
Imagine you're happily playing PUBG. The circle is closing; your team still has a chance of a chicken dinner, until you get sniped.
Then it starts. A stream of toxic voice chat erupts from a teammate. Slurs and threats that destroy the match. You hit mute, but the damage is done. This scenario plays out thousands of times daily across gaming platforms, social media, and streaming services.
A study on harassment in online games Valorant and Overwatch found that sexual comments were heard in 14.2 % of matches, profanity in 80.8 %, and general verbal abuse in 25.8 %.
Audio and voice management has become one of the most critical challenges in digital content moderation. Here, we will go through what audio and voice moderation is, the challenges with implementing this type of moderation, the processes to do so, and the best practices organizations can follow to ensure their users have safe, inclusive, and positive voice communication experiences while maintaining platform integrity and regulatory compliance.
What is Audio and Voice Moderation?
Audio and voice moderation is the process of monitoring, analyzing, and filtering spoken content in real-time or post-production to identify and remove harmful, inappropriate, or policy-violating material.
This includes, but isn't limited to, detecting:
-
Hate speech
-
Harassment
-
Threats
-
Sexual content
-
Spam
-
Other forms of verbal abuse
Audio and voice moderation is applicable across various audio formats, including live voice chat on gaming and streaming platforms, as well as pre-recorded podcasts, voice messages, and video soundtracks.
Why Audio and Voice Moderation Matters
Recent research reveals that identity-based harassment occurs in approximately 50% of hour-long gaming sessions, with one-third specifically targeting players' identities. This toxic environment has created a significant comfort gap, with 61% of LGBTQ gamers feeling uncomfortable using voice chat compared to 40% of non-LGBTQ gamers, effectively silencing marginalized communities who avoid voice communication entirely to escape harassment.
The problem extends far beyond gaming. Discord, processing 4 billion voice-conversation minutes daily, reports that harassment constitutes 32% of all incident reports, its single largest abuse category. In professional settings, the shift to remote work hasn't eliminated workplace harassment, but instead relocated it: 43% of remote workers report experiencing bullying, with 35% stating that it occurred during group virtual meetings. Among those experiencing workplace discrimination, 80% report it happening through video conferencing and voice channels.
These statistics translate to real-world harm. Depending on the platform, between 1 in 7 and 1 in 3 live voice interactions expose users to toxicity. Without effective moderation, platforms risk user attrition, reputational damage, and potential legal liability.
More critically, unchecked voice abuse creates hostile environments that exclude vulnerable users, stifle diverse perspectives, and normalize harmful behavior. For platforms hosting billions of minutes of voice content daily, even small percentages of abuse represent millions of harmful interactions that demand immediate intervention.
Business, Legal, and Brand-Risk Implications
Voice abuse hits the bottom line hard. A survey of 2,408 gamers found that 1 in 5 players spend less money on platforms with toxic voice chat, while 3 in 10 abandon matches entirely to escape harassment. Even more telling: 4 in 10 players simply disable voice chat altogether, defeating the purpose of the feature.
The operational costs compound quickly. CollX's implementation of moderation reduced in-app phishing attempts and harmful content by 90% in the sports card marketplace, pushing their user retention rates up to 75%. Fewer incidents mean fewer moderator hours and support tickets, resulting in direct cost savings that offset the moderation investment.
Legal exposure has reached eye-watering levels. Epic Games paid $520 million to the FTC in 2022 ($275 million civil penalty plus $245 million in refunds), with the settlement forcing Fortnite to turn off live voice and text chat by default for minors. This precedent shows regulators will tie voice-safety failures directly to consumer protection law.
Brand damage extends beyond legal penalties:
-
26% of advertisers plan to cut spending on X/Twitter due to "toxic content."
-
Discord's transparency reports show harassment and bullying as their second-largest violation category (19% of all reports), while processing 4 billion voice minutes daily.
-
Workplace platforms face Title VII hostile-environment claims when voice abuse occurs in virtual meetings, where 43% of remote workers report experiencing bullying.
Voice moderation isn't optional. It protects revenue, reduces costs, and prevents catastrophic legal exposure.
The Challenges of Audio and Voice Moderation
Unlike text moderation, where you can analyze at your own pace, voice moderation must keep up with human conversation. Gamers expect near-instant responses—under 300 milliseconds—forcing platforms into a difficult choice: process locally with limited accuracy or accept conversation-killing delays.
