

Earlier this year, payment service Klarna launched an AI customer service assistant. Within the first month, this AI had 2.3 million conversations, the equivalent of 700 agents, and led to a 25% drop in repeated inquiries. Klarna estimated it would “drive $40 million USD in profit improvement” in 2024.
Customer success is an ideal opportunity for AI chatbots. Customers usually want quick, simple conversations within a bounded domain with clear goals. Human interaction can be a fallback for the customers who need more.
So let’s build precisely that.
Picking Your Model
Klarna used OpenAI to build their AI assistant. At the time, this was the leading model. But AI has advanced so dramatically in the past few months that the " best " choice is no longer so clear.
For one, you have the broad choice of proprietary models vs open source models. Proprietary models–OpenAI, Anthropic’s Claude, or Google’s Gemini, have the advantage that they are hosted with robust infrastructure behind them and are constantly iterating on more features. They have good developer experience, and you should be able to get up and running with one of these models in just a few minutes.
The obvious downside here is cost. You’re paying for that infrastructure, and while costs for these models continue to decline, they are still more expensive than using open-source models.
So, about those open-source models. Models like Llama 3 and Mixtral have made huge strides in capability while being free to run on your own infrastructure. While they require more technical expertise to deploy and maintain, they can be a cost-effective choice for companies with the engineering resources to handle hosting and fine-tuning.
Here, we’re going to follow the Klarna route and use OpenAI. The reasons are that this is the easiest of all the models to set up, and it has two functionalities we really want for our chatbot fine-tuning and embeddings.
Preparing Your Model
How do you build this? Well, you can just plug in an off-the-shelf AI model and use that to interact with your customers. However, these models can only ever give generic answers, and customer success is precisely where you want to provide specific answers. Thus, we want to create a model that is geared more towards our customers.
We can use two techniques to improve AI models: fine-tuning and retrieval-augmented generation.
Fine-tuning
Fine-tuning is the process of further training an AI model on your specific data to make it better at your particular use case. By feeding it examples of good customer service interactions from your company, you can teach the model your brand voice, common customer issues, and preferred solutions. This additional training helps the model give more accurate and on-brand responses than it would with its generic training alone.
We’re able to do that by taking a generic GPT model and running the OpenAI fine-tuning process. First, we need to get our data into the right format, JSONL, where each line is a valid JSON object containing our training examples.
123456789101112131415161718192021222324252627282930313233import csv import json def csv_to_jsonl(input_csv, output_jsonl): with open(input_csv, 'r', encoding='utf-8') as csv_file, open(output_jsonl, 'w', encoding='utf-8') as jsonl_file: reader = csv.DictReader(csv_file) for row in reader: # Create the messages array with the system message and conversation flow messages = [ { "role": "system", "content": "You are a helpful customer support assistant." }, { "role": "user", "content": row['instruction'] }, { "role": "assistant", "content": row['response'], "weight": 1 } ] # Create the JSON object with the messages array json_obj = { "messages": messages } # Write the JSON object as a line in the JSONL file jsonl_file.write(json.dumps(json_obj) + '\n') csv_to_jsonl('customer_support_training_dataset.csv','training_data.jsonl')
This converts our customer support training data from CSV format into the JSONL format that OpenAI's fine-tuning API expects. Each row in our CSV creates a conversation flow with a system message defining the assistant's role, the customer's question (instruction), and the ideal response, with each conversation being written as a separate line in the output file.
