

If you are used to using the ChatGPT or Claude chat interfaces, you might think that these models have incredible memories, able to maintain knowledge of the conversation across multiple interactions.
You're being tricked. The reality is that LLMs like Claude's have no inherent memory between calls. Each API request is stateless by design. When you use the official Claude web interface, it maintains your entire conversation history in the background and sends it with each new request. They are faking memory.
This "memory facade" pattern is fundamental to building any conversational AI application that maintains context over time, whether you're using Claude, GPT, or any other LLM. When building your own AI chatbot application, you'll need to implement this same pattern:
- Store each message exchange (both user and assistant messages)
- Bundle the entire conversation history with each new API call
- Pass this history in the messages array parameter
If you have built on Stream’s AI integration examples, you will have already used this pattern. Here, we’ll walk through doing that using the Anthropic API, showing how to use Stream to easily build a chatbot with memory, context, and history.
Constructing Our Message Memory
Let's walk through how our AnthropicAgent class works to maintain conversation context in a Stream Chat application.
We’re going to end up with this:
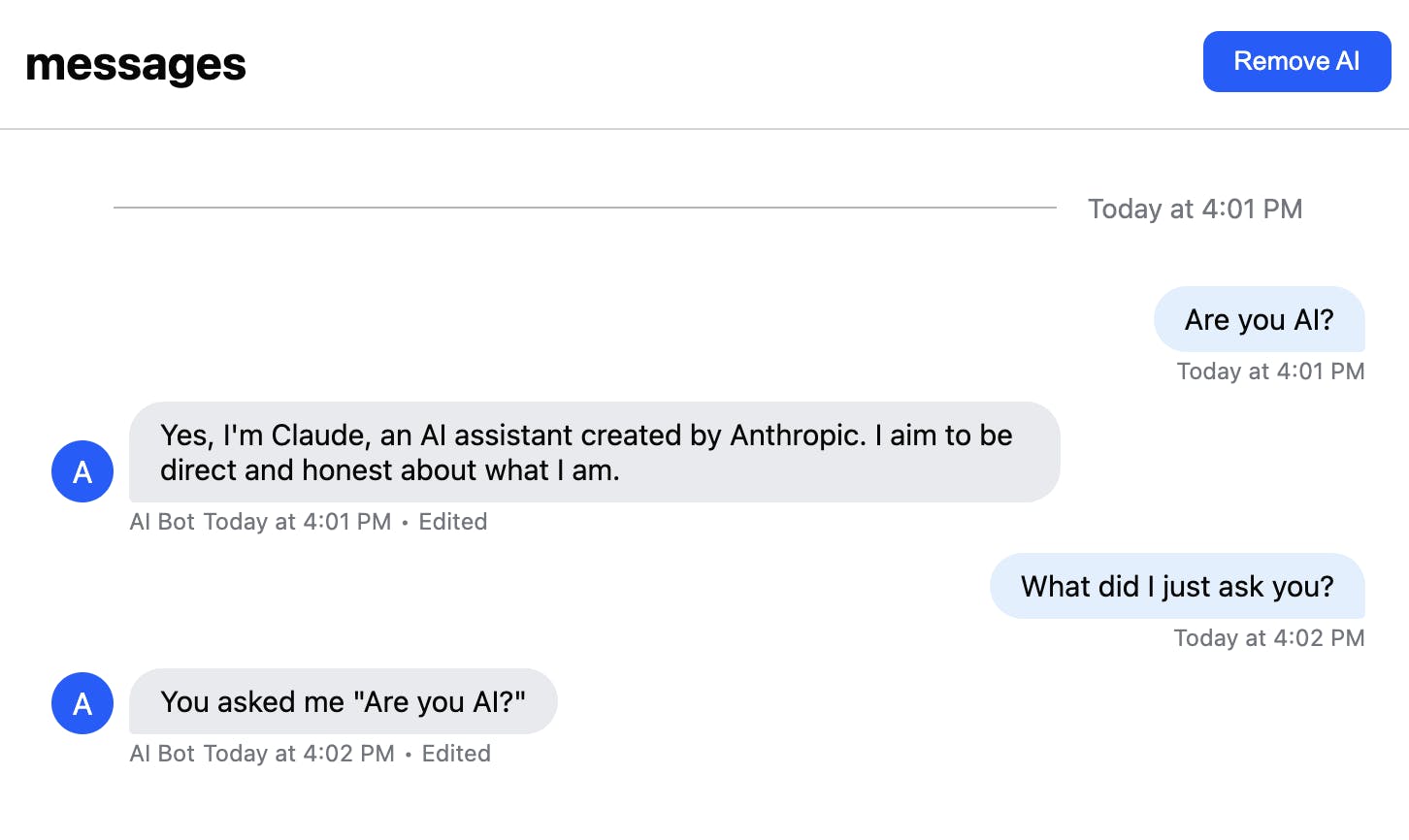
This seems simple–it looks like any chat app. And with Stream and Chat AI, it is simple, but we need to set up our implementation correctly for this to work.
