

Deepseek is the latest LLM to hit the digital shelves. It boasts high-quality reasoning at a fraction of the cost of current state-of-the-art models, OpenAI o1 and o3-mini, and Gemini 2.0 Flash Thinking.
DeepSeek R1 is open-source, which means two things. First, developers can examine the model's architecture, training process, and weights directly, enabling a better understanding of its capabilities and limitations and allowing for customization and improvement. Second, organizations can deploy the model on their infrastructure, giving them complete control over data privacy, scaling, and cost optimization while avoiding vendor lock-in.
So that is what you’re going to do today. You will download one of the smaller DeepSeek models, DeepSeek-R1-Distill-Llama-8B, store it in an S3 bucket, and then use AWS Bedrock to host it. The model will then be consumed as a Stream AI chatbot.
Self-Hosting Deepseek on AWS Bedrock
(Note: you will incur costs hosting this model on AWS Bedrock)
AWS Bedrock allows you to deploy and manage foundation models from various providers, including custom models, through a unified API. You’re going to take advantage of this custom model ability.
Let’s start by creating a quick Python script to transfer our DeepSeek model from Huggingface to an AWS S3 bucket Bedrock can use. First, install the dependencies:
pip install huggingface_hub boto3huggingface_hub: A Python library that provides an interface for interacting with the Hugging Face Hub. It allows you to download and manage models and datasets.boto3: The Python SDK for AWS allows you to interact with AWS services programmatically.