Real-world voice chat presents multiple technical hurdles:
-
Background noise from cafés, roommates, and construction sites
-
Various people talking simultaneously during heated gameplay
-
Poor mobile microphone quality captures everything indiscriminately
-
Game sound effects and music bleeding into voice channels
Traditional speech recognition, trained on clean audio, fails spectacularly in these chaotic environments.
Language and Cultural Complexity
Modern online communication breaks every assumption built into moderation models. A single Discord channel might feature multiple languages to moderate, like English, Spanish, and Korean in the same conversation, with speakers code-switching mid-sentence. Teen slang evolves weekly. Regional accents can confound systems that expect standard pronunciation. Gaming terminology like "that's sick!" can have opposite meanings depending on the context, tone, and relationship between speakers.
The Context Problem
Context changes everything. Friends greeting each other with profanity aren't violating policies, but identical words from strangers constitute harassment. Sarcasm flips meaning entirely: "great job!" becomes mockery through tone alone.
Current solutions remain imperfect:
-
Acoustic analysis detects aggressive pitch and volume patterns
-
AI systems consider conversation history and user relationships
-
Emotion detection identifies hostile intent beyond words
-
Human reviewers handle appeals and edge cases
Even the most sophisticated systems struggle with nuance, making human oversight essential.
Regulatory Landscape Snapshot
The regulatory noose around voice platforms tightened dramatically in 2024-2025. Multiple jurisdictions now explicitly target real-time audio communication with hefty penalties.
-
EU Digital Services Act (DSA): The DSA requires risk assessments specifically for "audio-based real-time communication" and detailed transparency reports (first due 2025). Platforms serving EU users must implement notice-and-action workflows and cooperate with trusted flaggers to ensure compliance with EU regulations.
- Penalties: Up to 6% of global annual turnover per infringement. For a €5 billion revenue company, that's €300 million per violation.
-
UK Online Safety Act 2023: Explicitly covers voice chat and livestream audio for any service accessible in the UK. Mandates safety-by-design, risk audits, age verification, and swift removal of illegal content. Ofcom can block services or bring criminal charges against executives who fail to comply with its regulations.
- Penalties: Fines up to £18 million or 10% of worldwide revenue, whichever is higher.
-
U.S. COPPA (2025 Amendments): New rules treat voiceprints and children's audio as personal information requiring parental consent. A narrow exemption allows collecting a child's voice only to fulfill a specific request, then immediately deleting it. The FTC plans spot audits on voice-chat products marketed to users under 13 years old.
- Compliance deadline: April 22, 2026.
-
HIPAA Requirements: Audio-only telehealth must protect Protected Health Information (PHI). While landline calls are exempt from the Security Rule, Privacy Rule safeguards apply to all voice communications. The COVID-era enforcement discretion expired in May 2023.
- Penalties: Up to $50,000 per violation, with annual caps of $1.9 million (indexed for 2025).
-
ESRB: Games with unfiltered voice chat must display the "Users Interact" label. Many retailers and platforms require this disclosure before listing. Starting in August 2025, ESRB will begin conducting random audits of live-service games' chat settings against their label claims.
The Core Concepts of Audio and Voice Moderation
Understanding audio moderation requires familiarity with both technical systems and policy frameworks. The field combines speech processing technology with content policy enforcement, creating a specialized vocabulary that spans engineering and trust & safety disciplines.
Audio Moderation vs. Voice Content Moderation
While often used interchangeably, these terms have distinct meanings in practice.
Audio moderation encompasses all sound-based content: music copyright detection, sound effect analysis, background audio in videos, and non-speech audio signals. It includes monitoring podcasts for licensed music, detecting gunshots in livestreams, or identifying prohibited sound effects.
Voice content moderation specifically targets human speech. This narrower focus enables specialized techniques such as speaker identification, emotion detection, and linguistic analysis, which wouldn't apply to general audio. Voice moderation systems optimize for conversation dynamics, turn-taking patterns, and the social context of speech.
Most platforms need both. A gaming platform moderates voice chat between players (voice content) while also scanning for copyrighted music playing in the background (audio). The distinction matters when selecting vendors, as some excel at speech while others specialize in broader audio analysis.