Here, we’re using the Bitest customer support dataset, so we get an output like this:
1234567891011{"messages": [ {"role": "system", "content": "You are a helpful customer support assistant."}, {"role": "user", "content": "question about cancelling order {{Order Number}}"}, {"role": "assistant", "content": "I've understood you have a question regarding canceling order {{Order Number}}, and I'm here to provide you with the information you need. Please go ahead and ask your question, and I'll do my best to assist you.", "weight": 1} ]} {"messages": [ {"role": "system", "content": "You are a helpful customer support assistant."}, {"role": "user", "content": "i have a question about cancelling oorder {{Order Number}}"}, {"role": "assistant", "content": "I've been informed that you have a question about canceling order {{Order Number}}. I'm here to assist you! Please go ahead and let me know what specific question you have, and I'll provide you with all the information and guidance you need. Your satisfaction is my top priority.", "weight": 1} ]}
With that, we can then run our fine-tuning process. First, we need to install the only dependency, openai:
pip install openaiThen, we have our script for fine-tuning. You’ll need an OpenAI API key:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152import time from openai import OpenAI import os # Initialize the OpenAI client client = OpenAI(api_key=os.getenv('OPENAI_API_KEY')) response = client.files.create( file=open("training_data.jsonl", "rb"), purpose="fine-tune" ) print(response) # Extract the file ID training_file_id = response.id print(f"Uploaded file ID: {training_file_id}") # Create a fine-tuning job fine_tune_response = client.fine_tuning.jobs.create( training_file=training_file_id, model="gpt-4o-mini-2024-07-18" # Specify the base model to fine-tune ) # Extract the fine-tuning job ID fine_tune_job_id = fine_tune_response.id print(f"Fine-tuning job ID: {fine_tune_job_id}") # Check the status of the fine-tuning job while True: status_response = client.fine_tuning.jobs.retrieve(fine_tune_job_id) status = status_response.status print(f"Fine-tuning job status: {status}") if status in ['succeeded', 'failed']: break time.sleep(60) # Wait for 60 seconds before checking again # Retrieve the fine-tuned model ID fine_tuned_model_id = status_response.fine_tuned_model print(f"Fine-tuned model ID: {fine_tuned_model_id}") # Use the fine-tuned model completion = client.chat.completions.create( model=fine_tuned_model_id,# messages=[ {"role": "system", "content": "You are a helpful customer support assistant."}, {"role": "user", "content": "Help me with my order"} ], max_tokens=100 ) # Print the generated completion print(completion.choices[0].message.content)
This takes our prepared JSONL training data and runs it through OpenAI's fine-tuning process. First, we upload our training file to OpenAI's servers and get back a file ID. Then, we create a fine-tuning job using that file ID and specify our base model (in this case, gpt-4o-mini-2024-07-18).
The script continuously monitors the fine-tuning job until it is complete; at this point, we get our fine-tuned model ID. Finally, we test our new model by sending it a sample customer support question. The output will look something like this:
Uploaded file ID: file-A7WrnKWEJKsTitbi5BNNgA
Fine-tuning job ID: ftjob-ja5GpNup23S5qkjsBswA6kT7
Fine-tuning job status: validating_files
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: running
Fine-tuning job status: succeeded
Fine-tuned model ID: ft:gpt-4o-mini-2024-07-18:argot::AXEhwFH8
Of course, I'm here to help! Please provide me with the details of your order, such as your order number, the problem you're facing, or any specific questions you have. I'll do my best to assist you from there.We need just our fine-tuned model ID from here–this is what we’ll use in our app instead of a generic OpenAI model.
Retrieval-Augmented Generation
Retrieval-augmented generation is a technique that combines the power of LLMs with a knowledge base of specific information. Instead of relying solely on the model's training data, RAG allows us to feed in relevant context from our own documentation, FAQs, or knowledge base at query time. This means our responses can include up-to-date, company-specific information while maintaining the model's natural language capabilities.
We'll use OpenAI again for this, but this time, we will generate embeddings. Embeddings are numerical representations of text that capture its semantic meaning, allowing us to measure how similar different pieces of text are to each other.
These embeddings will be stored in a vector database specifically designed to efficiently store and search through these high-dimensional numerical representations of text. Unlike traditional databases that excel at exact matches, vector databases can find content that is semantically similar even if the wording is different.
Here, we’re using Pinecone. All we’ll need is an API key that will allow us to generate an index and store our vectors. We’ll need to install the Pinecone library along with a PDF parser.
