

Integrating AI into enterprise applications often challenges getting accurate and efficient results from LLMs. The main reason is that LLMs are trained on large datasets rather than specifically on your enterprise's data. These challenges may usually include hallucinations, outdated information presentation, and more. This article explores the integration of AI agents, or, Agentic Retrieval Augmented Generation (RAG), and vector databases to provide effective search and improved LLM responses. We will implement a simple AI chat bot, allowing you to use vector search and an AI agent to chat with data in a PDF document.
Prerequisites
To build our sample retrieval-based agent in this tutorial, we need an API key from providers like OpenAI, Anthropic, Mistral, and xAI to access an LLM. We will use OpenAI; however, you can choose your preferred model provider. We also need a vector database for information retrieval, a Python framework to build the RAG agent, and a service to store data in documents.
- OpenAI API account: Create an OpenAI account and export your API keys to access LLMs like
gpt-4o-mini. - Vector Database: This example uses LanceDB for an accurate similarity search for data in PDF documents. You can use other vector databases like Pinecone or Superbase Vector.
- Phidata: For building the agentic RAG system
- Amazon S3: For a PDF storage.
What is Retrieval Augmented Generation (RAG)?
Supposing we want to build a chat messaging application using Stream's React Native Chat SDK to allow users to chat on Android and iOS devices. One way to start is to ask an LLM like ChatGPT or Claude for a step-by-step guide with a context. However, the probability of getting a hallucinated, outdated, or generic guide on how to build the chat app is very high. You may get inaccurate steps because ChatGPT and Claude, as language transformers, are trained on massive datasets rather than specifically on Stream's React Native documentation to create chat apps. RAG becomes helpful in the situations described above. RAG is nothing more than providing an LLM with knowledge bases and tools for accurate and valuable responses. In RAG, you can give the LLM the latest information about your enterprise's data or documentation in the form of Markdown, PDF, text, website URL, etc. Providing a knowledge base to an LLM prevents the unwanted results described above.
The following sections will guide you through building an AI agent in Python and arming it with a PDF knowledge base for precise information retrieval.
Understanding RAG
The following is a practical example of RAG being used across different AI tools. In Microsoft Copilot, whenever you prompt the model, it searches the web for information and combines it with the data it is trained on (what it already knows) before presenting the results. In summary, three things are happening here:
- Retrieval: The LLM can retrieve data from any unstructured source, such as text, audio, video, and images.
- Augmented (augmentation): It then augments or modifies the information retrieved from the knowledge base.
- Generation: Finally, it spawns its response to the user based on the specified prompt.
The primary idea behind RAG is that when a user sends plain/human-understandable text as a prompt, the LLM transforms it into a machine-understandable query and sends a request to a knowledge base (vector database). The knowledge base can also be arrays of embeddings or a standard database. The knowledge base processes the request and returns it to the LLM. Finally, the LLM combines the information it retrieves from the data source with the prompt and generates an answer.

In the diagram above, the response quality control loop (Response Quality Checks) ensures that the LLM retrieves only accurate information from the knowledge base.
What is an Agentic RAG?
As explained earlier, a standard RAG connects a vector database to the LLM to retrieve relevant information and generate a response. Although it produces accurate results from the knowledge base, a problem will arise if you want to assign multiple vector databases to the LLM to perform additional tasks. An agentic RAG comes into play in a situation like this. Simply put, a RAG agent system arms the LLM with tools and functions and uses the LLM as an agent or orchestrator to help perform complex and multi-step problems rather than using the LLM only for generating responses.

The RAG agent diagram shows two vector databases containing weather and financial information. When a user enters a prompt, the AI agent analyzes it and consults the knowledge base that contains the required data. Also, suppose a user asks the agent to retrieve information not in any vector databases (LanceDB and Pinecone in this context). In that case, the agent will know that the requested information is not in any data store, and it can do a web search. It will display a message about its inability to retrieve relevant data if no relevant information is found.
Key Features of Agentic RAG
An agentic RAG system has numerous advantages over a standard RAG. For example, using agentic RAG over traditional RAG when solving complex tasks is beneficial.
- Multiple documents search: Agentic RAG supports comparing multiple documents for similarities and differences.
- Multi-part requests: It supports handling complex requests with different parts or requiring multiple answers.
- A diverse set of knowledge bases: Agentic RAG supports using two or more knowledge bases. Retrieving information from multiple sources helps improve responses.
- Sequential reasoning: RAG agents can solve complex tasks that require the LLM to think sequentially.
Enterprise Applications of RAG Agents
In the enterprise landscape, RAG agents can be built to automate complex tasks and repetitive processes. These agentic RAG systems can help minimize manual, repetitive work in organizations and improve team workflows and productivity. The following are some of the enterprise use cases of RAG agents.