Use huggingface_hub first to download a snapshot of our specific DeepSeek R1 model:
1234from huggingface_hub import snapshot_download model_id = "deepseek-ai/DeepSeek-R1-Distill-Llama-8B" local_dir = snapshot_download(repo_id=model_id, local_dir="DeepSeek-R1-Distill-Llama-8B")
Then, use boto3 to upload it to a bucket:
123456789101112131415161718192021222324import boto3 import os # AWS Configuration aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID') aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY') s3_client = boto3.client( 's3', region_name='us-east-1', aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key ) bucket_name = 'stream-deepseek' local_directory = 'DeepSeek-R1-Distill-Llama-8B' folder_name = 'deepseek/' # Make sure to include the trailing slash for root, dirs, files in os.walk(local_directory): for file in files: local_path = os.path.join(root, file) s3_key = os.path.join(folder_name, os.path.relpath(local_path, local_directory)) # Convert Windows path separators to forward slashes for S3 s3_key = s3_key.replace('\\', '/') s3_client.upload_file(local_path, bucket_name, s3_key)
Your bucket must be in a region supporting Amazon Bedrock, such as us-east-1 or us-west-2. Then, head to Amazon Bedrock in the AWS console and start a new import job:
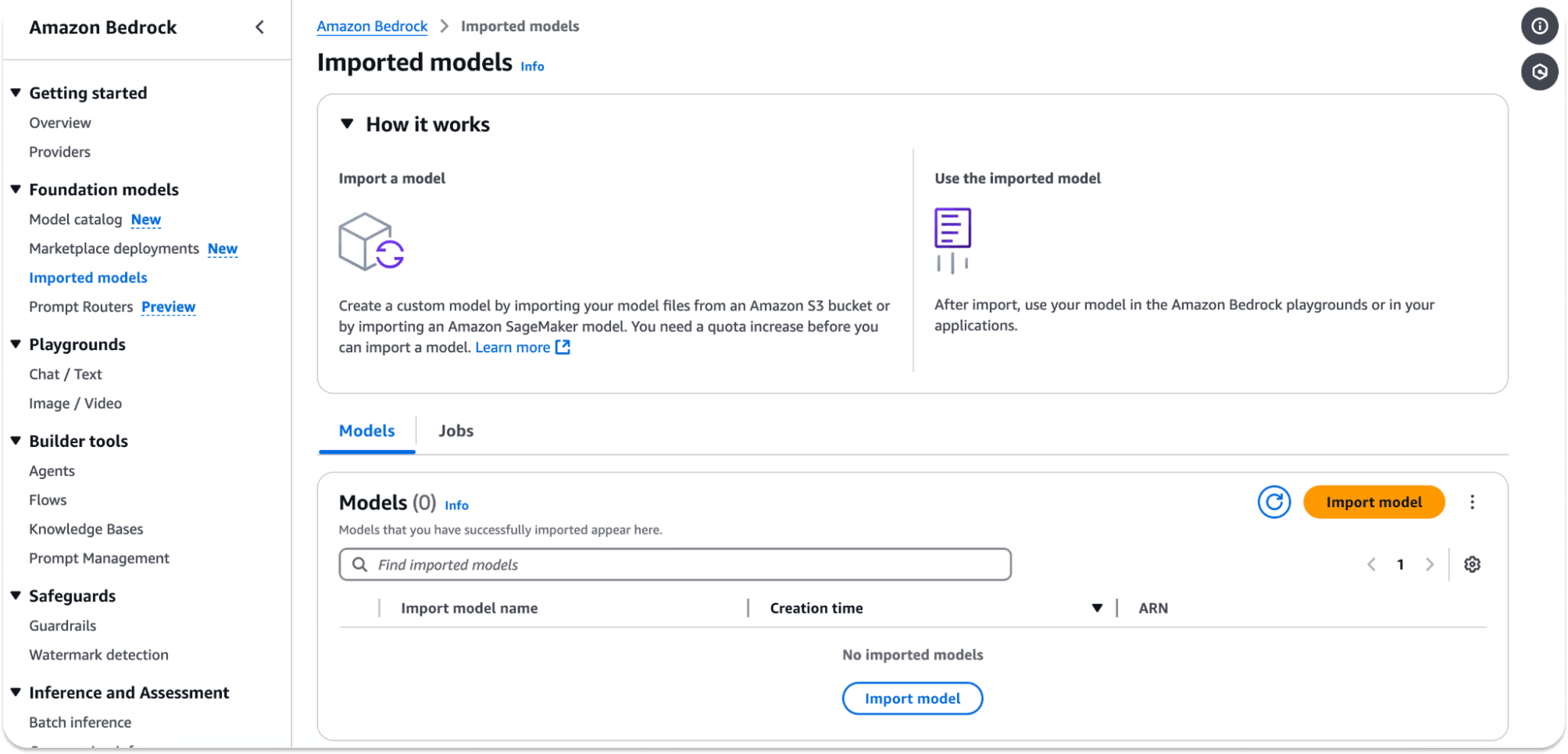
Choose Import model and add the S3 URI for the bucket with your model (e.g. s3://your-s3-bucket-name/DeepSeek-R1-Distill-Llama-8B/). The import will take a few minutes:
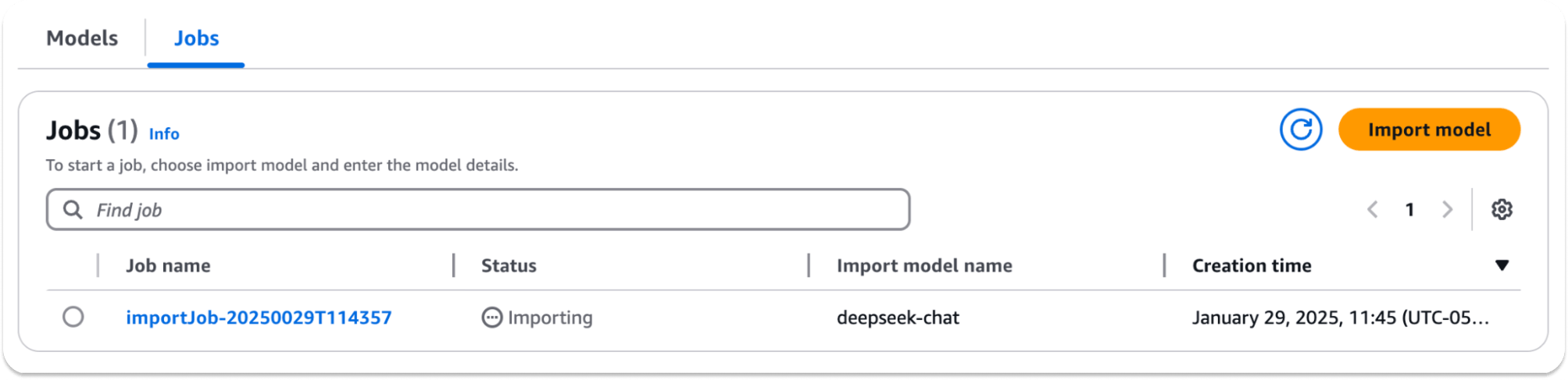