Key Technical Terms
-
VAD (Voice Activity Detection): The first gate in any voice moderation pipeline. VAD determines when someone is speaking versus when there is silence or background noise. Accurate VAD prevents wasting computational resources on dead air while ensuring that no spoken content is missed. Modern VAD uses machine learning to distinguish speech from similar sounds like music or game effects.
-
Diarisation: The process of determining "who spoke when" in multi-speaker audio. Diarisation segments continuous audio into speaker turns, crucial for assigning violations to specific users in group chats. Advanced systems can track speakers even when they talk over each other or change their acoustic properties (such as switching from a calm tone to a shouting one).
-
ASR (Automatic Speech Recognition): Converts spoken words into text for analysis. Modern ASR handles accents, background noise, and informal speech patterns. Accuracy can vary dramatically, with pristine audio achieving 95% accuracy, while noisy gaming chat drops to 70%. Some systems now use "end-to-end" models that skip text conversion entirely, analyzing speech patterns directly.
-
Toxicity Score: A numerical assessment (typically 0-1 or 0-100) indicating how likely audio contains harmful content. Scores combine multiple signals, including word choice, acoustic features such as shouting, and contextual factors. Platforms set thresholds for automatic action, so perhaps 0.8+ triggers immediate muting while 0.5+ flags for human review.
-
Severity Tier: Classification systems that rank violations by harm potential. A typical three-tier system:
-
Tier 1 (Critical): Immediate threats, CSAM, severe hate speech—requires instant action
-
Tier 2 (High): Harassment, moderate hate speech, graphic content—rapid review needed
-
Tier 3 (Low): Mild profanity, spam, borderline content—standard review queue
-
Policy Vocabulary
Effective moderation requires precise definitions that distinguish between similar but distinct harms:
-
Harassment: Targeted attacks on individuals or groups intended to intimidate, shame, or silence. In voice context, this includes sustained verbal attacks, coordinating pile-ons, or following users across channels. Harassment often escalates in voice chat due to real-time dynamics and emotional immediacy.
-
Hate Speech: Attacks on protected characteristics, such as race, religion, gender identity, sexual orientation, disability, or national origin. Voice adds complexity through tone and emphasis. "Those people" can become hate speech simply through intonation. Platforms must clearly define protected categories and train models on culturally specific slurs.
-
Extremist Content: Promotion of or recruitment for violent ideological groups. Voice channels pose unique risks as extremists use them for real-time coordination and radicalization. Detection requires understanding coded language, identifying known extremist rhetoric patterns, and sometimes analyzing networks of speakers.
-
Self-Harm Content: Promotion or instruction of self-injury or suicide. Voice moderation must distinguish between someone seeking help ("I'm having dark thoughts") versus actively promoting harmful behaviors. This requires nuanced policies that protect vulnerable users while enabling support conversations.
-
Privacy Breach: Sharing personal information without consent, such as addresses, phone numbers, real names, or financial data. Voice chat privacy breaches often happen accidentally when users forget they're being recorded or don't realize how far their voice carries. Platforms need clear policies on doxxing, revenge porn threats, and inadvertent personal information disclosure.
Each policy category requires different detection approaches, response protocols, and appeals processes. The real-time nature of voice makes precise categorization crucial - you can't unmute someone after realizing their "hate speech" was friendly banter between friends who share that identity.
The Audio and Voice Moderation Pipeline
Voice moderation pipelines transform raw audio streams into actionable safety decisions within milliseconds. Each stage involves technical choices that strike a balance between accuracy, latency, and resource consumption.