pip install pinecone pypdf2We’ll create the embeddings from a PDF of some Stream documentation:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170import os from openai import OpenAI import pinecone import time from typing import List, Dict import PyPDF2 from pathlib import Path import re from pinecone import Pinecone, ServerlessSpec class PDFEmbeddingSystem: def __init__(self, openai_api_key: str, pinecone_api_key: str, pinecone_environment: str, index_name: str): """ Initialize the embedding system with necessary API keys and configuration. """ # Initialize OpenAI client self.client = OpenAI(api_key=openai_api_key) # Initialize Pinecone self.pc = Pinecone(api_key=pinecone_api_key) # Create or connect to Pinecone index if index_name not in self.pc.list_indexes().names(): self.pc.create_index( name=index_name, dimension=1536, # dimensionality of text-embedding-ada-002 metric='cosine', spec=ServerlessSpec(cloud='aws', region='us-east-1') ) self.index = self.pc.Index(index_name) def extract_text_from_pdf(self, pdf_path: str) -> Dict[int, str]: """ Extract text from PDF file, maintaining page structure. Returns a dictionary with page numbers as keys and text content as values. """ pdf_text = {} try: with open(pdf_path, 'rb') as file: pdf_reader = PyPDF2.PdfReader(file) for page_num in range(len(pdf_reader.pages)): page = pdf_reader.pages[page_num] text = page.extract_text() # Clean the extracted text text = self.clean_text(text) if text.strip(): # Only store non-empty pages pdf_text[page_num + 1] = text return pdf_text except Exception as e: raise Exception(f"Error extracting text from PDF: {str(e)}") def clean_text(self, text: str) -> str: """ Clean and normalize extracted text. """ # Remove multiple spaces text = re.sub(r'\s+', ' ', text) # Remove multiple newlines text = re.sub(r'\n+', '\n', text) # Remove special characters but keep basic punctuation text = re.sub(r'[^\w\s.,!?-]', '', text) return text.strip() def chunk_text(self, text: str, chunk_size: int = 1000) -> List[str]: """ Split text into smaller chunks for processing. Tries to break at sentence boundaries when possible. """ # First split by sentences sentences = re.split(r'(?<=[.!?])\s+', text) chunks = [] current_chunk = "" for sentence in sentences: if len(current_chunk) + len(sentence) < chunk_size: current_chunk += " " + sentence if current_chunk else sentence else: if current_chunk: chunks.append(current_chunk.strip()) current_chunk = sentence if current_chunk: chunks.append(current_chunk.strip()) return chunks def create_embedding(self, text: str) -> List[float]: """ Create embedding for a single piece of text using OpenAI. """ response = self.client.embeddings.create( input=text, model="text-embedding-ada-002" ) return response.data[0].embedding def process_pdf(self, pdf_path: str, additional_metadata: Dict = None) -> None: """ Process a PDF file: extract text, chunk it, create embeddings, and store in Pinecone. """ # Extract text from PDF pdf_text = self.extract_text_from_pdf(pdf_path) # Get PDF filename for metadata pdf_name = Path(pdf_path).name for page_num, page_text in pdf_text.items(): chunks = self.chunk_text(page_text) for i, chunk in enumerate(chunks): # Create embedding embedding = self.create_embedding(chunk) # Prepare metadata chunk_metadata = { 'text': chunk, 'pdf_name': pdf_name, 'page_number': page_num, 'chunk_index': i, 'total_chunks_in_page': len(chunks) } if additional_metadata: chunk_metadata.update(additional_metadata) # Store in Pinecone self.index.upsert( vectors=[{ 'id': f'{pdf_name}_p{page_num}_chunk_{i}', 'values': embedding, 'metadata': chunk_metadata }] ) # Rate limiting to avoid API throttling time.sleep(0.5) def query_similar(self, query: str, top_k: int = 3, filter_dict: Dict = None) -> List[Dict]: """ Query Pinecone for similar text chunks using a query string. Optionally filter results based on metadata. """ query_embedding = self.create_embedding(query) results = self.index.query( vector=query_embedding, top_k=top_k, include_metadata=True, filter=filter_dict ) return results['matches'] # Example usage if __name__ == "__main__": # Initialize the system embedder = PDFEmbeddingSystem( openai_api_key="openai_api_key", pinecone_api_key="pinecone_api_key", pinecone_environment="us-east-1", index_name="cs-chat" ) # Process a PDF file embedder.process_pdf( pdf_path="MessageInputContext.pdf", )
We create a PDFEmbeddingSystem class that handles the entire RAG pipeline. This initializes connections to OpenAI (for embeddings) and Pinecone (for vector storage), creates a new vector index if one doesn't exist, configured for OpenAI's embedding dimensions, and extracts and processes text from PDF documents.
It includes several methods for processing:
- extract_text_from_pdf: Pulls text content from PDFs while preserving page structure
- clean_text: Normalizes the extracted text by removing excess spaces and special characters
- chunk_text: Breaks down long text into smaller, sentence-aware chunks (defaulting to 1000 characters)
- create_embedding: Generates embeddings using OpenAI's text-embedding-ada-002 model
The process_pdf method ties everything together. It extracts text from the PDF, chunks it into manageable pieces, creates embeddings for each chunk, and then stores each embedding in Pinecone with metadata about its source and location.
