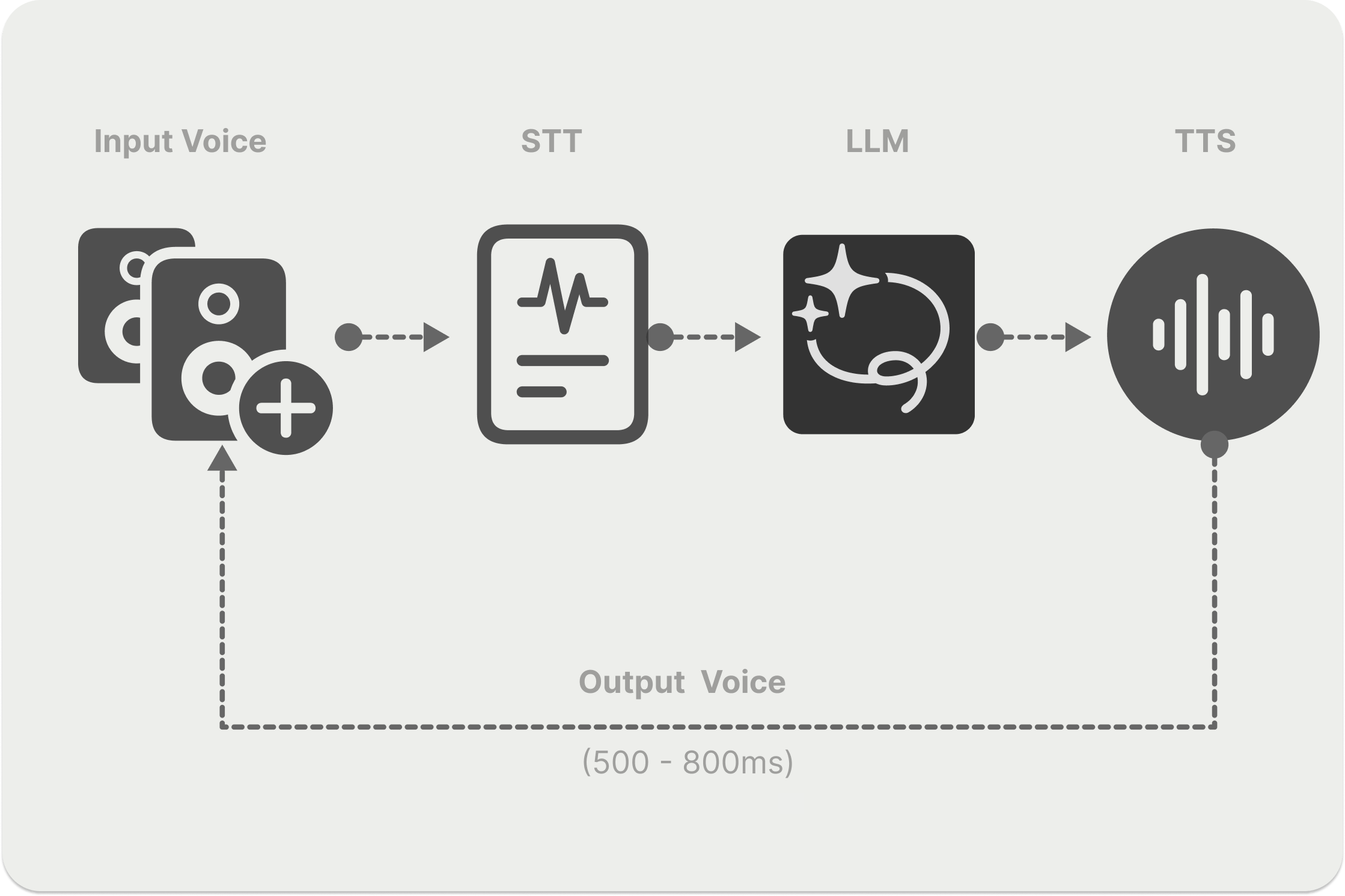
Real-time voice and turn-based architectures are commonly used to assemble voice agents. Both technologies allow developers to achieve low-latency user-AI interactions. However, several factors, such as the system's responsiveness, handling mid-utterances, and taking turns, should be considered when choosing which one to use for your voice AI project.
As the diagram above shows, the STT/ TTS pipeline consists of different AI models for transcribing and converting text to an output voice that a user can hear. Since it uses a sequential pipeline (Voice → STT → LLM → TTS → Voice) and has several speech conversion components, the architecture can result in high latency.
Although there are many ways to reduce latency in such a system, achieving an optimal latency can also hinder the voice system's performance. Also, it can cause loss of information during transcription for languages that are hard to transcribe by LLMs.