Once complete, grab the model ARN, which is what you’ll need to call the model:
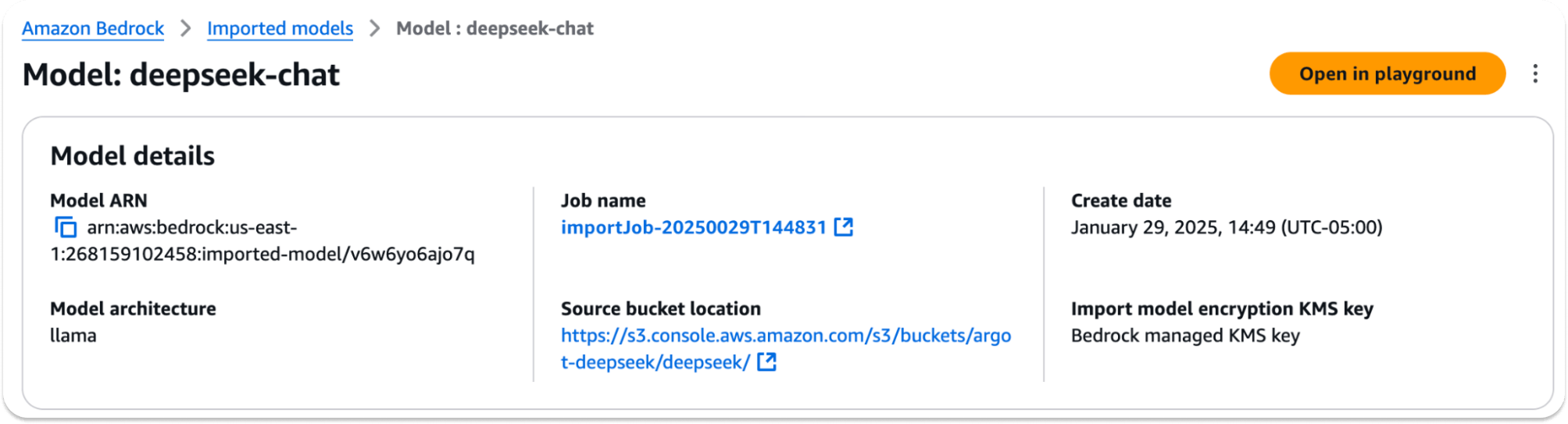
The DeepSeek model is now available on AWS. You can test it with this code:
12345678910111213141516171819202122232425import boto3 import json # AWS Configuration aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID') aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY') client = boto3.client('bedrock-runtime', region_name='us-east-1', aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key) model_id = os.environ.get('BEDROCK_MODEL_ARN') prompt = "What is the capital of France?" response = client.invoke_model( modelId=model_id, body=json.dumps({'prompt': prompt}), accept='application/json', contentType='application/json' ) result = json.loads(response['body'].read().decode('utf-8')) print(result) # output {'generation': ' Paris, right? But wait, is it really? I mean, I\'ve heard people say that sometimes the capital is a different city. Or is that just in other countries? Hmm, no, I think for France, Paris is definitely the capital. But I should double-check to be sure...', 'generation_token_count': 512, 'stop_reason': 'length', 'prompt_token_count': 8}
Seems to have a sense of humor. Time to plug it into chat.
Adding a DeepSeek Agent to Stream Chat
Most of what you need to use Deepseek with Stream already exists.
The client is going to be a React client based on this code. You will make a few changes to the Python Stream AI assistant for the backend. Instead of using an OpenAI or Anthropic agent, you’ll create a DeepSeek agent that uses the same architecture.