With our fine-tuned OpenAI model and our Pinecone embeddings, we’re ready to build out our AI Chatbot that leverages this information.
Building Our Chat App
We’re going to build our chat app using Next.js. To create a bare-bones app, you can use:
npx create-next-app@latestThis will take you through a series of questions to set up your app. Once completed, enter the generated project and add the dependencies we need:
npm install stream-chat stream-chat-react openai @pinecone-database/pineconeWe’re using Stream Chat to handle the chat part of our chat application and a combination of OpenAI and Pinecone for the AI component. For all of these, we’ll need API keys and other information that we’ll store in a .env file:
// .env.local
NEXT_PUBLIC_STREAM_KEY=
STREAM_SECRET=
OPENAI_API_KEY=
PINECONE_API_KEY=
PINECONE_ENVIRONMENT=
PINECONE_INDEX=
Now, we can start to add our code. We’ll start with the main page:
123456// app/page.js import ChatComponent from './components/ChatComponent'; export default function Home() { return <ChatComponent />; }
Not a lot to it. We want to use components within our code as much as possible for better code organization, reusability, and easier state management across our application.
When we look at ChatComponent, we can see what is happening:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196197198199200201202203204205206207208209210211212213214215216217218219220221222223224225226227228// app/components/ChatComponent.jsx 'use client'; import { useState, useEffect } from 'react'; import { Channel, ChannelHeader, MessageList, MessageInput, Window, useChannelStateContext, } from 'stream-chat-react'; import { StreamChat } from 'stream-chat'; const chatClient = StreamChat.getInstance(process.env.NEXT_PUBLIC_STREAM_KEY); // Phrases that trigger escalation to human support const ESCALATION_TRIGGERS = [ 'talk to a human', 'speak to a person', 'talk to someone', 'talk to a person', 'speak to a human', 'this hasn\'t helped', 'this is not helping', 'need human assistance', 'human support', 'real person', ]; // Custom MessageInput component to handle AI responses and escalation const CustomMessageInput = () => { const { channel } = useChannelStateContext(); const [isEscalated, setIsEscalated] = useState(false); const [waitingForHuman, setWaitingForHuman] = useState(false); const checkForEscalation = (message) => { return ESCALATION_TRIGGERS.some(trigger => message.toLowerCase().includes(trigger.toLowerCase()) ); }; const escalateToHuman = async () => { setWaitingForHuman(true); try { // Add human support agent to channel await channel.addMembers(['human-agent']); // Send system message about escalation await channel.sendMessage({ text: "This conversation has been escalated to human support. A support agent will join shortly.", user: { id: 'system', name: 'System', }, type: 'system', }); // Update channel data to mark as escalated await channel.update({ escalated: true, escalated_at: new Date().toISOString(), }); setIsEscalated(true); } catch (error) { console.error('Error escalating to human support:', error); await channel.sendMessage({ text: "I'm sorry, there was an error connecting you with human support. Please try again.", user: { id: 'system', name: 'System', }, }); } finally { setWaitingForHuman(false); } }; const handleSubmit = async (message) => { try { // First send the user's message const userMessage = await channel.sendMessage({ text: message.text, }); // Check if message should trigger escalation if (!isEscalated && checkForEscalation(message.text)) { await escalateToHuman(); return; } // If already escalated, don't send to AI if (isEscalated) return; // Show typing indicator for AI await channel.sendEvent({ type: 'typing.start', user: { id: 'ai-assistant' }, }); // Send message to OpenAI const response = await fetch('/api/openai', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ message: message.text }), }); const data = await response.json(); // Stop typing indicator await channel.sendEvent({ type: 'typing.stop', user: { id: 'ai-assistant' }, }); // Send AI response await channel.sendMessage({ text: data.response, user: { id: 'ai-assistant', name: 'AI Support', }, }); } catch (error) { console.error('Error handling message:', error); await channel.sendMessage({ text: "I'm sorry, I encountered an error processing your request.", user: { id: 'ai-assistant', name: 'AI Support', }, }); } }; return ( <div className="relative"> {waitingForHuman && ( <div className="absolute top-0 left-0 right-0 bg-yellow-100 p-2 text-center text-sm"> Connecting you with a human support agent... </div> )} <MessageInput overrideSubmitHandler={handleSubmit} disabled={waitingForHuman} /> </div> ); }; export default function ChatComponent() { const [channel, setChannel] = useState(null); const [clientReady, setClientReady] = useState(false); const userId = 'user-' + Math.random().toString(36).substring(7); useEffect(() => { async function initializeChat() { try { // Get token from our API const response = await