For these reasons, the real-time (Voice → LLM → Voice) option is often the better choice. It enables fully integrated audio streaming for building voice AI apps and works well with the speech APIs we’ll cover next. The STS system also has a simpler architecture and code structure.
When building AI applications or prototyping with a voice-to-voice project, you can use the following open-source and commercial/closed TTS and STT models from leading AI service providers:
- Qwen3-TTS: Text-to-speech model from Alibaba Cloud.
- ElevenLabs: Realistic voice AI platform.
- Deepgram: Voice AI APIs for developers.
- Cartesia: Ultra-realistic voice AI platform.
- Hume AI: Realistic voice AI in real-time.
- Pipecat: Open-source, real-time voice AI platform.
- Ultravox: Human-like Voice AI built for scale.
- Gladia: State-of-the-art speech-to-text API provider.
- Rime: Voice AI models for customer experience.
- Speechmatics: Enterprise-grade speech-to-text APIs.
- PlayAI: Realtime voice intelligence.
- Silero: TTS & STT models.
- Inworld TTS: State-of-the-art voice AI.
- LMNT: Next-level AI text-to-speech.
- Moonshine: Advanced speech recognition with Whisper-level accuracy.
- Kyutai: STT & TTS for developers.
Voice-to-Voice AI: Audio Streaming Mechanisms
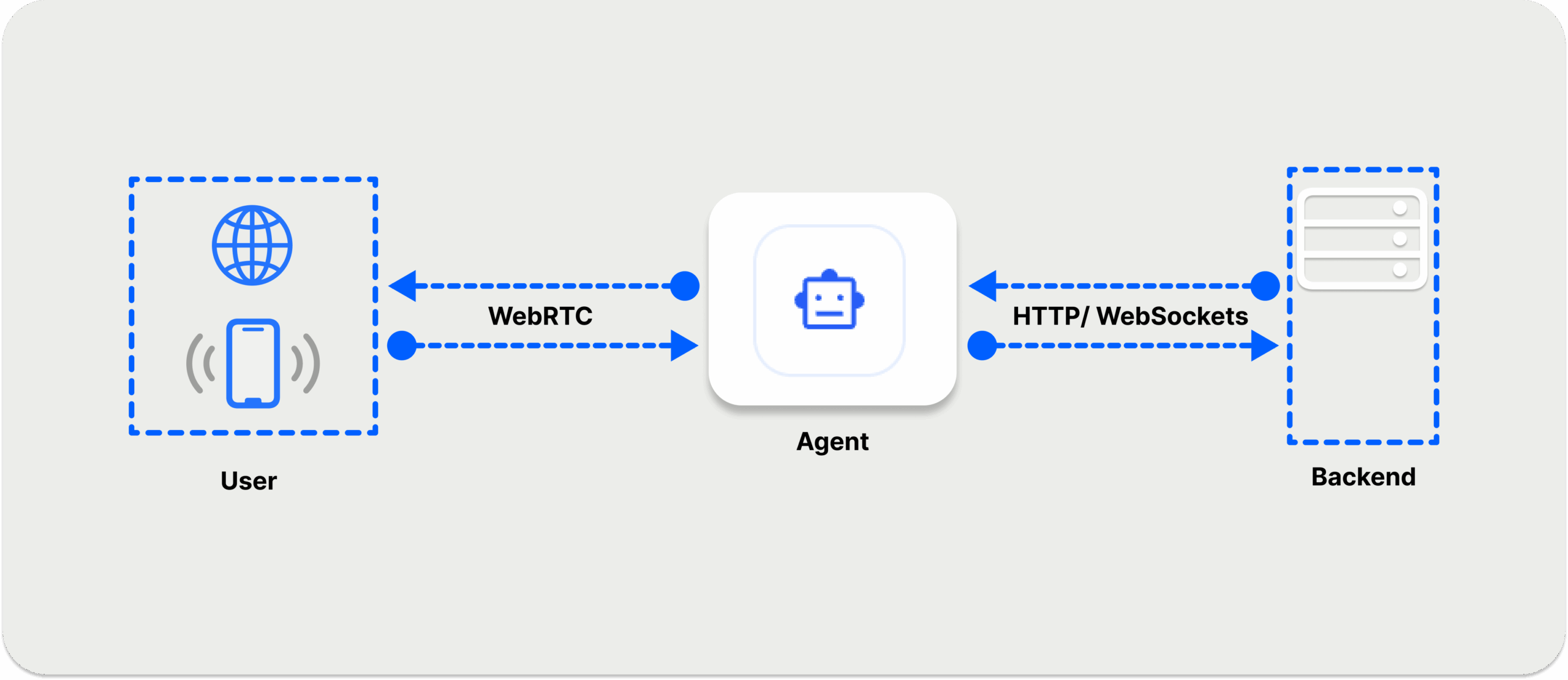
One critical aspect of building a voice agent is the transport layer, which establishes a reliable user-agent speech-to-speech connection, depending on the type of service you want to create.
