

In this post, we will see how to build a Python server allowing frontend chat SDKs to start and stop an AI agent for a channel in Stream Chat.
Building polished AI assistants can be challenging. Features like streaming responses, table components, and code generation require complex implementation across SDKs and the backend.
To ease this, we’ve developed a universal solution that connects our Chat API to external LLM providers via a single backend server (NodeJS or Python), simplifying agent management and integration.
When started, the AI agent will join the channel, listen to new messages from the chat participants, and send them to an LLM to get AI-generated responses.
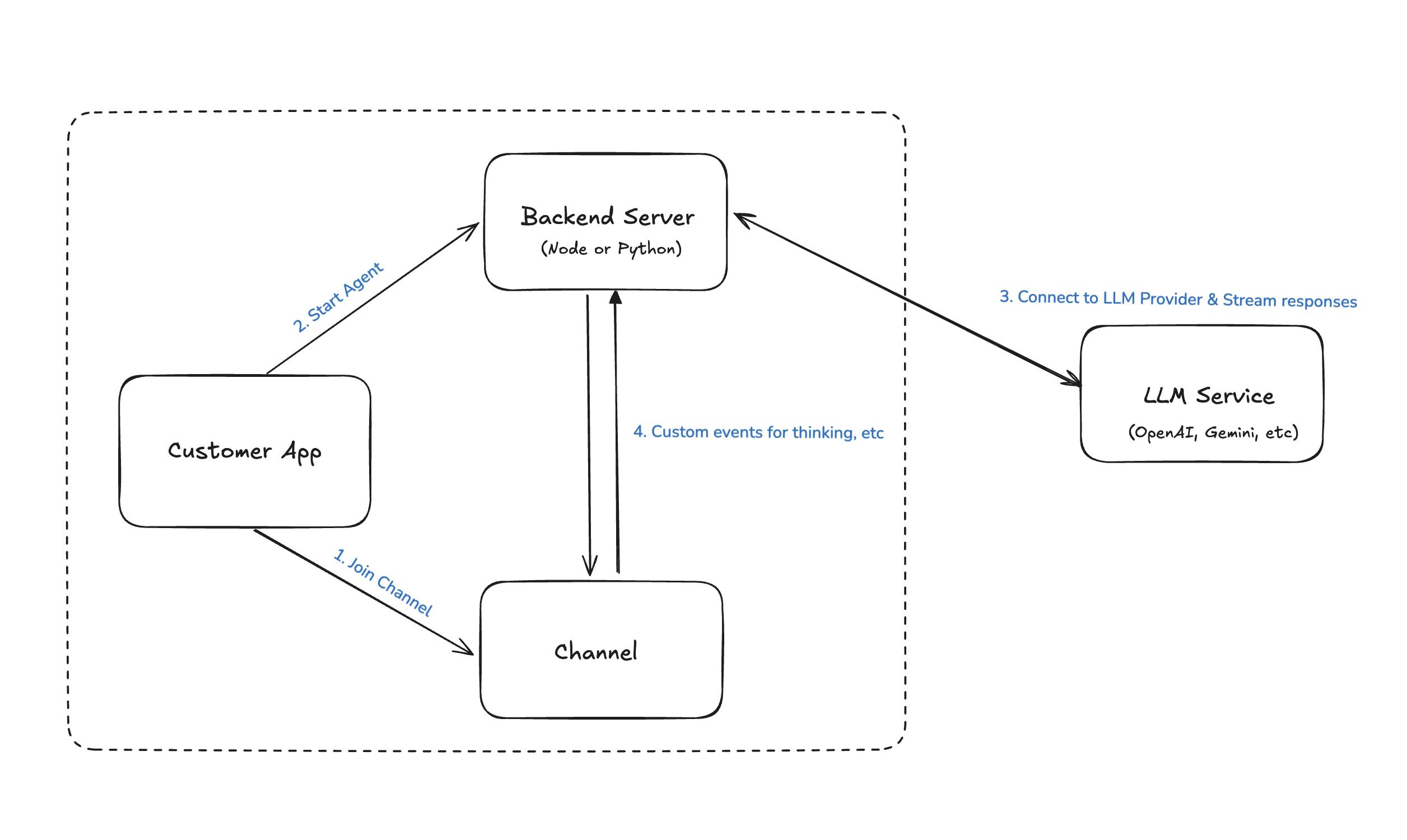
We offer a lot of guides on how to integrate these backends into frontend applications:
Let’s see how we can build this. You can find the complete project that you can run locally here.