fetch('/api/auth', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ userId }), }); const { token } = await response.json(); // Connect user await chatClient.connectUser( { id: userId, name: 'User', }, token ); // Create or join support channel const channel = chatClient.channel('messaging', 'support', { name: 'Customer Support', members: [userId, 'ai-assistant'], escalated: false, }); await channel.watch(); setChannel(channel); // Watch for human agent joining channel.on('member.added', event => { if (event.user.id === 'human-agent') { channel.sendMessage({ text: "Human support agent has joined the conversation.", user: { id: 'system', name: 'System', }, type: 'system', }); } }); setClientReady(true); } catch (error) { console.error('Error initializing chat:', error); } } initializeChat(); return () => { if (clientReady) { chatClient.disconnectUser(); } }; }, []); if (!channel || !clientReady) return <div>Loading...</div>; return ( <div className="h-screen"> <Channel channel={channel}> <Window> <ChannelHeader /> <MessageList /> <CustomMessageInput /> </Window> </Channel> </div> ); }
The component initializes a Stream chat client with a unique ID for each user and creates a dedicated support channel that includes both the user and our AI assistant. The CustomMessageInput component handles the core logic of our chatbot, intercepting messages before they're sent to determine if they need AI processing or human escalation.
When a user sends a message, it first checks against our escalation triggers–phrases like "talk to a human" or "need human assistance"--and, if matched, transitions the conversation to human support by adding a support agent to the channel (we see this from the agents POV later).
For non-escalated conversations, messages are sent to our OpenAI endpoint, which combines our fine-tuned model with the relevant context from our Pinecone vector database to generate appropriate responses.
Before we get to that endpoint, let’s look first at the auth route:
1234567891011121314151617181920212223242526272829303132// app/api/auth/route.js import { StreamChat } from 'stream-chat'; import { NextResponse } from 'next/server'; const serverClient = StreamChat.getInstance( process.env.NEXT_PUBLIC_STREAM_KEY, process.env.STREAM_SECRET ); export async function POST(request) { const { userId } = await request.json(); await serverClient.upsertUser({ id: userId, role: 'admin', }); await serverClient.upsertUser({ id: 'ai-assistant', name: 'AI Support', role: 'user', }); try { const token = serverClient.createToken(userId); return NextResponse.json({ token }); } catch (error) { return NextResponse.json( { error: 'Error generating token' }, { status: 500 } ); } }
This route handles user authentication for our chat system using Stream's server-side functionality. It creates or updates two users, the current customer and our AI assistant, ensuring both have the appropriate roles in the system. The endpoint then generates a Stream token for the user, which is necessary to establish a secure chat service connection.
Now let’s go through the openai endpoint:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253// app/api/openai/route.js import { OpenAI } from 'openai'; import { NextResponse } from 'next/server'; import { PineconeSystem } from '../../lib/PineconeSystem'; const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); export async function POST(request) { const { message } = await request.json(); try { const pinecone = new PineconeSystem( process.env.OPENAI_API_KEY, process.env.PINECONE_API_KEY, process.env.PINECONE_INDEX ); // Query similar content using the message text directly const similarContent = await pinecone.querySimilar(message, 3); // Construct context from relevant passages const context = similarContent .map(match => match.metadata.text) .join('\n'); // Generate completion with context const completion = await openai.chat.completions.create({ model: "ft:gpt-4o-mini-2024-07-18:argot::AXEhwFH8", temperature: 0.7, messages: [ { role: "system", content: "You are a helpful customer support assistant. Answer the question as best as possible using the provided context. If the context doesn't contain relevant information, use your general knowledge. Be concise and accurate." }, { role: "user", content: `Context: ${context}\n\nQuestion: ${message}` } ] }); const aiResponse = completion.choices[0].message.content; return NextResponse.json({ response: aiResponse }); } catch (error) { console.error('Error in OpenAI route:', error); return NextResponse.json( { error: 'Error generating AI response' }, { status: 500 } ); } }
The OpenAI endpoint serves as the brain of our chatbot, combining our fine-tuned model with contextual information from our knowledge base. When a message arrives, it first queries Pinecone to find relevant documentation that matches the user's question. The system then constructs a prompt that includes both the retrieved context and the user's message, sending this to our fine-tuned GPT model for processing.