Today's production and enterprise agents use WebRTC, WebSockets, or Session Initiation Protocol (SIP) connections. All can be used to achieve low-latency conversational voice AI experiences. WebRTC is an excellent choice for circumstances with poor network conditions and has several benefits over WebSockets.
For a typical voice agent interaction, WebRTC can be used for the front end to establish a seamless connection between the user and agent, while HTTP/ WebSockets can be used for the backend. For the pros and cons of each technology, check out our post WebRTC vs WebSockets.
Here’s a summary of how each voice connection method is used:
- SIP Connection: This protocol can be used to build voice agents with telephony support, allowing users to make direct phone calls through your app.
- WebSockets: WebSockets are excellent for server-side apps and services prototyping. However, WebRTC is preferred for real-time audio and video.
- WebRTC: This protocol is great for client-side and web browser-based enterprise and production voice service interactions.
Speech-to-Speech Communication: Architecture Overview
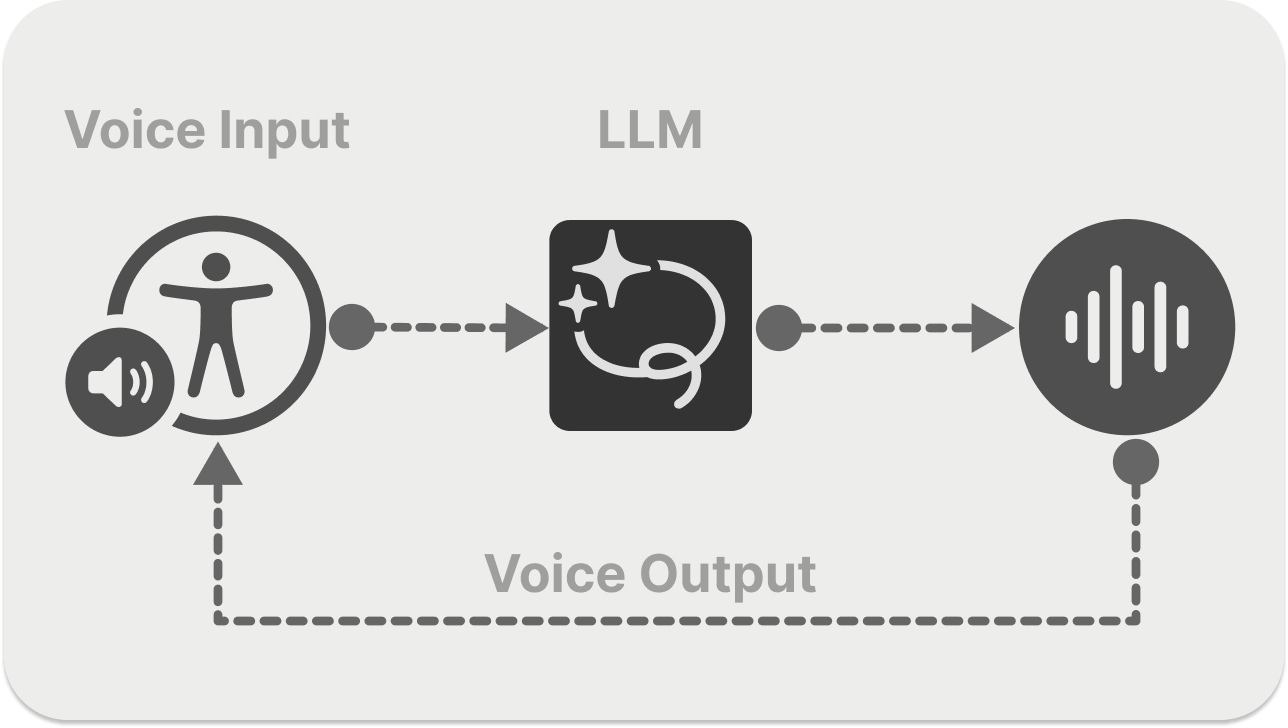
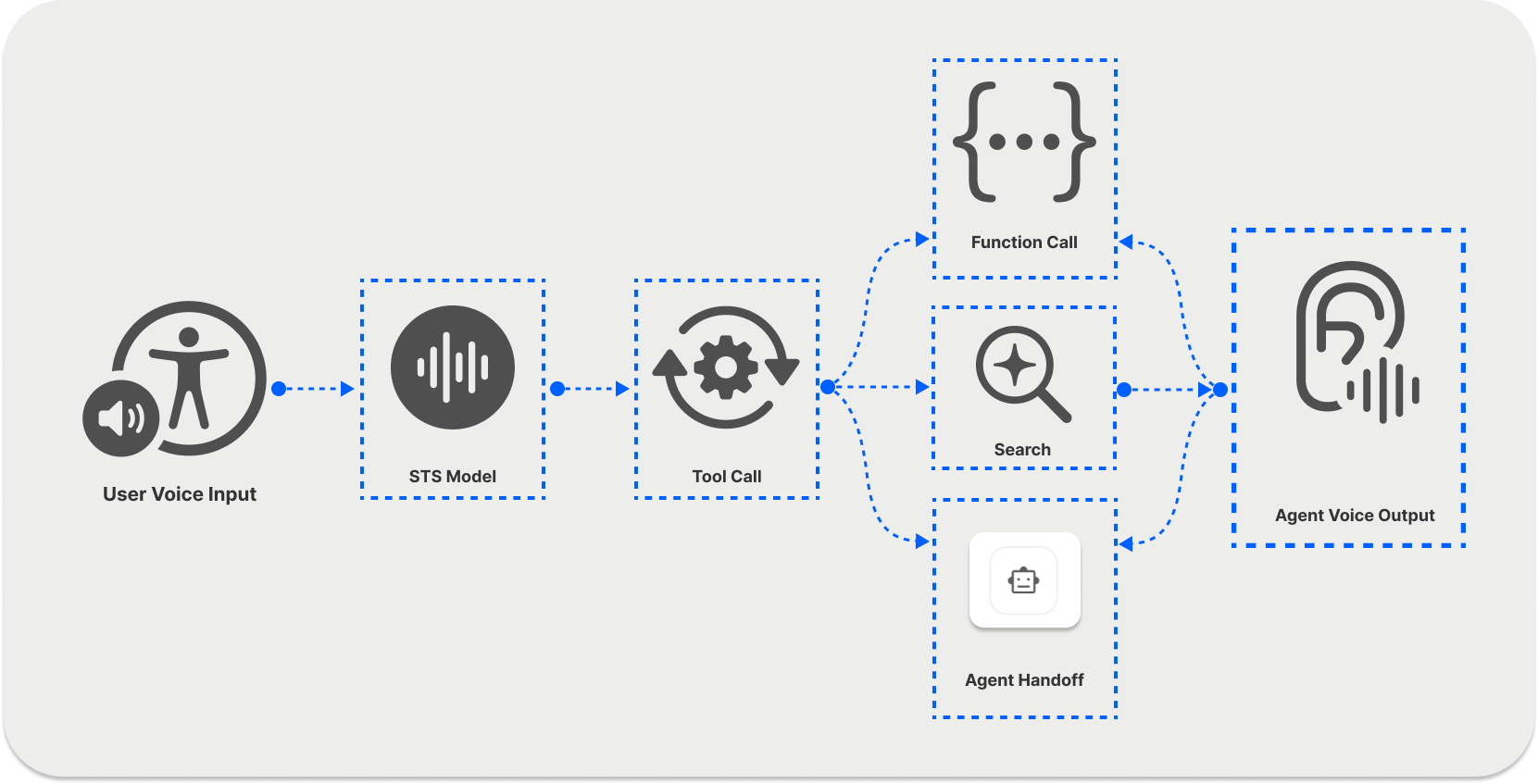
The real-time or integrated speech-to-speech voice pipeline approach relies on a single multimodal AI model that uses users' voice input to generate audio output, as seen in the diagram above. The LLM has speech and text generation capabilities, eliminating the need for separate STT and TTS models.
At the time of writing this article, the best real-time models include Qwen3-Omni, OpenAI gpt-realtime, and Gemini 2.5 Flash, among others. Try gpt-realtime via the OpenAI Playground or the Realtime API.
Gemini 2.5 Flash is available on Google AI Studio and through the Live API.