1. Creating the Python Project
First, we create a new directory for our project and navigate into it:
12mkdir python-ai-assistant cd python-ai-assistant
We want to isolate our working environment to not interfere with other projects on our device, and we’ll use Python’s built-in venv module for that. For that, we create the new virtual environment with the name env:
1python -m venv env
We need to activate the virtual environment. We do that with the following command:
12345# Windows env\Scripts\activate # macOS, Linux source env/bin/activate
Our terminal prompt now starts with (env), indicating the virtual environment is active. All Python packages that we install will now be isolated in this environment.
2. Adding the Dependencies
For this project, we will need several dependencies. We can either install them separately or use the requirements.txt file in the repository.
Let’s install them first, and then we’ll review why we need each. To install them from scratch, we run the following command in the virtual environment that we just activated:
1pip install "fastapi[standard]" stream-chat python-dotenv anthropic
The alternative is to copy the requirements.txt file into the python-ai-assistant folder and run the installation like this:
1pip install -r ./requirements.txt
We need to install the following packages:
fastapi: the FastAPI framework is a minimal yet powerful backend framework that makes it very easy to set up a server without adding much boilerplate codestream-chat: we want to be able to work with our chat project to add and remove the AI and send messages as well as events; for that, we use the Python server packagepython-dotenv: to hide our secrets, we store them in a.envfile; to load them we use the popular dotenv package, to keep them save and away from curious eyesanthropic: the official Python SDK from Anthropic allows us to seamlessly interact with their LLM services in the most straightforward way
These are all the packages we need. With them installed, we can start the implementation.
3. Setting Up the Environment File
Before we run the project, we need to set up the API keys of the services we’ll use.
There's a .env.example that you can use as a template. We must provide values for the following keys in our .env file.
123ANTHROPIC_API_KEY=insert_your_key STREAM_API_KEY=insert_your_key STREAM_API_SECRET=insert_your_secret
Note that we are using Anthropic in this example. We can easily switch that to other providers, such as OpenAI or Gemini. In that case, we would also need to add the respective secrets.
4. Adding and Removing Agents
To implement anything, we need to start by creating a file called main.py in the root of our project and opening it in our code editor (e.g., Visual Studio Code).
Then we initialize the FastAPI backend by adding this code snippet to the file:
12345678from fastapi import FastAPI app = FastAPI() if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8001)
The simplicity of getting started is evident here. The initialization is a one-liner. Then, we add the logic to expose the app on port 8001 once the file is run. When we do that, we have the server running, but we’re not yet exposing any endpoints, so let’s change that.
Now, we need to think about the endpoints we must define. Specifically, we need two for now:
start-ai-agent: This needs to be aPOSTrequest because we need to know which channel we should start an agent for. We will add a bot user to the channel and initialize an AI agent. To keep track of the agents, we’ll keep them in adictto do proper cleanup.stop-ai-agent: We again need aPOSTrequest for this since we will need the channel for which we need to stop the AI agent. We’ll clean up the related agent, remove the bot user from the channel, and close the connection to the Stream backend.
Let’s start with the start-ai-agent endpoint. We define this with the @ decorator (more details here). First, we must set up the connection to Stream Chat (using the async initializer) and add the bot to the channel.
