

This blog post is broken into two parts and harkens back to learnings from a prior post. The sum of all these parts is altogether my best effort to provide you with a framework of how to take the creation of personalized news feeds to the next level.
Part 1: Theory behind a very basic EdgeRank style algorithm that was used to build my own Instagram discovery engine.
Part 2: Understanding how to use modern machine learning techniques to optimize ranking in feeds
Part 1: How and why I used this score function
In my last blog post, I walked through how to build your own Instagram discovery engine. It included a fair amount code, but not a lot of discussion around the theory behind why I chose the algorithm below to rank posts.

So let's dig into it a little more. In essence, it is just a variation on the classic facebook EdgeRank algorithm:

This can be broken into 3 main components: affinity, weight and time decay.
Affinity
The term affinity is a way to relate how "connected" a user is to you. The idea being that if you have many mutual friends with whom you've interacted with in the past, you are more likely to want to see that user's future post.
In this example affinity is determined by two terms:

Where PPR is the personal pagerank of me to that user. Other factors could include how many times I commented and how many times I clicked on that user's post.
In Python, the PPR was calculated by creating a NetworkX graph based on who I follow. I then ran a pagerank with a specified personalization dictionary. The personalization dictionary simply tells the NetworkX PageRank algorithm that the probability of resetting to any random node is zero, except for the node that you are "personalizing".
#create social graph and calculate pagerank G = nx.from_pandas_dataframe(df_global, 'src_id', 'dst_id') #calculate personalized pagerank perzonalization_dict = dict(zip(G.nodes(), [0]*len(G.nodes()))) perzonalization_dict[user_id] = 1 ppr = nx.pagerank(G, personalization=perzonalization_dict)
Multiplying the PPR by the natural log of # of times I "liked" a user's post was a way to boost the affinity score of users that I had previously interacted with.
Weight
Weight can be determined by a number of varying factors depending on the type of data you have access to. I based mine on the number of likes and comments the post had.
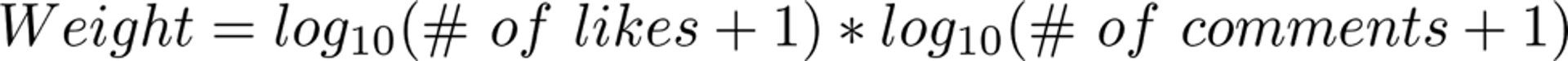
I used logs to make the importance of the first few likes on a post higher than those on a post that already has a lot of likes. The thought process being the difference between 10 and 100 likes should be much more relevant than 100 to 190, even though both have a difference of 90 likes.
Time Decay
Time decay applies to applications that care a lot about "freshness" of an item. It is important to boost newer content rather than old, out-dated content. Time decay ensures newer articles have a shot of appearing at the top of your feed, even though they may not have many likes...yet. Here at Stream, we base most of our decay functions off of Linear, Exponential, and Gaussian decay functions. The function you decide to use depends a lot on the end application and how quickly you want old content to become irrelevant.

Well, that was pretty simple huh? Multiplying three, fairly easy to come by features together can give us some pretty decent results. While tuning only a handful of parameters by hand is fairly easy, what happens when you want to include, 10's, 100's or even 1000's of different parameters to ensure your user's feed is populated with the most relevant content (I know, I know, big build up to the word Machine Learning). Let's take a look...
Part 2: Moving beyond EdgeRank to Boosted Trees and Neural Networks
While a simple EdgeRank style algorithm is easy to implement, it does have a few shortcomings depending on how much data your application has. It may seem obvious, but the optimal feed is one that will engage users the most. Achieving this can be hard to create if you have a lot of parameters that you want your feed to be based on. Engagement can be based on many different parameters depending on the application. For an Instagram style feed, they could be based on Clicks, Likes, Comments, Sends, Follows, and Unfollows. We can treat each of these metrics as different models, optimize each one, and, in the end, add them up for a final score.

[1]
Total Score = 30.6015.
So what model can we use to predict the probability of all of these events? One way that has been proven to be successful in ranking feeds at scale[1] is boosted decision trees stacked with logistic regression. Using boosted decision trees allows us to throw (almost) as many features as we want at the model and let it decide what is important. After the decision trees are trained we can take each input feature and turn it into a set of categorical features. We then use those categorical features as one-hot encoded inputs into a logistic regression to relearn the leaf weights. This extra step allows us to speed up the training process and push the training step to a near-online model, while still taking advantage of the feature transforms that the boosted trees provided us.
Pro-tip: for production, you may want to prune the number of features to speed up training time and mitigate overfitting.

(Yellow nodes represent categorical features, green nodes represent leaf weights to be relearned)
So what features can we use to feed into a boosted decision tree model? Let's break them into two subcategories: contextual and historical.
Contextual features are those that make up the content. For instance, the all powerful puppy within a puppy photo that has the hashtag #puppiesofinstagram.
Historical features can be described by the engagement priors between the author and the viewer. Understanding an individual's network structure here is important as it allows one to see who their close friends are, whose photos they always like, whose photos they only like when they post images of cats, and whose photos they always comment on when pictures of puppies are posted. Other important historical features include people you may know in real life and people who you search for. For example, I always like posts from haystackpets, so they should show up first in my feed. (Yes, that was a shameless plug for my pet's Instagram account.)
Historical features will drive most of the engagement, but contextual features are essential for the cold start problem. While boosted trees are a favorite of the Stream team (and have been at the cutting edge for a long time) there are situations where Neural Networks can perform better. Mostly, when you have a LOT of sparse data to rank.
In terms of setup, the model for Neural Networks can be set up in almost the same way as boosted trees. By having the inputs of your neural network be a single stream of data with features and feedback labels, and the output be a single node with a sigmoid function to predict the probability of an event.
Since Neural Networks can be expensive to train, we can utilize a simple trick that is often used in image recognition. Instead of training the entire Neural Network from scratch for each metric, we can utilize transfer learning to train it for one then reuse the expensive to train base layers and fine tune the top dense layers for each metric that you want to optimize. An example of how a feed-forward Neural Network would look is shown below.

This can still be quite expensive to compute depending on the number of feeds you need to rank each day. Facebook has combined Neural Networks with boosted decision trees to help mitigate the cost of inference in neural networks, and still get the performance gain [2].
Once you train your Neural Network you can use the last layer as a feature vector and input it into a logistic regression model for each event, so that we can speed up training and quickly take new data into account. Plus, as an added bonus you'll also have a great topic for your next cocktail party.
Wow, I definitely brushed over a lot of topics there. We also have a lot of great information about how you can implement personalized ranked feeds in your application. Feel free to reach out to me or anyone on our data science team to walk through how it could improve your app!
[1] Ewa Dominowska - Generating a Billion Personal News Feeds - MLconf SEA 2016 (https://www.youtube.com/watch?v=iXKR3HE-m8c)
[2] Measurement and analysis of predictive feed ranking models on Instagram
(https://code.facebook.com/posts/1692857177682119/machine-learning-scale-2017-recap/)