

In 2021, Twitch streamers, mainly Black and LGBTQ+, were hit with a wave of "hate raids." These automated bot swarms dumped dozens of identical slurs and threats into chat rooms in bursts that lasted seconds. The median raid spewed ~48 messages in <16 s. 222 bots hit one channel at once.
In the fallout, creators organised #ADayOffTwitch blackout; analytics firm Gamesight reported Twitch viewership fell 5‑15 % that day, the platform's lowest of the year.
How do you fight against that? Even without swarms, if every message needs to be checked on a large platform that is processing millions of messages, how do you do so without compromising the user experience?
The answer is to build a system that layers multiple detection methods, from instant to async, without blocking 99.9% of legitimate messages that keep communities thriving.
Defining Your Moderation Policy
While it might seem tedious compared to diving into technical solutions, defining a clear moderation policy is the bedrock of any effective content moderation system.
Picture this: You've built a sophisticated content moderation service with cutting-edge AI, regex filters, and behavioral tracking. It can process millions of messages per second. But when a user posts "kys," your system doesn't know whether to flag it, block it, or let it through. Why? Because you never defined what constitutes self-harm content in your community guidelines.
This is the paradox of content moderation at scale: The technology is often the easy part. The hard part is deciding what "harmful" means for your specific community.
Content moderation is only effective when it’s aligned with content compliance, the legal and policy framework your system enforces. For a deeper look at how to design and operationalize those requirements, see our Guide to Content Compliance.
Why Policies Matter More Than Technology
A moderation policy is the instruction manual for every automated decision your system will make millions of times per day. Without it, you're essentially asking your moderation tools to enforce rules that don't exist.
Consider these two communities:
-
A mental health support forum where discussions of self-harm are therapeutic and necessary
-
A gaming platform where the same discussions could be harmful or triggering
The same message—"I've been thinking about hurting myself"—requires different responses. Your policy defines which response is correct.
Key Components of a Moderation Policy
1. Harm Categories and Severity Levels
Start by mapping out what types of content you want to moderate. Stream identifies over 40 harm types, from obvious categories like hate speech and threats to nuanced ones like coordinated inauthentic behavior. But not all harms are created equal. Define severity levels for each category:
-
Critical: Immediate threats, CSAM, terrorism (always block)
-
High: Targeted harassment, graphic violence (usually block)
-
Medium: Profanity, spam, off-topic content (flag or warn)
-
Low: Mild negativity, criticism (usually allow)
2. Action Thresholds
For each harm type and severity level, decide what action to take:
-
Block: Message never appears
-
Shadow Block: Visible only to sender (useful for repeat offenders)
-
Flag: Appears but marked for review
-
Bounce: Return message to sender.
The key is proportionality. A first-time profanity violation might warrant a warning, while coordinated hate raids demand immediate blocking.
3. Cultural and Contextual Considerations
Language is messy. What's offensive in one culture might be a term of endearment in another. Your policy needs to account for:
-
Regional differences
-
Community-specific terminology (gaming slang vs professional networks)
-
Evolving language (new slurs, reclaimed words)
-
Context collapse (when different user groups collide)
Building Your Policy: A Practical Framework
-
Start with your values: What kind of community do you want to build? Safe for whom? Open to what?
-
Study your users: What problems do they face? Analysis of your flagged content can reveal patterns you didn't expect.
-
Design for edge cases: The bulk of your content will be fine. Design your policy for the 0.1% that causes 90% of your problems.
-
Plan for evolution: Language changes. New attack vectors emerge. Build in regular review cycles.
-
Document everything: Every moderator (human or AI) needs to make consistent decisions. Clear documentation prevents drift.
Your moderation policy is your North Star. It tells your moderation system what phrases to look for. It trains your AI on what severity levels mean. It guides your rules on when to escalate from warnings to bans. Every technical layer you build will reference back to this foundation.