Benefits of STS Architecture Over STT → LLM → TTS
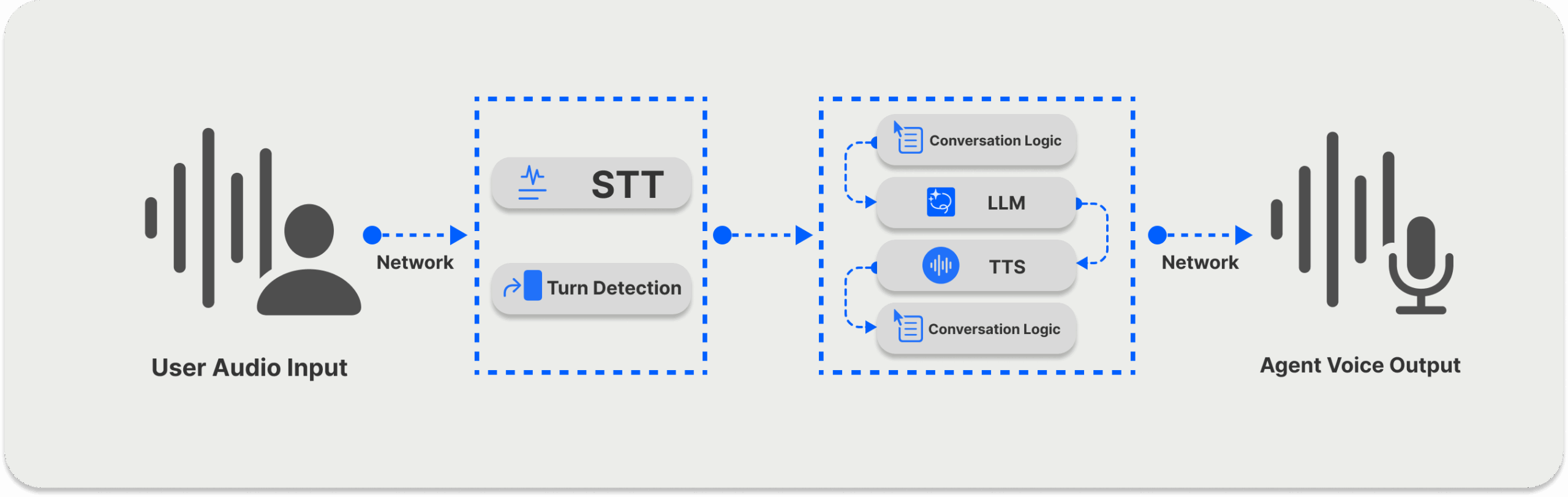
The diagram above represents a standard single-turn voice-to-voice AI service.
When a user initiates a voice conversation through a network in a turn-based voice system, the pipeline's STT component transcribes the user's speech, performs turn detection in parallel, and sends it to an LLM. The system also has a TTS component that is responsible for generating a user audio output.
As mentioned previously, the real-time (Voice → LLM → Voice) architecture has several advantages over the turn-based (Voice → STT → LLM → TTS → Voice) architecture. These include:
- Architecture: STS removes the sequential pipeline (
Voice → STT → LLM → TTS → Voice) since its LLM understands both text and speech generation. Dealing with a single model simplifies the voice system. - Transcription: The STS system transcribes sentences partially, while STT/ TTS can only transcribe complete sentences.
- Latency: STS results in low latency and is suitable for live support agent services and fast-paced environments. The
Voice → STT → LLM → TTS → Voicepipeline can be optimized for low latency, but can also result in poor quality. - Multimodal capability: An STS model uses a single AI model for voice input and output with a simplified architecture.
Top 5 Real-Time Speech-to-Speech APIs and Libraries
This section introduces you to the top five speech-to-speech APIs and tools, allowing developers to quickly build low-latency voice and video AI applications.
Several startups and companies provide STS models and services for building speech/video apps. However, when writing this article, major STS platforms include OpenAI Realtime API, Gemini Live API, Amazon Nova Sonic, Azure OpenAI Realtime API, and FastRTC. Let's highlight the details of each platform in the following sections.
1. OpenAI Realtime API
The OpenAI Realtime API allows developers to build multimodal AI apps with low-latency user experiences. It uses voice LLMs that support seamless STS interactions and input formats such as audio, image, and text.
The API is excellent for audio and text generation, such as real-time voice transcription, and works seamlessly with the OpenAI Agents SDK supporting:
- Connection Types: The API supports connecting your voice applications with WebRTC, WebSockets, and SIP.
- Interruption Handling: It provides efficient mechanisms to handle user-AI agent interruptions.
- Tool Calling: Define your tools with custom code and call them anytime.
- Guardrails: Monitor and restrict the output of an agent in your app with built-in guardrails.
- Reusable Components: Use the same API and SDK components to build text-based and voice agents.
OpenAI Realtime API Quickstart
An everyday use case of the Realtime API is voice-to-voice generation. It can be used for any service requiring natural language input and output, such as kids' storytelling apps.
The example below uses the gpt-realtime model in OpenAI Playground to transcribe a user's voice and generate an audio output in real time.
Implementing the above example in a video conferencing app can be helpful for transcribing video call participants' voices in real time.
The following example uses the Realtime API for a transcription-only use case with a session object. To implement, you connect the session through WebRTC or WebSockets.
1234567891011121314151617181920{ object: "realtime.transcription_session", id: string, input_audio_format: string, input_audio_transcription: [{ model: string, prompt: string, language: string }], turn_detection: { type: "server_vad", threshold: float, prefix_padding_ms: integer, silence_duration_ms: integer, } | null, input_audio_noise_reduction: { type: "near_field" | "far_field" }, include: list[string] | null }
Check out realtime transcription in the OpenAI API to learn advanced concepts like voice activity detection and transcription handling.