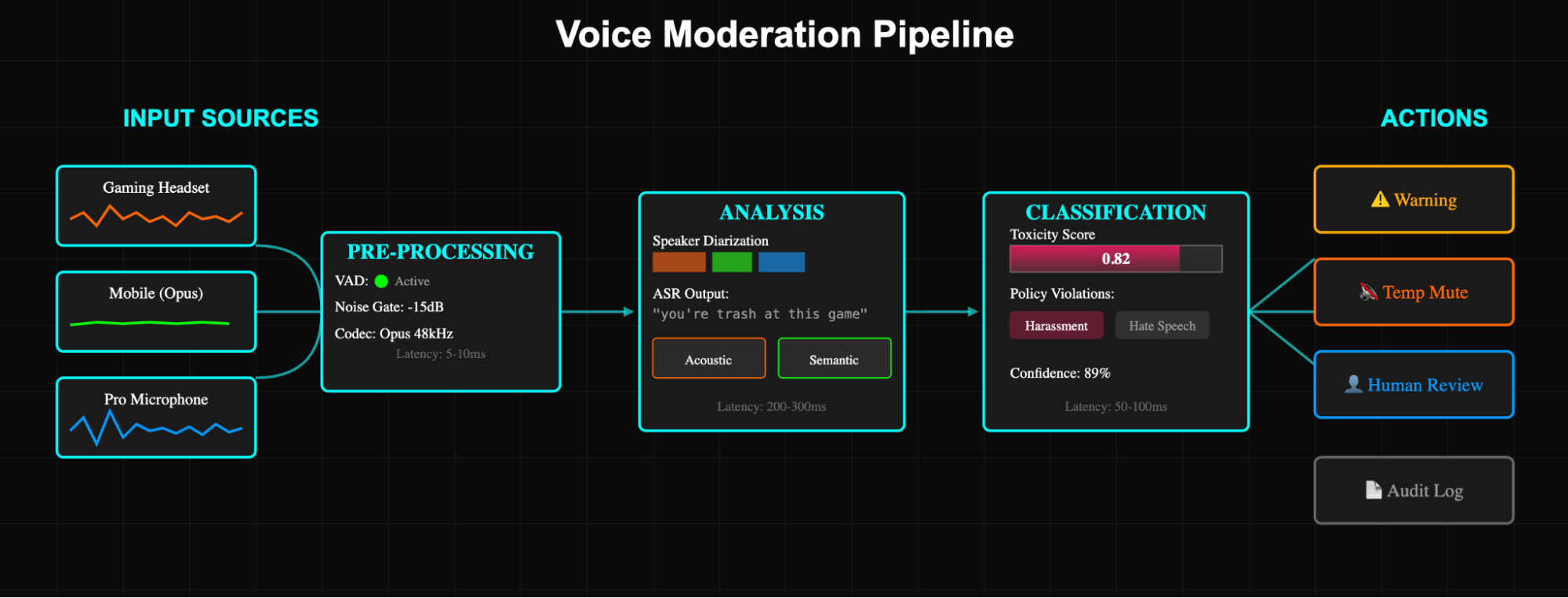
Capture & Pre-Processing
The pipeline begins the moment audio enters the system. Platforms must handle diverse input sources, including WebRTC streams at 48 kHz, mobile clients sending Opus-encoded packets, and legacy systems using G.711. Each format requires specific handling.
-
Voice Activity Detection (VAD) acts as the first filter. Modern VAD implementations use lightweight neural networks (typically 2-3 MB models) that run every 10-30ms frame. WebRTC's VAD achieves sub-millisecond processing but suffers from false positives in noisy environments.
-
Codec selection impacts everything downstream. Opus at 24 kbps preserves enough spectral detail for emotion detection while minimizing bandwidth. Some platforms transcode to PCM for processing, adding 5-10ms latency but simplifying the pipeline.
-
Noise gating removes background hum and static before analysis. Spectral subtraction techniques estimate noise profiles during silence and then remove those frequencies from the speech segments. Advanced pipelines use learned noise models that adapt to each user's environment, crucial for mobile gaming, where background conditions change constantly.
Speaker Separation & Attribution
Multi-speaker scenarios dominate real-world voice platforms. Diarisation systems must determine who said what, even when speakers overlap.
Modern approaches use embedding-based clustering. Each audio frame generates a vector (typically 256-512 dimensions) representing speaker characteristics. ECAPA-TDNN models achieve 95%+ accuracy on clean audio but degrade to 70% with gaming headset quality. Platforms often combine multiple techniques:
-
Energy-based segmentation: Detect speaker changes through volume/pitch shifts
-
Neural embeddings: Create speaker fingerprints robust to emotion changes
-
Attention mechanisms: Track conversation dynamics and turn-taking patterns
Real-time constraints force compromises. Offline diarisation may use 5-second windows for optimal accuracy, but live systems work with 500ms chunks, accepting a 10-15% accuracy loss for a 10x latency reduction.
Attribution accuracy becomes critical for enforcement. False attribution creates user trust disasters. Production systems maintain confidence scores per utterance, only taking automated action above 90% confidence thresholds.
Speech-to-Text: Latency, Accuracy, Multilingual Support
ASR forms the backbone of most moderation pipelines, though end-to-end approaches are emerging.