Let's now go through the technical layers to successful moderation. Here's what the entire process looks like:
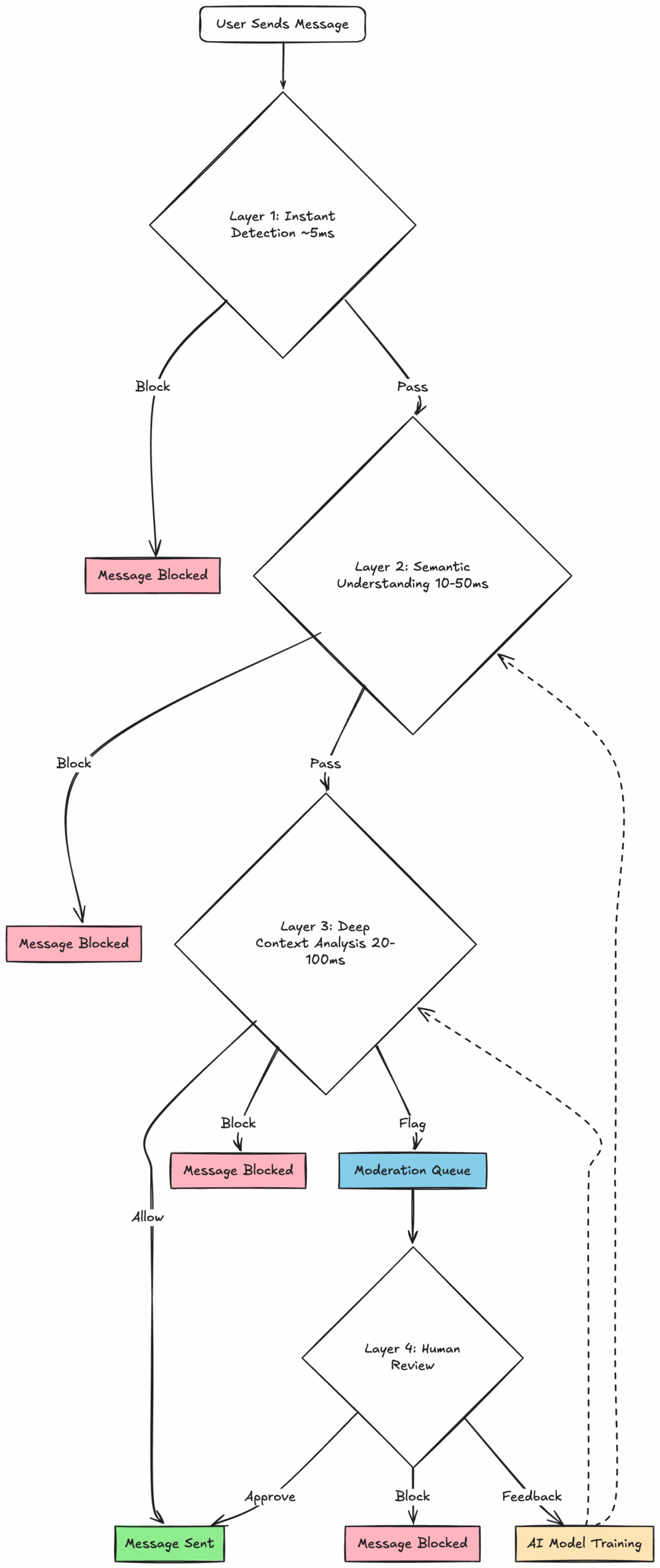
Layer 1: Instant Detection - The First Line of Defense
Speed matters when milliseconds count. In the time it takes to read this sentence, a popular Twitch streamer's chat has processed dozens of messages. Each one needs to be checked, approved, and displayed, all within the 50-100ms window before users notice lag. This is where instant detection earns its keep: the unglamorous but essential work of pattern matching that keeps 90% of obvious spam from ever hitting your users' screens.
The Speed-First Arsenal
The humble blocklist remains the workhorse of content moderation. It's not sophisticated—it's essentially a bouncer with a list of banned words checking IDs at the door. But when you need to stop the f-word or filter out "buy-v1agra-n0w," nothing beats the sub-millisecond response time of a hash table lookup.
The beauty lies in the simplicity. No AI to spin up, no context to analyze—just pure pattern matching. But blocklists have a fatal flaw: they're hilariously easy to evade. Spammers know this, which is why "viagra" becomes "v!agra" becomes "v.i.a.g.r.a" becomes "vıαgrα" (using Greek alpha).
Regular expressions let you fight back against creative spelling. Instead of blocking "viagra" and its 47 variants individually, you write one pattern:
/v[i!1ı][a@4][g9][r®][a@α]/iNow you're catching hundreds of variations with a single rule. But beware the performance trap. Complex regex patterns can slow your system. The key is balance: powerful enough to catch variations, simple enough to run in microseconds.