- Tickets RAG agent: Build a support RAG agent to create tickets automatically based on received customer queries.
- Feedback RAG agent: To collect customer feedback, analyze sentiments, and track common issues to improve customer service.
- Meeting invite and calendar agent: Automatically schedule meetings based on meeting notes and team members' or stakeholders' availability.
- Invoice reminder RAG agent: Automatically schedule reminder notifications to collect overdue invoices.
- Contact and subscription renewal RAG agents: Automate the renewal of customer contracts and subscriptions to ensure timely renewals.
Note: The above use cases are just a few of the countless application areas of agentic RAG systems.
Build a RAG Agent With LLMs
There are several excellent Python frameworks for building agent-based RAG applications. We will use Phidata as the agentic RAG framework for simplicity and ease of use.
Configure Your Environment
Create a new Python virtual environment with your favorite editor, install Phidata and OpenAI, export your API key, and install the knowledge base and text search package dependencies by running the following commands in your Terminal.
123456789101112131415# Environment set up python3 -m venv ~/.venvs/aienv source ~/.venvs/aienv/bin/activate # Install Phidata and OpenAI pip install -U phidata openai # Export your OpenAI API key export OPENAI_API_KEY=”OPENAI_API_KEY” # Install knowledge base and text search dependencies pip install lancedb tantivy pypdf # Install dependencies for the agent UI (Phidata Playground) pip install 'fastapi[standard]' sqlalchemy
Aside from LanceDB, we need:
- Tantivy: To perform a full-text search.
- Pypdf: This is used to transform the PDF file.
- Sqlalchemy: To provide persistence patterns. It is a dependency for Phidata Playground.
- FastAPI: This is for serving the agentic RAG app through Phidata’s Playground.
Create a RAG Agent in Phidata
Working with Phidata allows you to write pure Python code to build your agentic retrieval systems. Create a new Python file using your favorite IDE and add the following required imports.
123456from phi.agent import Agent from phi.model.openai import OpenAIChat from phi.embedder.openai import OpenAIEmbedder from phi.knowledge.pdf import PDFUrlKnowledgeBase from phi.vectordb.lancedb import LanceDb, SearchType from phi.playground import Playground, serve_playground_app
If you get a warning about any of the imported packages not being installed, refer to the previous section to install it.
Specify Your Document URL
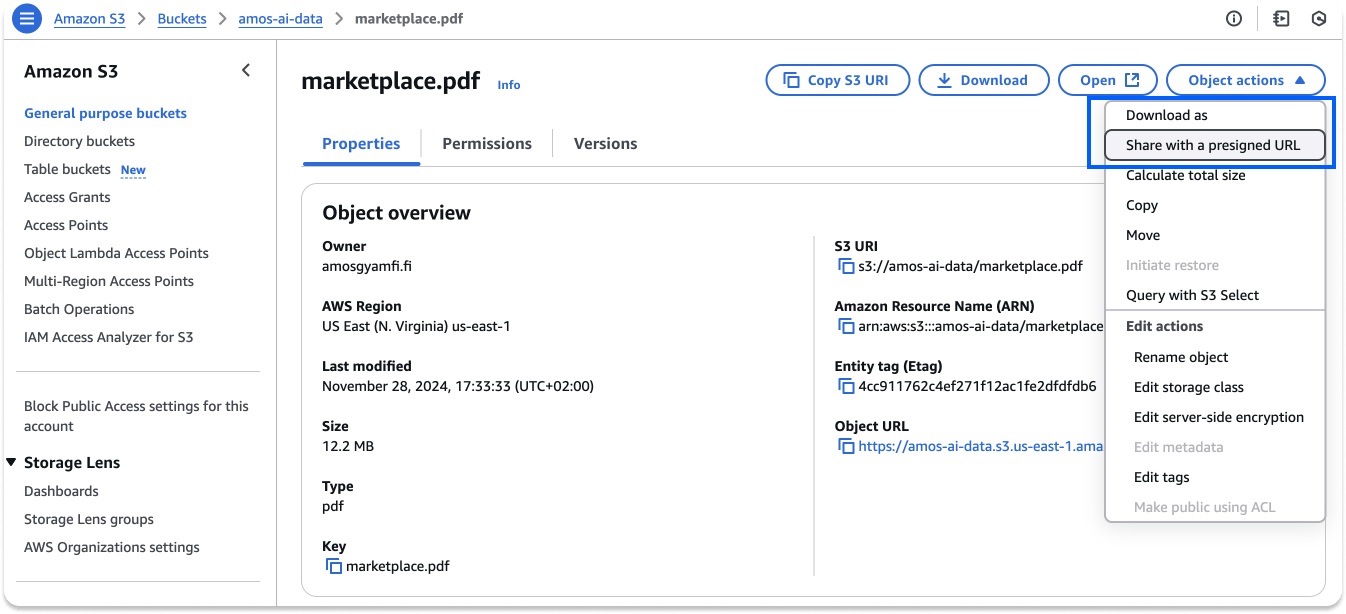
Below the package's import, specify the document URL you want for the retrieval agent.
pdf_url = "YOUR_AMAZON_S3_PDF"
In this example, we upload a PDF document to Amazon S3 and generate a Preassigned URL to make it accessible to anyone with the link. You can create an AWS Management Console account or upload a PDF to any preferred service.