Latency optimization requires streaming ASR that processes audio incrementally. Modern implementations use:
-
Chunked attention: Process 200-400ms segments with 50ms lookahead
-
Partial hypothesis emission: Output words as soon as confidence exceeds thresholds
-
Speculative decoding: Predict likely continuations to reduce perceived latency
Production systems achieve 300-500ms end-to-end latency (audio in to text out) using optimized ONNX or TensorRT models on GPU infrastructure.
Accuracy varies dramatically by scenario:
-
Clean audio, native speakers: 2-3% WER (Word Error Rate)
-
Gaming headsets, casual speech: 15-25% WER
-
Heavy accents, code-switching: 30-40% WER
-
Overlapping speakers, background music: 40-50% WER
Multilingual support multiplies complexity. Unified models like Whisper handle 99 languages but require 3-10x more compute than language-specific models. Production deployments often use:
-
Language identification: Route to specialized models after detecting language
-
Multilingual embeddings: Share representations across related languages
-
Zero-shot transfer: Apply English-trained safety models to other languages via multilingual embeddings
Code-switching breaks traditional approaches. Users mixing English, Spanish, and Korean in one sentence require models trained on actual multilingual conversation data, not just monolingual datasets combined.
Toxicity & Policy Classification Approaches
Classification layers determine the types of policy violations present in the audio. Modern systems combine multiple approaches.
Keyword/Regex Baselines
Despite ML advances, deterministic rules remain essential. Platforms maintain:
-
Blocklists: 10K-100K terms including slurs, variations, and leetspeak
-
Contextual patterns: Regex that considers surrounding words ("kill" + "myself" vs "kill" + "boss")
-
Phonetic matching: Soundex/Metaphone algorithms catching pronunciation-based evasion
Keyword systems achieve near-zero false negatives for known slurs but suffer from context blindness. They serve as high-precision filters feeding into ML layers.
Supervised Acoustic-Plus-Semantic Models
Joint models analyze both the content and how it was expressed. Architecture typically involves:
-
Acoustic branch: CNN/RNN processing mel-spectrograms for prosodic features
-
Semantic branch: BERT-style transformers processing ASR output
-
Fusion layer: Attention mechanisms combining both signals
-
Multi-task heads: Separate outputs for toxicity, emotion, and speaker intent
Training requires carefully labeled datasets with both audio and transcripts. Platforms like Perspective API provide text toxicity scores, while acoustic labels are derived from human annotations of emotion and aggression levels.
Production models achieve 85-90% F1 on held-out test sets but degrade 10-20% on novel slang or emerging harassment patterns.
LLM+RAG Policy Reasoning
Latest systems use Large Language Models for nuanced policy decisions. The architecture:
-
Context retrieval: RAG systems fetch relevant policy documents, past choices, and cultural context
-
Prompt engineering: Structure queries with transcript, acoustic features, and conversation history
-
Policy reasoning: LLM evaluates against specific platform rules
-
Explanation generation: Produce human-readable justifications for decisions
LLM approaches excel at context understanding but add 500-2000ms latency and $0.001-0.01 per evaluation cost.
Scoring, Thresholds & Routing
Raw model outputs need calibration before triggering enforcement actions. A toxicity score of 0.7 means different things in different contexts.
Composite scoring combines multiple signals into unified risk scores. Text toxicity might contribute 40% of the final score, acoustic aggression 30%, and user history another 30%. So aggressive shouting (0.9) with mild text (0.7) from a repeat offender (0.5) yields a final score of 0.7. High enough for review but not automatic action.
Dynamic thresholds adapt to context. New users get lower thresholds to prevent toxic first experiences. Competitive gaming modes raise thresholds to allow passionate reactions. Youth spaces drop sexual content thresholds to near zero. The same 0.7 score triggers automatic muting in a kids' space, but just logging in adult competitive matches.
Intelligent routing ensures human reviewers focus on borderline cases:
-
Scores above 0.9: Automatic enforcement
-
0.7-0.9: Priority human review
-
0.5-0.7: Standard review queue
-
Below 0.5: Log only for pattern analysis
This tiered approach handles volume while preserving human judgment for nuanced decisions.
Human Review Loops and Enforcement Actions
Automation handles volume, but humans provide crucial judgment for edge cases.