Instant detection excels at the obvious cases. It's binary, deterministic, and blazingly fast. But language is rarely binary. Consider:
-
"I'm going to kill it at the presentation" (positive)
-
"I'm going to kill you in Fortnite" (gaming context)
-
"I'm going to kill you" (potential threat)
A blocklist sees "kill" and acts. It doesn't understand context, tone, or intent. That's not a bug; it's a feature. Instant detection is designed to be a coarse filter, catching obvious violations while allowing edge cases to pass through to more sophisticated layers.
This is where lightweight NLP models can give instant detection some much-needed nuance. Instead of just looking for exact word matches, these models can process the surrounding context to understand meaning. They're fast enough to run in parallel with blocklists, still within the sub-100ms budget, but smart enough to tell the difference between "kill it at the hackathon" and "kill you after class."
Implementing Instant Detection
The best instant detection setup follows these principles:
-
Start conservative: Begin with established lists (profanity, known spam domains) and expand based on actual problems.
-
Monitor false positives: Track what gets blocked incorrectly—it's often your first sign that filters are too aggressive.
-
Layer your approaches: Combine blocklists for known bad words, regex for variations, and domain filtering for URLs.
-
Respect the speed budget: Every millisecond counts. Test your regex performance under load.
Instant detection stops the obvious threats immediately, keeping your platform responsive and your users happy. But for the subtle threats, the context-dependent harms, and the ever-evolving language of online communication, you need deeper defenses.
Layer 2: Semantic Understanding - Catching What Keywords Miss
When "I h8 u" means the same as "I hate you"
It's March 23, 2016, and Microsoft's chatbot Tay is having a very bad day. Within 24 hours of launch, Twitter users have taught it to spew racist rhetoric. But here's the thing: they didn't use obvious slurs that blocklists would catch. They used euphemisms, code words, and context-dependent phrases that meant nothing to keyword filters but everything to the people reading them.
This is the semantic gap, the chasm between what words literally say and what they actually mean. It's where traditional moderation falls apart and where semantic understanding begins.
The Meaning Behind the Words
Semantic filters operate on a fundamentally different principle from blocklists. Instead of matching exact strings, they understand intent. They know that:
-
"You should unalive yourself" = "kill yourself"
-
"Check out my OF" = "OnlyFans" (platform bypass)
-
"You're acting real 13/52 right now" = racist dogwhistle
The technology works by converting text into mathematical representations (embeddings) that capture meaning rather than letters. Sentences with similar meanings cluster together in this mathematical space, even if they share no common words.
How Semantic Understanding Works
Think of it like this: every sentence gets mapped to a point in space. "I hate you" might be at coordinates (5, -3, 2). The semantic filter knows that anything within a certain distance, say "I despise you" at (5.1, -2.9, 2.1), means essentially the same thing.
With Stream, moderators can define "seed phrases" that represent harmful content:
Seed phrases for self-harm content:
- "I want to end my life"
- "I'm going to kill myself"
- "Time to self-delete"
The system automatically catches variations:
- "Thinking about ending it all" (similarity: 0.89)
- "Gonna kms tonight" (similarity: 0.85)
- "Time to unalive myself" (similarity: 0.91)The similarity scores tell you how confident the system is that the new phrase matches your seed intent. You can tune the threshold—set it high (0.9+) for precision, or lower (0.7+) to catch more variations at the risk of false positives.
Semantic understanding has its kryptonite: context collapse. The same phrase can be helpful or harmful depending on where it appears:
"How to tie a noose"
-
In a suicide prevention forum: Harmful, should be blocked
-
In a camping/survival community: Legitimate rope technique
-
In a historical education context: Academic discussion
The semantic filter sees the meaning but not the situational context. This is why layered moderation matters. Semantic filters identify potentially harmful content, but you need additional context (user history, channel type, conversation flow) to make the final call.
The power of semantic filters lies in customization. You want to build filters specific to your community's needs:
-
Start with problem content: Pull real examples from your moderation queue.
-
Create seed phrase lists: Group similar violations together.
-
Test variations: Try edge cases to see what gets caught.
-
Adjust thresholds: Find the sweet spot between precision and recall.
-
Monitor for drift: Language evolves, your filters should too.
Unlike instant detection, semantic analysis requires actual computation. Each message gets converted to embeddings and compared against your seed phrases. The magic is in the optimization. Modern systems can do this in 10-50ms, fast enough that users don't notice, but slow enough that you want to be selective.