Before defining the endpoint itself, we define the parameters it receives. FastAPI uses Pydantic to define these model classes. We call ours StartAgentRequest and define it like this (we can add this to the top of main.py:
12345from pydantic import BaseModel class StartAgentRequest(BaseModel): channel_id: str channel_type: str = "messaging"
Here’s the code for the endpoint:
123456789101112131415161718192021222324252627282930313233@app.post("/start-ai-agent") async def start_ai_agent(request: StartAgentRequest, response: Response): server_client = StreamChatAsync(api_key, api_secret) # Clean up channel id to remove the channel type - if necessary channel_id_updated = clean_channel_id(request.channel_id) # Create a bot id bot_id = create_bot_id(channel_id=channel_id_updated) # Upsert the bot user await server_client.upsert_user( { "id": bot_id, "name": "AI Bot", "role": "admin", } ) # Create a channel channel = server_client.channel(request.channel_type, channel_id_updated) # Add the bot to the channel try: await channel.add_members([bot_id]) except Exception as error: print("Failed to add members to the channel: ", error) await server_client.close() response.status_code = 405 response.body = str.encode( json.dumps({"error": "Not possible to add the AI to distinct channels"}) ) return response
This code initializes our Stream Chat client. It then cleans up the channel_id inside the request. This is necessary because we must ensure it doesn’t contain special characters before jumping to the next step. For that, we add a helper method called clean_channel_id:
1234567def clean_channel_id(channel_id: str) -> str: channel_id_updated = channel_id if ":" in channel_id: parts = channel_id.split(":") if len(parts) > 1: channel_id_updated = parts[1] return channel_id_updated
We then create a bot_id that contains the updated channel ID. This needs to be replicable to ensure that multiple AI agents are not created for the same channel. Here’s the code for our helper function:
12def create_bot_id(channel_id: str) -> str: return f"ai-bot-{channel_id.replace('!', '')}"
Then, we add the user using the upsert_user function (which is only being executed the first time we add an agent to the respective channel). We retrieve the channel from the Stream chat client and add the bot user using the add_members function.
Note: We must wrap that last call into a try-except block because we can’t add the bot for distinct channels. This is a limitation of the Python SDK since it doesn’t support watchers as of the writing of this article. If you need to support that, consider using the Node.js SDK (we have a similar tutorial). If adding the bot fails, we handle the error gracefully, close the connection to the client, and return an appropriate response.
Since the Node.js example uses the watchers to determine if an AI is in a channel, we need to modify the frontend examples to instead check for an existing AI member. Here’s an example how to incorporate that into a React example using a useEffect hook (in our frontend example, this would go into the MyChannelHeader.tsx file):
123456789101112131415161718192021222324const { channel } = useChannelStateContext(); const [aiInChannel, setAiInChannel] = useState(false); useEffect(() => { channel?.queryMembers({}).then((members) => { const isAiInChannel = members.members.filter((member) => member.user_id?.includes('ai-bot')) .length > 0; setAiInChannel(isAiInChannel); }); const relevantEvents = ['member.added', 'member.removed']; channel?.on((event) => { if (relevantEvents.includes(event.type)) { channel?.queryMembers({}).then((members) => { const isAiInChannel = members.members.filter((member) => member.user_id?.includes('ai-bot') ).length > 0; setAiInChannel(isAiInChannel); }); } }); }, [channel]);
Next, we want to handle the creation and management of AI agents. For that, we first need to have an agent that we can add. We create a basic file we’ll fill out in the next chapter. For now, we create a new file AnthropicAgent.py with the following code:
1234567891011class AnthropicAgent: def __init__(self, chat_client, channel): self.chat_client = chat_client self.channel = channel api_key = os.environ.get("ANTHROPIC_API_KEY") if not api_key: raise ValueError("Anthropic API key is required") self.anthropic = AsyncAnthropic(api_key=api_key) async def dispose(self): await self.chat_client.close()
We initialize it with an instance of the Stream chat client and a channel that we will use later. Then, we check if the API key is present, initialize the AsyncAnthropic client, or raise an error if that’s not the case. Finally, we add a dispose method, where we close the connection to the chat_client.
Once that is done, we can jump back to main.py and continue with our implementation of the start-ai-agent endpoint. Whenever we create new agents, we want to save them into an agent dictionary so we can access them later.
For that, we add an initializer before our definition of the start-ai-agent endpoint:
1agents = {}
Then we add the following snippet to the endpoint itself after the code we have already added:
12345678910# Clean up any old bot we might have if bot_id in agents: await agents[bot_id].dispose() # Create an agent agent = AnthropicAgent(server_client, channel) # Add agent to our agents agents[bot_id] = agent return {"message": "AI agent started"}
If an agent exists for this channel, we dispose of it properly before creating a new one. Here, we create a new instance of our AnthropicAgent and manage its lifecycle. This prevents memory leaks and ensures only one active agent per bot.
Next, we add the endpoint for stopping an agent. Here, we need to dispose of the agent and remove it from our list of agents. Then, we remove the bot from the channel and close the connection to the Stream chat client.