Another application area for the Realtime API is building a voice AI agent using the OpenAI Agents SDK in TypeScript or Python.
Using the API along with OpenAI's STS models, you can quickly build an agent for real-time voice chat. As seen from the diagram at the beginning of this section, the STS models support audio and text streaming and tool calling, making them excellent for creating telephony AI apps for customer support and more.
1234567891011121314151617181920212223import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime'; export async function setupCounter(element: HTMLButtonElement) { // .... // for quick start, you can append the following code to the auto-generated TS code const agent = new RealtimeAgent({ name: 'Assistant', instructions: 'You are a helpful assistant.', }); const session = new RealtimeSession(agent); // Automatically connects your microphone and audio output in the browser via WebRTC. try { await session.connect({ // To get this ephemeral key string, you can run the following command or implement the equivalent on the server side: // curl -s -X POST https://api.openai.com/v1/realtime/client_secrets -H "Authorization: Bearer $OPENAI_API_KEY" -H "Content-Type: application/json" -d '{"session": {"type": "realtime", "model": "gpt-realtime"}}' | jq .value apiKey: 'ek_...(put your own key here)', }); console.log('You are connected!'); } catch (e) { console.error(e); } }
The sample TypeScript code above creates a voice agent with the Realtime API that you can interact with via the web browser. Consult the voice agent quickstart for a step-by-step guide on using the Realtime API for your projects.
2. Gemini Live API
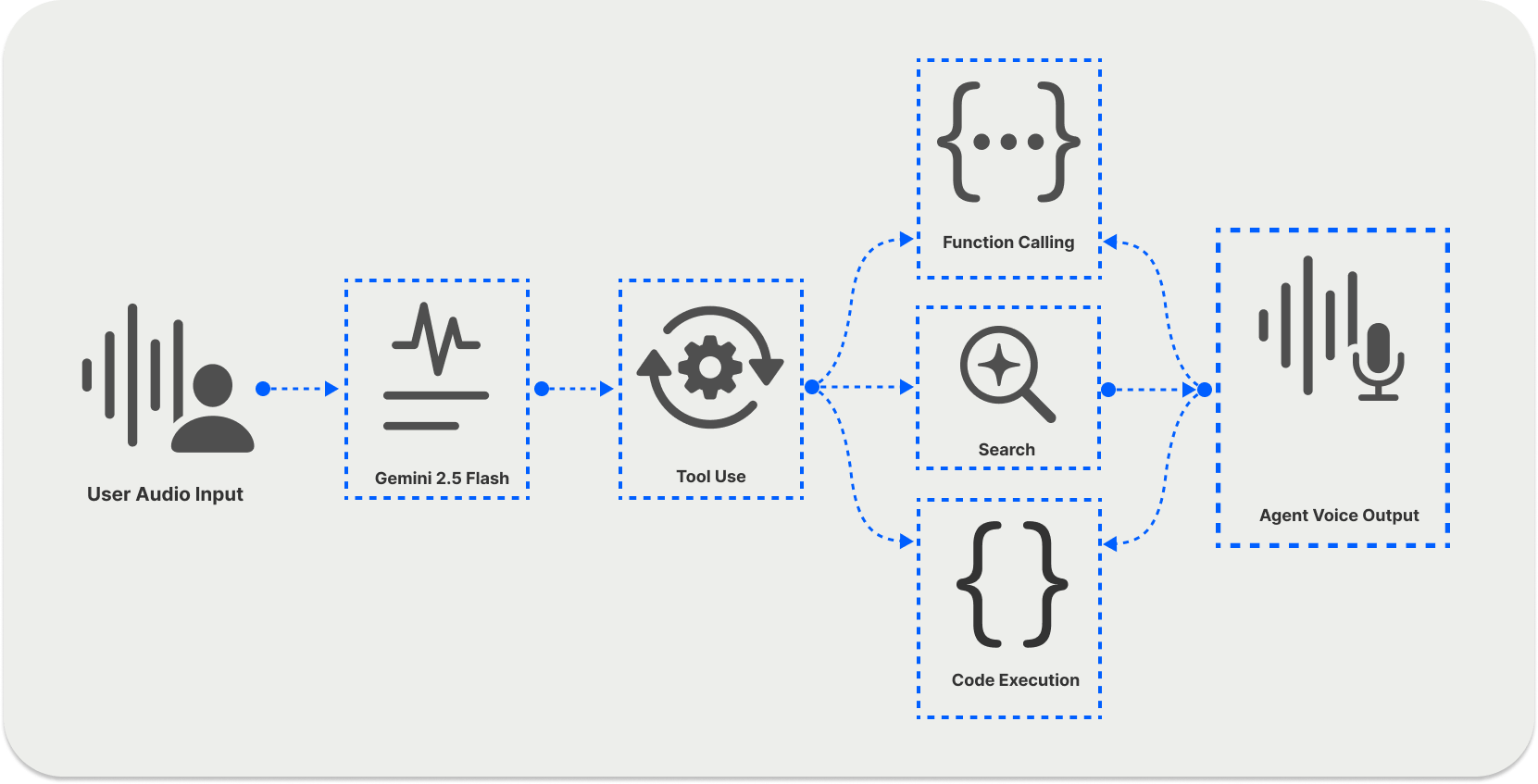
The Live API uses Gemini models to process audio, text, and video and generate spoken responses. Like the OpenAI Realtime API, the Gemini Live API supports the following:
- Connection: Connect your AI applications via WebSockets.