Note: Using the Object URL of the Amazon S3 PDF won't be accessible. Instead, you should generate a Preassigned URL as the image above indicates.
Create a Knowledge Base With LanceDB
1234567891011# Create a knowledge base from a PDF knowledge_base = PDFUrlKnowledgeBase( urls=[pdf_url], # Use LanceDB as the vector database vector_db=LanceDb( table_name="recipes", uri="tmp/lancedb", search_type=SearchType.vector, embedder=OpenAIEmbedder(model="text-embedding-3-small"), ), )
The next step is to create a LanceDB vector database connection by specifying properties such as table_name, URI, search_type, and embedder.
search_type: Configuring the search type asvectorhelps us do similarity and relatedness searches to improve the information retrieval results from the knowledge base.text-embedding-3-small: We use OpenAI's text-embedding-3-small model to help the LLM understand the PDF content and ensure seamless and efficient retrieval.
After creating the knowledge base, we should load it into the vector database.
knowledge_base.load()
Next, we create our RAG agent using Phidata's Agent class and specify the agent's capabilities.
1234567retrieval_agent = Agent( model=OpenAIChat(id="gpt-4o-mini"), # Add the knowledge base to the agent knowledge=knowledge_base, show_tool_calls=True, markdown=True, )
Here, we use gpt-4o-mini as the language model and set markdown=True to get a well-formatted display of the models' responses.
Streaming the output through the Terminal allows us to add the code below to print the agent's response.
retrieval_agent.print_response("What are the main features of the marketplace?", stream=True)
However, we need a UI to specify prompts and interact with the RAG agent. Let's implement that in the next section.
Implement UI For the RAG Agent
To implement a UI for the RAG agent, remove the following line from your code or make it an inline comment.
retrieval_agent.print_response("What are the main features of the marketplace?", stream=True)
Then, add this code at the bottom of the previous ones.
12345# Create playground with both agents app = Playground(agents=[retrieval_agent]).get_app() if __name__ == "__main__": serve_playground_app("retrieval_agent:app", reload=True, port=7777)
With the code snippet above, we create a new Phidata Playground app for the retrieval agent, serve it, and specify the local host's port (endpoint) to test it.
Putting Everything Together
Let's combine all the previous code snippets and run the RAG agent.
123456789101112131415161718192021222324252627282930313233343536from phi.agent import Agent from phi.model.openai import OpenAIChat from phi.embedder.openai import OpenAIEmbedder from phi.knowledge.pdf import PDFUrlKnowledgeBase from phi.vectordb.lancedb import LanceDb, SearchType from phi.playground import Playground, serve_playground_app pdf_url = "https://amos-ai-data.s3.us-east-1.amazonaws.com/ios-chat.pdf" # Create a knowledge base from a PDF knowledge_base = PDFUrlKnowledgeBase( urls=[pdf_url], # Use LanceDB as the vector database vector_db=LanceDb( table_name="recipes", uri="tmp/lancedb", search_type=SearchType.vector, embedder=OpenAIEmbedder(model="text-embedding-3-small"), ), ) knowledge_base.load() retrieval_agent = Agent( model=OpenAIChat(id="gpt-4o-mini"), # Add the knowledge base to the agent knowledge=knowledge_base, show_tool_calls=True, markdown=True, ) # Create playground with both agents app = Playground(agents=[retrieval_agent]).get_app() if __name__ == "__main__": serve_playground_app("retrieval_agent:app", reload=True, port=7777)
Note: Before running the code, you should replace `pdf_url = "https://amos-ai-data.s3.us-east-1.amazonaws.com/ios-chat.pdf" with a link to your PDF document.
Running our RAG agent requires Phidata authentication. Run phi auth to authenticate the app. Then run your Python file like python3 retrieval_agent.py. You now have a fully functional agentic RAG system that can retrieve relevant information from a PDF document.
Conclusion
This tutorial guided you and demonstrated an exciting journey of building agents-powered RAG systems using an agentic Python framework, LLM, and a vector database. You created a single, straightforward agent for information retrieval from a PDF document. You can go beyond this basic agentic RAG workflow by building a multi-agent RAG application and integrating AI moderation for user safety.