Again, we define a model for calling the endpoint:
12class StopAgentRequest(BaseModel): channel_id: str
And here’s the complete code for it:
12345678910111213@app.post("/stop-ai-agent") async def stop_ai_agent(request: StopAgentRequest): server_client = StreamChatAsync(api_key, api_secret) bot_id = create_bot_id(request.channel_id) if bot_id in agents: await agents[bot_id].dispose() del agents[bot_id] channel = server_client.channel("messaging", request.channel_id) await channel.remove_members([bot_id]) await server_client.close() return {"message": "AI agent stopped"}
To run our server, we run the following command:
1python main.py
We can now add and remove agents from the channels. But these agents haven’t done anything yet, so let’s change that.
5. Listen to Messages Using A Webhook
Before writing code, let’s step back and consider what we want to achieve. Whenever a user sends a new message in a channel where an agent is present, we want to react to that message and stream the response back to the channel.
We can achieve this by using a webhook that gets triggered whenever a new message is sent. We expose an endpoint (in our case, new-message) that receives this event and can act accordingly.
First, we define a model for the endpoint:
123456from typing import Optional class NewMessageRequest(BaseModel): cid: Optional[str] type: Optional[str] message: Optional[object]
We’re using the Optional type because different events might come in with different parameters. In the implementation, we check for the different event types later on.
Then, we define a basic endpoint that we can register for the webhook:
123@app.post("/new-message") async def new_message(request: NewMessageRequest): print(request)
While this does nothing, we can see if the webhook registration worked.
To test this with our machine, we need to be able to reach our local server through the web. We use ngrok for that but feel free to check for alternatives. After signing up and installing it on our machine (e.g. using brew install ngrok on macOS), we can expose our server on the web with this command (remember: we set port 8001 for our Python server):
1ngrok http http://localhost:8001
The output of this command will show an ephemeral domain that we need to copy, which looks like this:
1https://9511-2001-a62-1435-7201-40f6-1314-8aa4-803.ngrok-free.app
To register this to be called when new messages arrive, we go to the Stream dashboard and our project page. We scroll to the webhooks section (see screenshot below) and paste the domain we just copied. It’s essential to add the /new-message to the end of it to ensure it’s calling our endpoint.
We de-select all events except for the message one.
With that we can run our project and send a message in a channel and will see the request being printed in the console of our server.

We have verified that the webhook works and can now implement the LLM.
6. LLM Integration
In this chapter, we finally integrate the LLM functionality. We implement Anthropic, but this can be switched to any other service. Before we implement the AnthropicAgent, though, we need to fill our new-message endpoint with the necessary logic. We do that first and then jump to our agent implementation.
Inside new-message, we first verify that we get a cid (a channel ID) in the request. Then, we construct the bot_id and check if we have an agent running for that. If yes, and it is not currently processing a request, we call its handle_message function, which will do the rest.
Here’s the complete code:
12345678910111213141516@app.post("/new-message") async def new_message(request: NewMessageRequest): print(request) if not request.cid: return {"error": "Missing required fields", "code": 400} channel_id = clean_channel_id(request.cid) bot_id = create_bot_id(channel_id=channel_id) if bot_id in agents: if not agents[bot_id].processing: await agents[bot_id].handle_message(request) else: print("AI agent is already processing a message") else: print("AI agent not found for bot", bot_id)
Now, let’s turn to the AnthropicAgent.py file. We added a basic initialization to it already, but we need a few more properties to be initialized that will get more clear while we enhance the implementation.
We add these properties to the __init__ function (below the initialization of the AsyncAnthropic client:
123self.processing = False self.message_text = "" self.chunk_counter = 0
Next, we create a handle_message function. We called that from the new message endpoint but haven’t implemented it yet. Let’s add the function signature and then fill it up step-by-step:
12async def handle_message(self, event: NewMessageRequest): self.processing = True
We set the processing property to True whenever we call that, preventing duplicated work.