- Voice Activity Detection (VAD): Allows an LLM to recognize when a user is talking and when a user has finished speaking.
- Tool Use: Access external content without hindering its real-time connection. Its tools include search, function calling, code execution, and URL context.
- Session Management: Stream input and output continuously to establish a persistent session connection.
End-to-End Use Cases of Gemini Live API
Using the Live API, you can create a bidirectional AI voice system that streams audio through a user's microphone. Visit the Live audio starter app in Google AI Studio to experience a practical Gemini voice agent example and how the Live API works. The sample app uses JavaScript libraries to connect with the Live API to create a user-agent voice interaction.
When working with the Live API, you can decide which type of model you want to use to generate audio and choose your implementation method. For audio generation, you can select between native and half-cascade audio.
- Native Audio: The native audio option is excellent for building multilingual and natural-sounding voice applications. With this option, you can also access Gemini's advanced features like affective dialog, which allows the model to adapt its output to an input expression and tone. Models available for this audio generation method are
gemini-2.5-flash-preview-native-audio-dialogandgemini-2.5-flash-exp-native-audio-thinking-dialog. Some OpenAI models support native audio, but the Gemini Live API handles the feature better. - Half-Cascade Audio: In this method, native audio is used as an input while the output uses TTS. It supports
gemini-live-2.5-flash-previewandgemini-2.0-flash-live-001, and is excellent for production voice applications with tool use.
You can connect the Gemini Live API to work with your app through the app's backend (server-to-server) or frontend (client-to-server).
- Server-to-Server: Connect your app's backend to the Live API using WebSockets.
- Client-to-Server: Stream data in your app by connecting the front end directly to the Live API using WebSockets.
Gemini Multimodal Live API Quickstart
To build voice applications with the Live API, you should first install the SDK and store your Google API key on your machine.
12pip install -U -q google-genai export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
To illustrate the Live API's simple usage, create a Python file and replace its content with the following sample code. This example shows a turn-based text-to-voice interaction. The user sends a text message, and the agent responds with an audio output.
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576import asyncio import base64 import contextlib import datetime import os import json import wave import itertools # Audio playback - using standard library instead of IPython import subprocess import sys from google import genai from google.genai import types os.environ['GEMINI_API_KEY'] = os.getenv('GEMINI_API_KEY') client = genai.Client(api_key=os.environ['GEMINI_API_KEY']) MODEL = "gemini-live-2.5-flash-preview" # @param ["gemini-2.0-flash-live-001", "gemini-live-2.5-flash-preview","gemini-2.5-flash-preview-native-audio-dialog"] {"allow-input":true, isTemplate: true} @contextlib.contextmanager def wave_file(filename, channels=1, rate=24000, sample_width=2): with wave.open(filename, "wb") as wf: wf.setnchannels(channels) wf.setsampwidth(sample_width) wf.setframerate(rate) yield wf config={ "response_modalities": ["AUDIO"] } async def async_enumerate(aiterable): n=0 async for item in aiterable: yield n, item n+=1 async def main(): async with client.aio.live.connect(model=MODEL, config=config) as session: file_name = 'audio.wav' with wave_file(file_name) as wav: message = "Hello? Gemini are you there?" print("> ", message, "\n") await session.send_client_content( turns={"role": "user", "parts": [{"text": message}]}, turn_complete=True ) turn = session.receive() async for n,response in async_enumerate(turn): if response.data is not None: wav.writeframes(response.data) if n==0: print(response.server_content.model_turn.parts[0].inline_data.mime_type) print('.', end='') # Play the audio after the session is complete print(f"\nAudio saved to {file_name}") print("Playing audio...") try: # Try to play audio using system default player if sys.platform == "darwin": # macOS subprocess.run(["afplay", file_name]) elif sys.platform == "win32": # Windows subprocess.run(["start", file_name], shell=True) else: # Linux subprocess.run(["aplay", file_name]) except Exception as e: print(f"Could not play audio automatically: {e}") print(f"You can manually play the audio file: {file_name}") if __name__ == "__main__": asyncio.run(main())
Running the above sample code in your Terminal will generate an audio file audio.wav for playback.