Best practices for performance:
-
Keep seed phrase lists focused (10-50 phrases per concept).
-
Use instant detection first to reduce semantic processing load.
-
Cache results for common phrases.
-
Process asynchronously when possible.
The beauty of semantic understanding is its adaptability. When "Netflix and chill" became a euphemism, semantic filters learned. When "unalive" emerged as a TikTok workaround, they adapted. You must understand language as it evolves.
But semantic understanding still operates on individual messages. It can catch "I h8 u" but might miss a user who sends 50 seemingly innocent messages that collectively constitute harassment. For that, we need to zoom out further, from understanding meaning to understanding behavior.
Layer 3: Deep Context Analysis - The AI Safety Net
A teenager posts, "I'm so stupid, I should just die," after failing a test. A suicide prevention counselor writes, "If you're thinking of ending your life, please reach out." A gamer types "kys" after losing a match. Three messages about self-harm, three completely different contexts requiring three different responses.
This is where deep context analysis proves its worth. Unlike keyword matching or semantic similarity, AI harm detection models understand the nuance between expressing distress, offering help, and casual gaming toxicity.
Consider how AI evaluates different level of threats:
"I would beat him so badly"
- Context: Sports discussion
- Severity: Low
- Action: Allow
"I'll break your worthless jaw anytime, anywhere"
- Context: Direct threat
- Severity: High
- Action: Block
"We'll kill your wife too"
- Context: Targeted death threat
- Severity: Critical
- Action: Block + AlertThe magic is in understanding the escalation from competitive banter to genuine danger.
AI harm detection models revolve around a core idea: context.
Context matters:
-
"¿Plata o plomo?" in Spanish (literally "silver or lead?" for those that haven't watched Narcos) is a death threat, not a question about metals.
-
"Your mother" jokes are playful banter in some cultures, fighting words in others.
-
The 👌 emoji means "OK" in the US, but is an offensive gesture in Brazil.
AI understands cultural weight. A phrase that's mildly rude in one language might be deeply offensive in another. The system adjusts severity accordingly.
Nuance also matters. What makes AI harm detection particularly powerful is its ability to parse complex scenarios. When marginalized communities reclaim slurs, context becomes everything. The AI evaluates:
-
Who's speaking (in-group vs out-group)
-
How it's being used (empowerment vs attack)
-
Community norms (some spaces allow reclamation, others don't)
Then there is sarcasm and irony. "Oh sure, I LOVE getting hate mail" requires understanding that capital letters and "love" + negative object often signal sarcasm. The AI weighs linguistic markers against content to determine actual sentiment.
Deep context analysis shines where other methods struggle. It catches:
-
Coded language that seems innocent
-
Harmful intent disguised as jokes
-
Serious threats mixed with casual conversation
-
Cultural references that outsiders miss
Real-Time Performance at Scale
The challenge with sophisticated AI analysis is speed. Complex models that understand nuance typically require significant processing power. You can solve this through:
-
Hierarchical processing: Simple cases get fast-tracked, complex ones get deeper analysis.
-
Confidence thresholds: High-confidence decisions happen instantly, edge cases may take slightly longer.
-
Caching intelligence: Common phrases and patterns get cached results.
-
Asynchronous options: For non-critical content, process in background while showing optimistically.
The result? With Stream, most messages are analyzed in under 50ms. Fast enough that users never notice the safety net beneath their conversations.
Implementing AI Harm Detection
Best practices for deployment:
-
Start with defaults, then customize: Use pre-trained models initially, then tune based on your community.
-
Monitor cultural edge cases: What's normal in your community might be unusual elsewhere.
-
Set different thresholds by channel: Competitive gaming channels might tolerate more aggressive language than support groups.
-
Review regularly: Language evolves, and so should your configuration.
-
Combine with other layers: AI is powerful but not infallible, so use alongside other moderation tools.
Layer 4: Human-in-the-Loop - When Algorithms Need Help
Despite all our sophisticated filters and AI models, human moderators remain irreplaceable. They understand context that transcends patterns. They recognize irony that defeats algorithms. Most importantly, they can make judgment calls in the gray areas where even the best AI stutters.
The Moderation Queue
Here's the math that keeps platform safety teams up at night: If your platform processes 10 million messages daily and 0.1% require human review, that's 10,000 messages that need to be moderated. With each review taking 30 seconds, you need 83 human-hours of moderation daily, every single day.