First, create a DeepseekAgent Class that mimics how our Anthropic agent works:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111import boto3 import json import os from datetime import datetime from typing import List, Optional, Any from model import NewMessageRequest from helpers import create_bot_id class DeepseekAgent: def __init__(self, chat_client, channel): self.chat_client = chat_client self.channel = channel self.last_interaction_ts: float = datetime.now().timestamp() self.processing = False self.message_text = "" self.chunk_counter = 0 # AWS Bedrock setup aws_access_key_id = os.environ.get('AWS_ACCESS_KEY_ID') aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY') if not aws_access_key_id or not aws_secret_access_key: raise ValueError("AWS credentials are required") self.client = boto3.client('bedrock-runtime', region_name='us-east-1', aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key ) self.model_id = os.environ.get('BEDROCK_MODEL_ID') async def dispose(self): await self.chat_client.close() def get_last_interaction(self) -> float: return self.last_interaction_ts async def handle_message(self, event: NewMessageRequest): self.processing = True if not event.message or event.message.get("ai_generated"): print("Skip handling ai generated message") self.processing = False return message = event.message.get("text") if not message: print("Skip handling empty message") self.processing = False return self.last_interaction_ts = datetime.now().timestamp() bot_id = create_bot_id(channel_id=self.channel.id) # Send initial empty message channel_message = await self.channel.send_message( {"text": "", "ai_generated": True}, bot_id ) message_id = channel_message["message"]["id"] try: await self.channel.send_event( { "type": "ai_indicator.update", "ai_state": "AI_STATE_THINKING", "message_id": message_id, }, bot_id, ) except Exception as error: print("Failed to send ai indicator update", error) try: response = self.client.invoke_model( modelId=self.model_id, body=json.dumps({'prompt': message}), accept='application/json', contentType='application/json' ) result = json.loads(response['body'].read().decode('utf-8')) print(result) response_text = result.get('generation', '') # Adjust based on actual response structure print(response_text) # Update message with response await self.chat_client.update_message_partial( message_id, {"set": {"text": response_text, "generating": False}}, bot_id, ) # Clear AI indicator await self.channel.send_event( { "type": "ai_indicator.clear", "message_id": message_id, }, bot_id, ) except Exception as error: print("Error handling message", error) await self.channel.send_event( { "type": "ai_indicator.update", "ai_state": "AI_STATE_ERROR", "message_id": message_id, }, bot_id, ) self.processing = False
This is the chat agent integration between Stream and AWS Bedrock. First, the __init__ method establishes AWS credentials and initializes the Bedrock client configuration for the us-east-1 region.
The handle_message method then manages the message processing by first creating an empty placeholder message (using channel.send_message({"text": "", "ai_generated": True})) that will be updated with the AI response. It then uses the Bedrock client's invoke_model method to send the prompt to Deepseek. We extract the 'generation' field from the response JSON, parse this, and pass it back to the channel.
Throughout this process, we maintain the state through the processing flag and update the UI using Stream's event system, toggling between AI_STATE_THINKING during processing and AI_STATE_CLEAR when complete.
Then we need a DeepseekResponseHandler:
12345678910111213141516171819202122232425262728293031323334353637383940414243from stream_chat import StreamChat from typing import Any from helpers import create_bot_id class DeepseekResponseHandler: def __init__( self, response_text: str, chat_client: StreamChat, channel: Any, message: Any ): self.response_text = response_text self.chat_client = chat_client self.channel = channel self.message = message async def handle(self): bot_id = create_bot_id(channel_id=self.channel.id) try: # Update message with full response await self.chat_client.update_message_partial( self.message["message"]["id"], {"set": {"text": self.response_text, "generating": False}}, bot_id, ) # Clear AI indicator await self.channel.send_event( { "type": "ai_indicator.clear", "message_id": self.message["message"]["id"], }, bot_id, ) except Exception as error: print("Error handling response", error) await self.channel.send_event( { "type": "ai_indicator.update", "ai_state": "AI_STATE_ERROR", "message_id": self.message["message"]["id"], }, bot_id, )
This response handler manages the final stages of the DeepSeek model's response processing within the Stream chat system. It initializes with the core components (response_text, chat_client, channel, message) needed for message manipulation. The handle method performs atomic updates using chat_client.update_message_partial(), which allows for efficient partial message updates without requiring a full message replacement.