Review interfaces must present everything moderators need at a glance: audio playback with visual waveforms showing volume spikes, ASR transcripts with confidence scores highlighted (low-confidence words in red), and model predictions explained in plain language. Moderators have access to the full conversation flow and user history, including previous violations, account age, and recent behavioral patterns. Quick action buttons for common decisions (approve, warn, mute, escalate) keep review times under 30 seconds per case.
Quality assurance prevents drift and bias. Every moderator has 5-10% of their decisions silently reviewed by another moderator. When reviewers disagree, cases are escalated to senior moderators, who determine the correct call and update training materials.
Enforcement follows predictable escalation.
-
Warning: System message about policy violation
-
Temporary mute: 5 minutes to 24 hours
-
Channel ban: Removed from the specific voice room
-
Feature restriction: Voice chat disabled, text only
-
Account suspension: Temporary platform ban
-
Permanent ban: Account termination
Designing an Audio and Voice Moderation Policy
Effective audio moderation begins with clear, comprehensive policies that strike a balance between user safety and freedom of expression. These policies must translate abstract principles into concrete technical implementations while remaining flexible enough to handle edge cases and cultural variations.
Creating a Hierarchical Taxonomy of Violations
A well-structured violation taxonomy serves as the foundation for consistent moderation decisions.
Start with four top-level categories:
-
Safety Threats: Immediate harm to users or platform integrity
-
Targeted Harm: Attacks on individuals or groups
-
Behavioral Violations: Disruptive but non-harmful actions
-
Content Violations: Inappropriate material without direct targets
Each branch has specific violations. Under Targeted Harm, for instance, you'll find identity-based attacks where users mock accents or deploy slurs. Personal harassment includes sustained verbal abuse, doxxing threats spoken aloud, or sexual harassment through unwanted advances or suggestive sounds. Coordinated harassment occurs when multiple users target a single individual, exchanging insults or taking turns with verbal attacks.
Voice creates unique violations that text platforms never face. Acoustic harassment weaponizes sound itself: ear-piercing screams, deliberate feedback loops, or playing high-frequency tones to cause physical discomfort. Voice masking allows bad actors to evade bans by disguising their real voices with modulators. Hot mic violations broadcast private conversations accidentally, catching everything from family arguments to credit card numbers being read aloud.
Defining Severity Levels and Enforcement Matrices
Critical violations demand immediate permanent suspension. Death threats, CSAM discussion, and terrorism planning fall here. High-confidence automated systems execute bans instantly, with human verification only after the action. Full audio gets preserved for law enforcement. No appeals, no exceptions.
Severe violations trigger escalating suspensions. First-time sustained hate speech draws 7 days. Second offense: 30 days. Third strike means permanent ban. Doxxing and severe harassment follow similar progressions but might skip steps based on egregiousness. These cases receive expedited human review within one hour, which should be both fast enough to prevent harm and careful enough to ensure accuracy.
The middle tiers handle daily moderation volume:
| Severity | Examples | First Action | Review Time |
|---|---|---|---|
| High | Single slur, mild threats | 24hr-7day ban | 4-24 hours |
| Medium | Profanity in family spaces | Warning-24hr mute | Automated |
| Low | Background music, hot mic | Warning only | User reports |
Context changes everything. Hate speech targeting minors skips straight to a permanent ban. Acoustic harassment that could damage hearing escalates faster than verbal toxicity. Professional esports matches may tolerate competitive trash talk that would be considered a violation of policies in casual spaces.
Multilingual & Cultural Nuance Considerations
A French person saying "Phoque" could just be talking about seals, but to English ears, it could sound like something else entirely.
This exemplifies why voice moderation can't use simple keyword lists across languages. What constitutes a severe slur in one language might be mild profanity or someone's actual name in another. Religious phrases create particular minefields. "Goddamn" barely registers in secular American contexts but deeply offends in religious communities. Conversely, phrases that sound innocent to English speakers might constitute severe blasphemy in Arabic or Hindi.
Cultural communication patterns vary dramatically. Mediterranean cultures often express passion through volume and rapid speech, which algorithms might flag as aggression. East Asian communication styles usually emphasize silence and indirect expression, making sarcasm and criticism more challenging to detect. Some cultures treat interruption as engaged discussion; others consider it profoundly disrespectful.
Platforms must layer policies geographically. The EU requires stricter standards for hate speech than the US First Amendment allows. MENA regions need blasphemy considerations. Asian markets value honorifics and age-based respect. When users from the different areas interact, systems typically apply the most restrictive combination to ensure all participants feel safe.