Smart prioritization becomes essential:
-
Severity scoring: Critical threats jump the queue.
-
Confidence weighting: Low-confidence AI decisions get human eyes faster.
-
User history: Repeat offenders get scrutinized more carefully.
-
Community signals: Multiple user reports escalate priority.
-
Context clustering: Similar issues get batched for efficient review.
Think of moderation queues like an emergency room. Not every case needs immediate attention, but the critical ones can't wait. You can break this triage down into three specialized queues:
-
Users Queue: The repeat offenders and suspicious accounts
-
That account created 5 minutes ago posting cryptocurrency links
-
The user with 47 flagged messages in the past week
-
Someone who just got reported by 15 different community members
-
-
Text Queue: Individual messages caught in the gray zone
-
Potential self-harm content that needs sensitive handling
-
Sarcasm the AI couldn't parse
-
Cultural references requiring human context
-
-
Media Queue: Images and videos requiring visual inspection
-
Memes that might contain hidden hate symbols
-
Screenshots of conversations from other platforms
-
Images the AI flagged as "maybe explicit" with 60% confidence
-
Certain scenarios demand human judgment:
-
Nuanced self-harm content: Distinguishing between someone seeking help and someone promoting harmful behavior
-
Historical/educational content: Understanding when harmful content serves legitimate educational purposes
-
Satire and parody: Recognizing when offensive content is actually criticizing the thing it appears to promote
-
Appeals and edge cases: When users claim they were unfairly moderated
-
Evolving situations: Real-time events that change the context of previously acceptable content
The Feedback Loop
The magic isn't in AI learning from customer data. It's in how you refine the system over time.
At Stream, AI moderation models aren't trained on your users' messages or moderator decisions. Instead, we improve accuracy through manual prompt refinement and configuration tweaks, informed by patterns we observe across deployments.
Message: "That's sick bro! 🔥🔥🔥"
AI: Flagged as potential harassment (60% confidence)
Human Moderator: Approved - positive slang
Result: AI learns this pattern for future messagesThis approach ensures privacy while still enabling continuous improvement, without ever storing or learning from your customers' data. The goal is to tune the system to catch more nuanced cases upfront, reducing the human workload and keeping moderation fast, consistent, and safe.
Scaling Human Review Efficiently
-
Batch similar decisions: Instead of reviewing spam messages one by one, moderators can bulk-action obvious cases.
-
Keyboard shortcuts: Professional moderators don't click buttons—they use hotkeys. Approve (A), Block (B), Escalate (E). Speed matters when you're reviewing hundreds of items.
-
Context preservation: Moderators need to see not just the flagged message but the conversation flow. Was it a response to provocation? Part of an ongoing discussion? Context changes everything.
-
Decision templates: Common scenarios get templated responses. This ensures consistency and speeds up review time.
The goal isn't to eliminate human moderators, it's to amplify their effectiveness. When machines handle the obvious cases, humans can focus on the nuanced decisions that require empathy, cultural understanding, and wisdom.
This hybrid model, instant detection catching obvious spam, semantic filters understanding meaning, AI analyzing context, and humans making final calls on edge cases, creates a moderation system that's both scalable and humane. It respects the speed users expect while maintaining the safety they deserve.
The Layered Advantage
By combining instant detection, semantic understanding, deep context analysis, and human expertise, we create a defense-in-depth approach. Each layer catches what the others miss:
-
Speed where it matters: Instant filters stop obvious spam before users see it.
-
Intelligence where it counts: Semantic and AI layers catch evolving threats.
-
Humanity where it's needed: Human moderators handle the nuanced decisions that define community culture.
Whether you're protecting a gaming community of hundreds or a social platform of millions, the principles remain the same:
-
Start with clear policies - Technology enforces the rules you define.
-
Layer your defenses - No single solution catches everything.
-
Move fast on the obvious - Don't make users wait while you analyze clear spam.
-
Stay human on the hard stuff - Some decisions require empathy, not algorithms.
-
Learn and adapt constantly - The threat landscape changes daily.
Stream's moderation platform provides all these layers we've discussed—instant detection, semantic understanding, AI harm analysis, and human review tools—in a single, integrated solution. With the Stream Moderation AI Platform, you can incorporate comprehensive content moderation into your application without writing a single line of moderation code, configure policies through an intuitive dashboard rather than complex APIs, and have enterprise-grade protection running in minutes instead of months of development.