We use a temperature of 0.7 to balance creativity and accuracy in the responses, while the system message ensures the AI maintains its role as a helpful support assistant. If anything goes wrong during this process, the endpoint handles errors gracefully and returns an appropriate error response.
The PineconeSystem handles our embeddings:
123456789101112131415161718192021222324252627282930313233343536373839import { Pinecone } from '@pinecone-database/pinecone'; import { OpenAI } from 'openai'; export class PineconeSystem { constructor(openaiApiKey, pineconeApiKey, indexName) { // Initialize OpenAI client this.openai = new OpenAI({ apiKey: openaiApiKey }); // Initialize Pinecone this.pc = new Pinecone({ apiKey: pineconeApiKey, }); this.indexName = indexName; this.index = this.pc.index(indexName); } async createEmbedding(text) { const response = await this.openai.embeddings.create({ input: text, model: "text-embedding-ada-002" }); return response.data[0].embedding; } async querySimilar(query, topK = 3, filterDict = null) { try { const queryEmbedding = await this.createEmbedding(query); const results = await this.index.query({ vector: queryEmbedding, topK, includeMetadata: true, filter: filterDict }); return results.matches; } catch (error) { throw new Error(`Error querying similar texts: ${error.message}`); } } }
The PineconeSystem class serves as our interface to the vector database, handling all embedding-related operations. It initializes connections to OpenAI (generating embeddings) and Pinecone (storing and querying them), maintaining these as instance variables for efficient reuse.
The createEmbedding method generates vector representations of text using OpenAI's text-embedding-ada-002 model. At the same time, querySimilar handles the core search functionality, taking a query string and returning the most semantically similar content from our knowledge base. This abstraction keeps our vector search logic clean and reusable across different application parts.
With this, we have an AI chatbot. Let’s ask it some questions. First, we’ll ask it something from the embedding:

Excellent answer, just what I needed. Now, we’ll ask it something more general:

Given how we have architected the system, it wants to fall back onto the context from the embeddings first but will give you the information from the fine-tuning.
Of course, no one wants to be stuck with just an AI bot when they need real help. So, we want to build the ability to escalate our problem to a human. In the ChatComponent above, we have some escalation terms that, when entered, will draw a human into the chat. So, we also need the infrastructure for a human to chat with.
First, a page for them:
123456// app/agent/page.js import AgentDashboard from './components/AgentDashboard'; export default function AgentPage() { return <AgentDashboard />; }
Again, we are using components, so the logic is within the AgentDashboard component:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180// app/agent/components/AgentDashboard.js 'use client'; import { useState, useEffect } from 'react'; import { Channel, ChannelHeader, ChannelList, Chat, MessageInput, MessageList, Window, useChannelStateContext, } from 'stream-chat-react'; import { StreamChat } from 'stream-chat'; const chatClient = StreamChat.getInstance(process.env.NEXT_PUBLIC_STREAM_KEY); const customChannelFilter = { type: 'messaging', escalated: true, }; const ChannelPreview = ({ channel, latestMessage, active }) => { const [unread, setUnread] = useState(0); useEffect(() => { const getUnread = async () => { const state = await channel.state(); setUnread(state.unreadCount); }; getUnread(); }, [channel]); return ( <div className={`p-4 border-b hover:bg-gray-50 cursor-pointer ${active ? 