Implementation requires:
-
Native speaker advisory boards reviewing edge cases
-
Regional moderation teams understanding local slang evolution
-
Dynamic policy loading based on user location and room context
-
Clear UI indicators when entering cross-cultural spaces
Code-switching complicates everything further. A conversation might flow between English, Spanish, and Tagalog in a single sentence, with different severity standards for similar concepts in each language.
Appeals, Transparency, and User Education
Users need to understand precisely why they were moderated.
Notifications must include the specific policy violated, the timestamp, and a transcript excerpt, never the full audio for privacy reasons. Clearly display the severity level, resulting action, and appeals deadline. Avoid legalese. "You received a 24-hour voice ban for harassment (Section 3.2.1)" tells users nothing. "You were voice-banned for 24 hours because you repeatedly called another player offensive names after they asked you to stop," explains the actual problem.
The appeals process should feel accessible, not bureaucratic. Let users explain context through structured forms: "This was banter between friends" or "The ASR misheard my accent." Route appeals to different moderators than the initial reviewer, ensuring a fresh perspective. Match cultural and linguistic expertise to the content. Gaming slang needs gaming-literate reviewers. Regional content needs native speakers. Set clear SLAs:
-
Critical severity: No appeals allowed
-
Severe: 24-hour response
-
High: 72-hour response
-
Medium/Low: 7-day response
Transparency builds trust. Publish quarterly reports showing total voice minutes moderated, violation breakdowns, enforcement statistics, and crucially, appeals success rates by language and region. If Spanish speakers are successfully appealed 50% more often than English speakers, that signals policy or detection problems that need attention.
The goal isn't perfect policies; those don't exist. It's creating systems transparent enough for users to understand, flexible enough to handle nuance, and responsive enough to improve based on community needs.
Audio and Voice Moderation Implementation Best Practices
-
Define a Clear, Hierarchical Policy Taxonomy. ML models need consistent labels. Structure violations hierarchically. This lets you tune enforcement granularly and tighten specific policies without affecting all spaces.
-
Start with Representative Audio Corpora. Generic training data fails in production. Capture platform-specific language: gaming slang, regional accents, in-jokes. Establish baselines before launch.
-
Layer AI + Human Review. AI handles volume, humans handle nuance. Route by confidence:
a. >95% confidence: "I'm certain this is hate speech." Automatically mute the user. b. 70-95% confidence: "This seems like harassment, but I'm not sure." Send to a human moderator immediately. c. 40-70% confidence: "This might be problematic." Collect these for moderators to review in batches later. d. <40% confidence: "I have no idea what this is." Don't take any action, just save it to improve the AI model. -
Implement Adaptive Thresholds. Static thresholds frustrate users. Youth sports leagues need low profanity thresholds. Adult horror games can handle higher thresholds. Let community managers adjust without code changes.
-
Track the Right Metrics. Monitor toxic utterances per 1,000 minutes, automated catch rates, and appeals by language. Set alerts so you can detect if, for example, spiking false-positives signals model drift.
-
Design for Transparency. Log decisions, not content. Store audio hashes and policy violations, never full transcripts. Auto-expire after 90 days. Publish quarterly safety reports.
-
Build Robust Appeals Workflows. Make appeals easy. Show users exactly what triggered the action. Route to different moderators than the initial reviewers. Track overturn rates by policy and region.
-
Test Before Deploying. Run shadow mode for 30 days. Compare automated decisions to human judgments without taking action. Identify failure modes before they impact users.
-
Handle Language Detection Gracefully. Don't assume English. Run language ID before ASR. Route to appropriate models. Fall back to acoustic-only analysis when languages aren't supported.
-
Create Feedback Loops. Successful appeals become training data. User reports highlight model blind spots. Survey power users quarterly. Iterate based on actual usage patterns.
Becoming the Voice for Moderation
Voice chat has become the beating heart of online communities, from late-night gaming sessions to remote team meetings. But as we've seen, it's also where some of the worst behavior happens. The technology to fix this exists, and it's getting better every day.
The best audio and voice moderation combines intelligent automation with human judgment. Let the machines catch the obvious cases, save human reviewers for the more complex ones, and always provide users with a fair appeals process. Most importantly, adapt your approach to your community's needs. What works for a competitive FPS won't work for a meditation app.
With the right tools, you can focus on what matters most: your users.