Then, in our main.py, we call our DeepseekAgent when the client requests the /start-ai-agent endpoint:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950@app.post("/start-ai-agent") async def start_ai_agent(request: StartAgentRequest, response: Response): print(request.channel_id) server_client = StreamChatAsync(api_key, api_secret) # Clean up channel id to remove the channel type - if necessary channel_id_updated = clean_channel_id(request.channel_id) # Create a bot id bot_id = create_bot_id(channel_id=channel_id_updated) # Upsert the bot user await server_client.upsert_user( { "id": bot_id, "name": "AI Bot", "role": "admin", } ) # Create a channel channel = server_client.channel(request.channel_type, channel_id_updated) # Add the bot to the channel try: await channel.add_members([bot_id]) # Watch the channel for new messages await channel.watch() except Exception as error: print("Failed to add members to the channel: ", error) await server_client.close() response.status_code = 405 response.body = str.encode( json.dumps({"error": "Not possible to add the AI to distinct channels"}) ) return response # Create an agent agent = DeepseekAgent(server_client, channel) if bot_id in agents: print("Disposing agent") await agents[bot_id].dispose() else: agents[bot_id] = agent print(agents) return {"message": "AI agent started"}
This endpoint manages the complete lifecycle of a DeepSeek agent within Stream's infrastructure through two main operations:
- First, it performs user and channel setup by creating an admin bot user (
server_client.upsert_user) and establishing channel membership (channel.add_members([bot_id])). - Second, it handles agent lifecycle management through the global
agentsdictionary, ensuring the proper cleanup of existing agents through thedispose()method before creating new ones. This design ensures resources are appropriately managed and prevents memory leaks from abandoned agent instances.
We can then run our client and server. Run the client with:
1npm run dev
Run the server with:
1python main.py
Head to the URL given for the client (usually localhost:5173 when using vite) and you’ll see the familiar Strem chat interface, but with an Add AI in the top-right corner. Click it to call the /start-ai-agent endpoint and create an agent.
You can then chat with the Deepseek AI agent as you would another user:
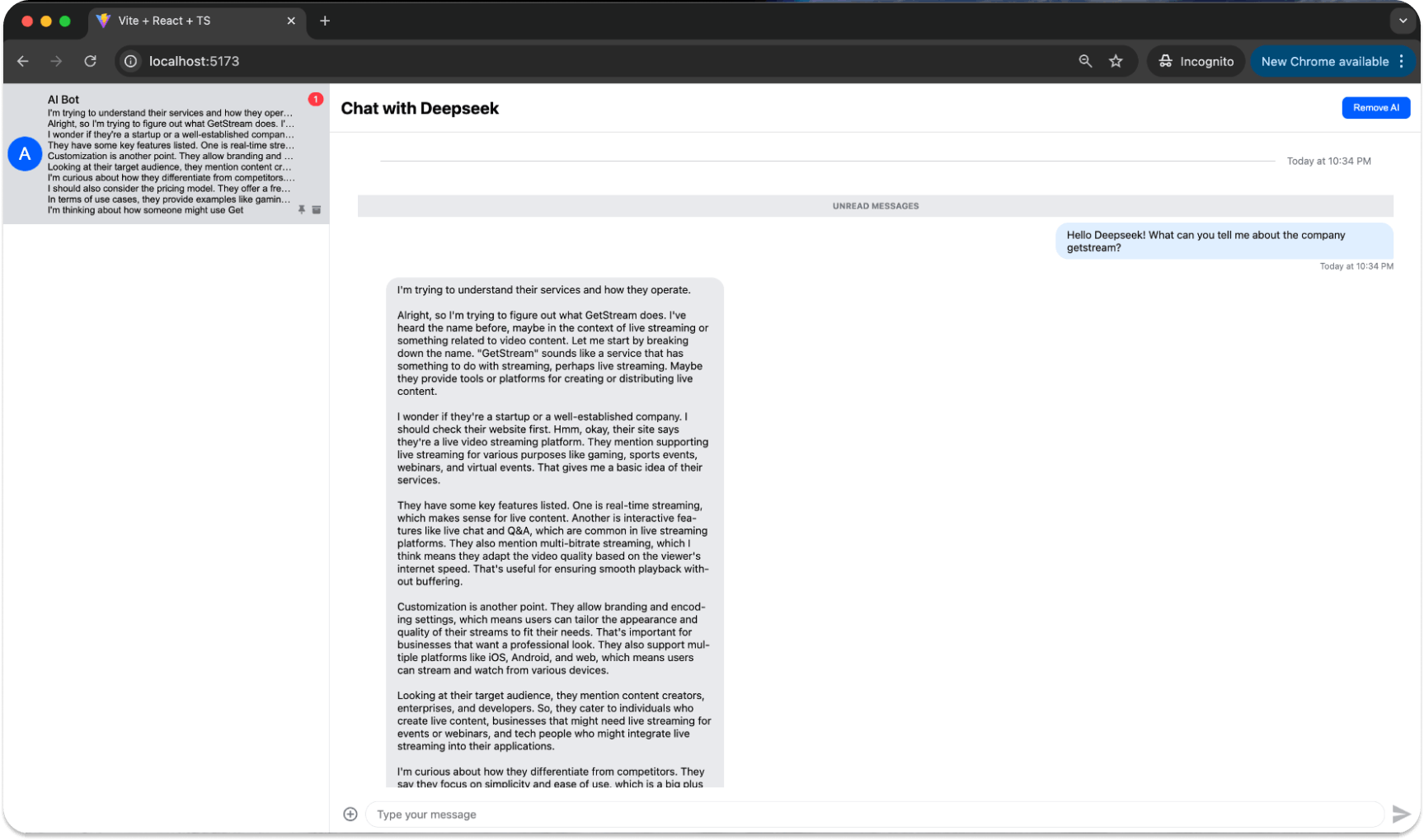
The DeepSeek-R1-Distill-Llama-8B model is one of the smaller models, so don’t expect Shakespeare. Effectively, when you add a new message to the chat, it calls a webhook for a new-message endpoint on our server:
12345678910111213141516@app.post("/new-message") async def new_message(request: NewMessageRequest): print(request) if not request.cid: return {"error": "Missing required fields", "code": 400} channel_id = clean_channel_id(request.cid) bot_id = create_bot_id(channel_id=channel_id) if bot_id in agents: if not agents[bot_id].processing: await agents[bot_id].handle_message(request) else: print("AI agent is already processing a message") else: print("AI agent not found for bot", bot_id)
As you can see, this, in turn, calls the handle_message method of our DeepseekAgent to start the process above.
When you’re done with the riveting conversation, hit Remove AI to call the /stop-ai-agent endpoint:
123456789101112131415@app.post("/stop-ai-agent") async def stop_ai_agent(request: StopAgentRequest): server_client = StreamChatAsync(api_key, api_secret) bot_id = create_bot_id(request.channel_id) print(agents) if bot_id in agents: await agents[bot_id].dispose() del agents[bot_id] channel = server_client.channel("messaging", request.channel_id) await channel.remove_members([bot_id]) await server_client.close() return {"message": "AI agent stopped"}
With that, our Deepseek agent has been killed.
Adding Deepseek and Other Custom Models to Stream
The velocity of new LLMs is incredible. Thus, you need an architecture that allows you to easily swap custom, proprietary, open-source models in and out as needed. You don’t want to be bound to a model that is obsolete in a matter of weeks.
The Stream AI architecture allows you to do this. The changes we’ve made to the initial Anthropic agent code are minimal, yet we’ve been able to introduce entirely new functionality with a lower-cost, open-source model. If a newer, better, cheaper model were launched tomorrow, we could immediately use this architecture to integrate it into an AI chatbot.
You can also run Deepseek locally, to learn more about running Deepseek locally, please see our prior article about this topic.
This approach allows developers to experiment with emerging models like DeepSeek while maintaining production-quality chat functionality and Stream's reliability.