'bg-blue-50' : ''}`}> <div className="flex justify-between items-start"> <div className="flex-1"> <div className="flex items-center gap-2"> <span className="font-medium">User {channel.data.name}</span> {channel.data.priority === 'high' && ( <span className="bg-red-100 text-red-800 text-xs px-2 py-1 rounded"> High Priority </span> )} </div> <div className="text-sm text-gray-500 truncate"> {latestMessage} </div> </div> {unread > 0 && ( <span className="bg-blue-500 text-white text-xs px-2 py-1 rounded-full"> {unread} </span> )} </div> <div className="mt-2 text-xs text-gray-400"> Waiting: {formatWaitTime(channel.data.escalated_at)} </div> </div> ); }; const formatWaitTime = (escalatedAt) => { const minutes = Math.floor((Date.now() - new Date(escalatedAt)) / 60000); return minutes < 60 ? `${minutes}m` : `${Math.floor(minutes / 60)}h ${minutes % 60}m`; }; const CustomChannelHeader = () => { const { channel } = useChannelStateContext(); const [userWaitTime, setUserWaitTime] = useState(''); useEffect(() => { if (channel.data.escalated_at) { const interval = setInterval(() => { setUserWaitTime(formatWaitTime(channel.data.escalated_at)); }, 60000); // Update every minute return () => clearInterval(interval); } }, [channel.data.escalated_at]); return ( <div className="flex justify-between items-center p-4 border-b"> <div> <h2 className="font-medium">Conversation with User {channel.data.name}</h2> <p className="text-sm text-gray-500"> Waiting time: {userWaitTime} </p> </div> <div className="flex gap-2"> <button className="px-3 py-1 text-sm bg-green-500 text-white rounded hover:bg-green-600" onClick={() => channel.update({ status: 'resolved' })} > Resolve </button> <button className="px-3 py-1 text-sm bg-blue-500 text-white rounded hover:bg-blue-600" onClick={() => channel.update({ priority: 'high' })} > Set High Priority </button> </div> </div> ); }; export default function AgentDashboard() { const [agentClient, setAgentClient] = useState(null); useEffect(() => { async function initializeAgentChat() { try { const agentId = 'human-agent'; // In production, this should come from authentication // Get token for agent const response = await fetch('/api/auth', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ userId: agentId }), }); const { token } = await response.json(); // Connect agent await chatClient.connectUser( { id: agentId, name: 'Support Agent', role: 'agent', }, token ); setAgentClient(chatClient); } catch (error) { console.error('Error initializing agent chat:', error); } } initializeAgentChat(); return () => { if (agentClient) { agentClient.disconnectUser(); } }; }, []); if (!agentClient) return <div>Loading...</div>; return ( <div className="flex h-screen bg-gray-100"> <div className="w-96 bg-white border-r"> <div className="p-4 bg-gray-800 text-white"> <h1 className="text-xl font-semibold">Support Dashboard</h1> <div className="text-sm mt-2"> Agent: Support Team </div> </div> <ChannelList filters={customChannelFilter} sort={{ last_message_at: -1 }} Preview={ChannelPreview} /> </div> <div className="flex-1"> <Channel> <Window> <CustomChannelHeader /> <MessageList /> <MessageInput /> </Window> </Channel> </div> </div> ); }
The AgentDashboard component creates a comprehensive interface for human support agents to manage escalated conversations from our AI chatbot.
The dashboard is split into two main sections:
- A sidebar showing a list of escalated conversations (filtered by the customChannelFilter).