Then, we check if the message was from the AI itself (which we should ignore if we don’t want the AI talking to itself) using the ai_generated property:
1234if not event.message or event.message.get("ai_generated"): print("Skip handling ai generated message") self.processing = False return
Now we know that we want to process this message. To indicate that to the users, we want to send an empty message to the channel and also send an event to indicate that the agent is currently thinking about the response:
12345678910111213141516171819bot_id = create_bot_id(channel_id=self.channel.id) channel_message = await self.channel.send_message( {"text": "", "ai_generated": True}, bot_id ) message_id = channel_message["message"]["id"] try: if message_id: await self.channel.send_event( { "type": "ai_indicator.update", "ai_state": "AI_STATE_THINKING", "message_id": message_id, }, bot_id, ) except Exception as error: print("Failed to send ai indicator update", error)
We want to give the agent some context, so we query for the last five messages in the channel. Here’s the code for that:
12345678910111213141516171819channel_filters = {"cid": event.cid} message_filters = {"type": {"$eq": "regular"}} sort = {"updated_at": -1} message_search = await self.chat_client.search( channel_filters, message_filters, sort, limit=5 ) messages = [ { "content": message["message"]["text"].strip(), "role": ( "assistant" if message["message"]["user"]["id"].startswith("ai-bot") else "user" ), } for message in message_search["results"] if message["message"]["text"] != "" ]
With these messages, we can now create an anthropic_stream object using the Anthropic SDK:
123456anthropic_stream = await self.anthropic.messages.create( max_tokens=1024, messages=messages, model="claude-3-5-sonnet-20241022", stream=True, )
Now we can listen to the stream and handle each event that arrives using a custom handle message, that we’ll define in a second. If an error occurs, we send an event to the channel that something went wrong:
12345678910111213try: async for message_stream_event in anthropic_stream: await self.handle(message_stream_event, message_id, bot_id) except Exception as error: print("Error handling message stream event", error) await self.channel.send_event( { "type": "ai_indicator.update", "ai_state": "AI_STATE_ERROR", "message_id": message_id, }, bot_id, )
The last step is to handle the events we get from the anthropic_stream object. Let’s add the function signature again and extract the event_type. Then, we will go over the different events and how we handle them.
12async def handle(self, message_stream_event: Any, message_id: str, bot_id: str): event_type = message_stream_event.type
There are four events we need to handle:
content_block_start: indicates that the generation of the response has startedcontent_block_delta: a new response element has arrivedmessage_delta: indicates that a change to the final message has been donemessage_stop: when the generation is finished
Let’s start implementing the logic for all of them. When the generation starts, we send a message to the channel indicating that the agent is now generating a response:
123456789if event_type == "content_block_start": await self.channel.send_event( { "type": "ai_indicator.update", "ai_state": "AI_STATE_GENERATING", "message_id": message_id, }, bot_id, )
If a new content block arrives, want to update the message with that new chunk using the update_message_partial function. However, not to spam the channel, we only execute that for every 20th chunk (which is an arbitrary number that we can play around with, just keep in mind not to spam the channel too much):
12345678910111213elif event_type == "content_block_delta": self.message_text += message_stream_event.delta.text self.chunk_counter += 1 if self.chunk_counter % 20 == 0: try: await self.chat_client.update_message_partial( message_id, {"set": {"text": self.message_text, "generating": True}}, bot_id, ) except Exception as error: print("Error updating message", error)
In case we get an update of the final message, we update that message:
123456elif event_type in ["message_delta"]: await self.chat_client.update_message_partial( message_id, {"set": {"text": self.message_text, "generating": False}}, bot_id, )
And finally, if the generation has stopped, we do a final update of the message and then send the ai_indicator.clear event to the channel:
12345678910111213elif event_type == "message_stop": await self.chat_client.update_message_partial( message_id, {"set": {"text": self.message_text, "generating": False}}, bot_id, ) await self.channel.send_event( { "type": "ai_indicator.clear", "message_id": message_id, }, bot_id, )
We have finished the implementation. If we add an agent to the channel and send a message, the thinking indicator will pop up, and the response will gradually update once the AI response is streaming in.
Conclusion
In this post, we have seen how to implement a server-side integration of Stream Chat with popular LLMs, such as Anthropic.
We have seen how to set up a Python server with the required dependencies using FastAPI. Also, We have shown you how to create a Stream Chat client on the backend that will listen to messages in a channel using a webhook.
Then, we have integrated with Anthropic to get streaming responses and send those as message updates. You have learned how to send events that will update the LLM state on the client (the AI typing indicator).
Visit our AI landing page to learn more about our AI solution. Then, create your free Stream account to add exciting AI chat capabilities to your apps today!