For more examples of Live API usage, refer to this cookbook.
3. Amazon Nova Sonic Speech-to-Speech Foundation Model
Amazon Nova consists of audio, code, image, and text generation models. Nova Sonic is a live speech model capable of producing human-sounding and natural-voice conversations.
You can access the model through your Bedrock account or via the browser. The web browser option is available only for specific locations.
Key Features of Nova Sonic
Nova Sonic has many STS generation capabilities. The following highlights some of its key features.
- Dialog Handling: The STS model can detect non-verbal cues such as laughter and guttural sounds. It also has a built-in mechanism to handle interruptions and pauses.
- Latency: You can stream bidirectional speech input and output with low latency.
- Supported Languages: Nova Sonic supports English, French, German, Italian, and Spanish.
- Speech Recognition: Its architecture can automatically detect background noises and recognize diverse accents.
- Adaptive Speech Response: The model is an excellent choice if you want to build a voice agent that can adapt to different user sentiments and tones.
Conversational Voice AI Apps With Sonic Nova Quickstart
To get started, set up a Bedrock account and run this simple Python sample code from Amazon's GitHub repo. This lets you test and experience Nova Sonic's functionality.
Visit Nova Sonic's user guide for advanced voice AI use cases, code examples, tool use, and error handling.
4. Azure GPT Realtime API
The GPT Realtime API for speech and audio allows developers to build AI applications with voice support in JavaScript, Python, and TypeScript. It uses the GPT-4o family of models to create low-latency conversational voice experiences.
Like the other STS APIs we discussed previously, the GPT Realtime API can be implemented with WebRTC or WebSockets to transport and receive audio from the model in real-time.
It supports the following OpenAI real-time models:
gpt-4o-realtime-preview(version2024-12-17)gpt-4o-mini-realtime-preview(version2024-12-17)gpt-realtime(version2025-08-28)
Since the GPT Realtime API is part of the OpenAI Realtime API we covered previously, this section does not show getting-started code or sample demos. However, you can read this article on using the GPT Realtime API for speech and audio. When you build audio apps with the Realtime API, you can deploy them on the Azure AI Foundry Portal.
5. FastRTC: Realtime Communication Library for Python
FastRTC is a Python library for real-time communication. With this library, you can create real-time voice apps using WebRTC or WebSockets to stream audio/video, similar to the APIs discussed earlier. The library was created by the team at Hugging Face and works out of the box with the Gradio front end.
FastRTC has the following key capabilities:
- Turn Taking: The library has a built-in turn-taking mechanism and automatic speech detection.
- Built-In Gradio Integration: Launch your voice agent with integrated Gradio UI using the
.ui.launch()method. - Telephony Support: To enable voice phone calling in your AI app, use the library's
fastphone()method. - Easily Customizable: You can quickly customize the library components to build a production-ready voice service.
- WebRTC and WebSockets Support: Use WebRTC for your app's front end and WebSockets endpoint for the back end.
FastRTC Quickstart
The FastRTC website has an excellent quickstart guide on building real audio and video AI applications with the library. For various examples and library-related concepts, check out its cookbook and the user guide.
For a quick voice chat demo in Python, you should first configure a virtual environment and install the FastRTC library.
1234567python -m venv venv source venv/bin/activate pip install gradio pip install fastrtc # Install the vad, stt, and tts extras pip install "fastrtc[vad, stt, tts]"
The sample code snippet below creates a simple audio app powered by Gradio UI. It takes the user's voice input and echoes it as output.
1234567891011121314from fastrtc import Stream, ReplyOnPause import numpy as np def echo(audio: tuple[int, np.ndarray]): # The function will be passed the audio until the user pauses # Implement any iterator that yields audio # See "LLM Voice Chat" for a more complete example yield audio stream = Stream( handler=ReplyOnPause(echo), modality="audio", mode="send-receive", )
Once you set up your environment and run this Python script, you should see the app available on your localhost at port 7860 http://127.0.0.1:7860.
Refer to the FastRTC website for advanced examples and everyday use cases of the real-time communication library.
What’s Next in Real-Time Speech-to-Speech AI?
This article showed you the top five APIs and libraries for building real-time voice and video applications, as well asagentic AI services. You discovered different speech-to-speech models and API platforms like OpenAI Realtime, Gemini Live, Amazon Nova Sonic, and more.
Check out these articles to learn more about integrating voice/video AI capabilities in your app:
- 8 Best Platforms To Build Voice AI Agents
- Using a Speech Language Model That Can Listen While Speaking
- WebRTC vs. WebSockets
When this article was written, real-time voice AI and models were in their early stages and not seen in many production apps compared with STT and TTS models. However, that may change in the future as STS has the potential to be used together with turn-based architectures for multimodal conversational AI use cases.