- The main chat window where agents can interact with users.
Each conversation in the sidebar displays essential information like the user's ID, wait time since escalation, message preview, and priority status. At the same time, the custom channel header provides agents with quick actions like setting priority levels and resolving conversations. The component handles agent authentication similarly to our user chat interface but with specific agent roles and permissions. For real-time updates, the dashboard includes features like unread message counts and wait time tracking, giving agents the context they need to effectively prioritize and manage their support queue.
So, when a user types “this is not helping,” we get an escalation:

The agent then gets all the previous message history in their dashboard, along with some vitals:
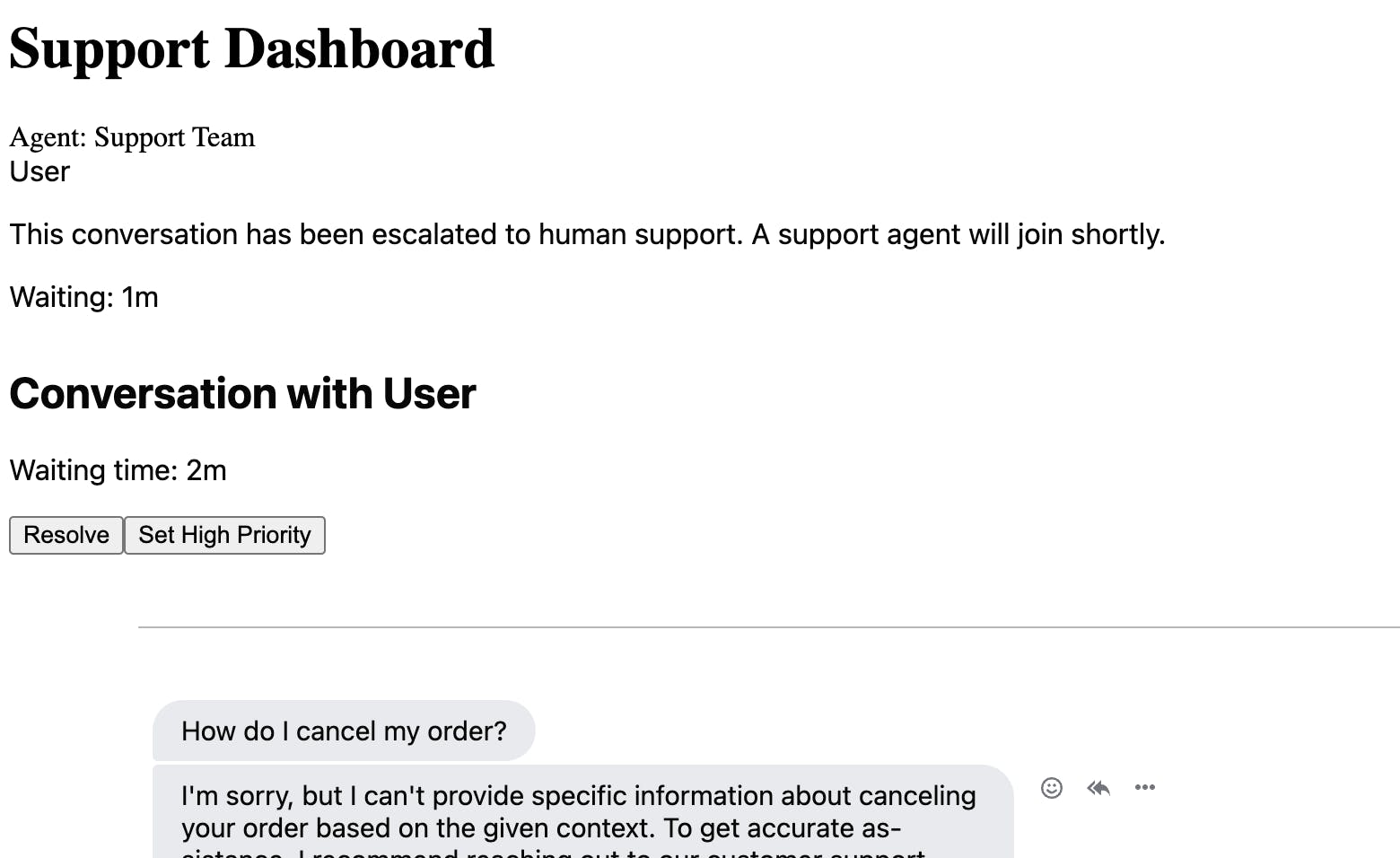
They can then reply, which shows up to the user:

And we have an AI-led but human-available customer support chatbot!
Best Practices for AI Responses
While we've built a powerful AI-driven support system, its effectiveness ultimately depends on how well we guide its responses. Here are essential practices to ensure your chatbot provides helpful, accurate, and appropriate support.
- Prompting. Our OpenAI endpoint uses a carefully crafted system message: "You are a helpful customer support assistant. Answer the question as best as possible using the provided context." This sets the foundation, but you might want to add more specific guidance like "Keep responses under three sentences unless explaining technical concepts" or "Always acknowledge the customer's concern before providing solutions." The more specific your system message, the more consistent your bot's personality will be.
- Hallucinations. Handling hallucinations—when the AI makes up information—is crucial for customer support. That's why we've implemented RAG with our documentation. But you should also include explicit instructions in your system message like "If you're not certain about something, say so and offer to escalate to a human agent" or "Only reference features and policies explicitly mentioned in the context." This prevents the AI from creating product features or policies that don't exist.
- PII. Sensitive information requires special attention. Configure your model to recognize and refuse to handle sensitive data patterns like credit card numbers, passwords, or personal identification numbers. You can add a pre-processing step in your handleSubmit function to scan for these patterns before sending them to the AI. Also, ensure your system message includes clear boundaries: "Never ask for or repeat sensitive information like passwords or payment details."
- Tone. Setting the right tone is about balancing professionalism with approachability. Our fine-tuning data teaches the model our brand voice, but we can reinforce this in the system message: "Maintain a friendly, professional tone. Use empathetic language when customers express frustration, but stay focused on solutions." Consider adding example responses in your fine-tuning data demonstrating how to handle everyday emotional situations like angry customers or urgent issues.
Finally, remember that AI responses should complement your human support team, not replace it. Use your escalation triggers strategically—if a conversation involves complex problem-solving, sensitive issues, or frustrated customers, it's often better to escalate early rather than risk degrading the customer experience with multiple AI response attempts.