First, our agent needs to connect to both the Stream chat service and the Anthropic API:
123456789101112131415161718export class AnthropicAgent implements AIAgent { private anthropic?: Anthropic; private handlers: AnthropicResponseHandler[] = []; private lastInteractionTs = Date.now(); constructor( readonly chatClient: StreamChat, readonly channel: Channel, ) {} init = async () => { const apiKey = process.env.ANTHROPIC_API_KEY as string | undefined; if (!apiKey) { throw new Error('Anthropic API key is required'); } this.anthropic = new Anthropic({ apiKey }); this.chatClient.on('message.new', this.handleMessage); };
The constructor takes two parameters:
- chatClient: A StreamChat instance for connecting to Stream's service
- channel: The specific Stream channel where conversations happen
During initialization, we configure the Anthropic client with your API key, then set up an event listener for new messages in the Stream channel. This line is important:
1this.chatClient.on('message.new', this.handleMessage);
This sets up our event listener to respond whenever a new message appears in the Stream channel. When a user sends a message, Stream triggers the message.new event, which our agent handles:
123456789101112131415private handleMessage = async (e: Event<DefaultGenerics>) => { if (!this.anthropic) { console.error('Anthropic SDK is not initialized'); return; } if (!e.message || e.message.ai_generated) { console.log('Skip handling ai generated message'); return; } const message = e.message.text; if (!message) return; this.lastInteractionTs = Date.now(); // Continue with handling the message... }
Note that we skip processing if:
- The Anthropic client isn't initialized
- The message is AI-generated (to prevent infinite loops)
- The message has no text content
Here's the crucial part where we construct context from the conversation history:
1234567const messages = this.channel.state.messages .slice(-5) // Take last 5 messages .filter((msg) => msg.text && msg.text.trim() !== '') .map<MessageParam>((message) => ({ role: message.user?.id.startsWith('ai-bot') ? 'assistant' : 'user', content: message.text || '', }));
This is the "memory trick" in action. We:
- Access the pre-maintained message history from
channel.state.messages - Take the last five messages
- Filter out empty messages
- Transform them into Anthropic's message format with proper roles
This approach creates the illusion of memory for our AI, allowing it to maintain context throughout the conversation even though each API call is stateless.
Continuing the AI Conversation
Next, we want to send our message array to our LLM. We can leverage threaded conversations for more contextual AI responses:
123456if (e.message.parent_id !== undefined) { messages.push({ role: 'user', content: message, }); }
The parent_id property is provided by Stream's messaging system, allowing us to identify thread replies. This threading capability is built into Stream, making it easy to create more organized conversations with humans and AI.
Now we send the constructed conversation history to Anthropic:
123456const anthropicStream = await this.anthropic.messages.create({ max_tokens: 1024, messages, model: 'claude-3-5-sonnet-20241022', stream: true, });
Notice how we're passing our messages array containing the conversation history. This gives Claude the context it needs to generate a relevant response. We then create a new message in the Stream channel and use Stream's built-in events system to show the AI's response in real-time:
1234567891011121314const { message: channelMessage } = await this.channel.sendMessage({ text: '', ai_generated: true, }); try { await this.channel.sendEvent({ type: 'ai_indicator.update', ai_state: 'AI_STATE_THINKING', message_id: channelMessage.id, }); } catch (error) { console.error('Failed to send ai indicator update', error); }
Stream provides several features we're leveraging here:
channel.sendMessage()for creating new messages- Custom fields like
ai_generatedfor adding metadata to messages channel.sendEvent()for triggering real-time UI updates- Message IDs for tracking and updating specific messages
These capabilities make creating interactive, real-time AI experiences easy without building custom pub/sub systems or socket connections. The AnthropicResponseHandler uses partial message updates to create a smooth typing effect:
123await this.chatClient.partialUpdateMessage(this.message.id, { set: { text: this.message_text, generating: true }, });
Stream's partialUpdateMessage function is particularly valuable for AI applications. It allows us to update message content incrementally without sending full message objects each time. This creates a fluid typing experience that shows the AI response being generated in real time without the overhead of creating new messages for each text chunk.
The run method processes the Anthropic stream events:
1234567891011121314run = async () => { try { for await (const messageStreamEvent of this.anthropicStream) { await this.handle(messageStreamEvent); } } catch (error) { console.error('Error handling message stream event', error); await this.channel.sendEvent({ type: 'ai_indicator.update', ai_state: 'AI_STATE_ERROR', message_id: this.message.id, }); } };
We then see our messages in the client:
If we were to console.log this for the messages above, we’d see:
123456789messages [ { role: 'user', content: 'Are you AI?' }, { role: 'assistant', content: "Yes, I'm Claude, an AI assistant created by Anthropic. I aim to be direct and honest about what I am." }, { role: 'user', content: 'What did I just ask you?' }, { role: 'assistant', content: 'You asked me "Are you AI?"' } ]
And so on for the last 5 messages. By changing .slice(-5), we can increase or decrease the memory of the AI. You might want to adjust this based on your specific needs:
- For simple Q\&A bots, 2-3 messages may be enough
- For complex discussions, you might need 10+ messages
- For specialized applications, you might need to include specific earlier messages
Stream’s memory is much larger. The Channel object provides a convenient state management system through channel.state.messages, automatically maintaining our entire message history. This is a significant advantage of using Stream–you don't need to build your own message storage and retrieval system, and can then just choose the messages to send to AI.
This creates a conversation history that Claude can use to maintain context. We properly format the conversation back and forth by determining whether messages come from a user or an AI bot (based on user ID).
We can test whether the AI is maintaining its own memory of the conversation by taking advantage of the ability to delete messages in Stream:
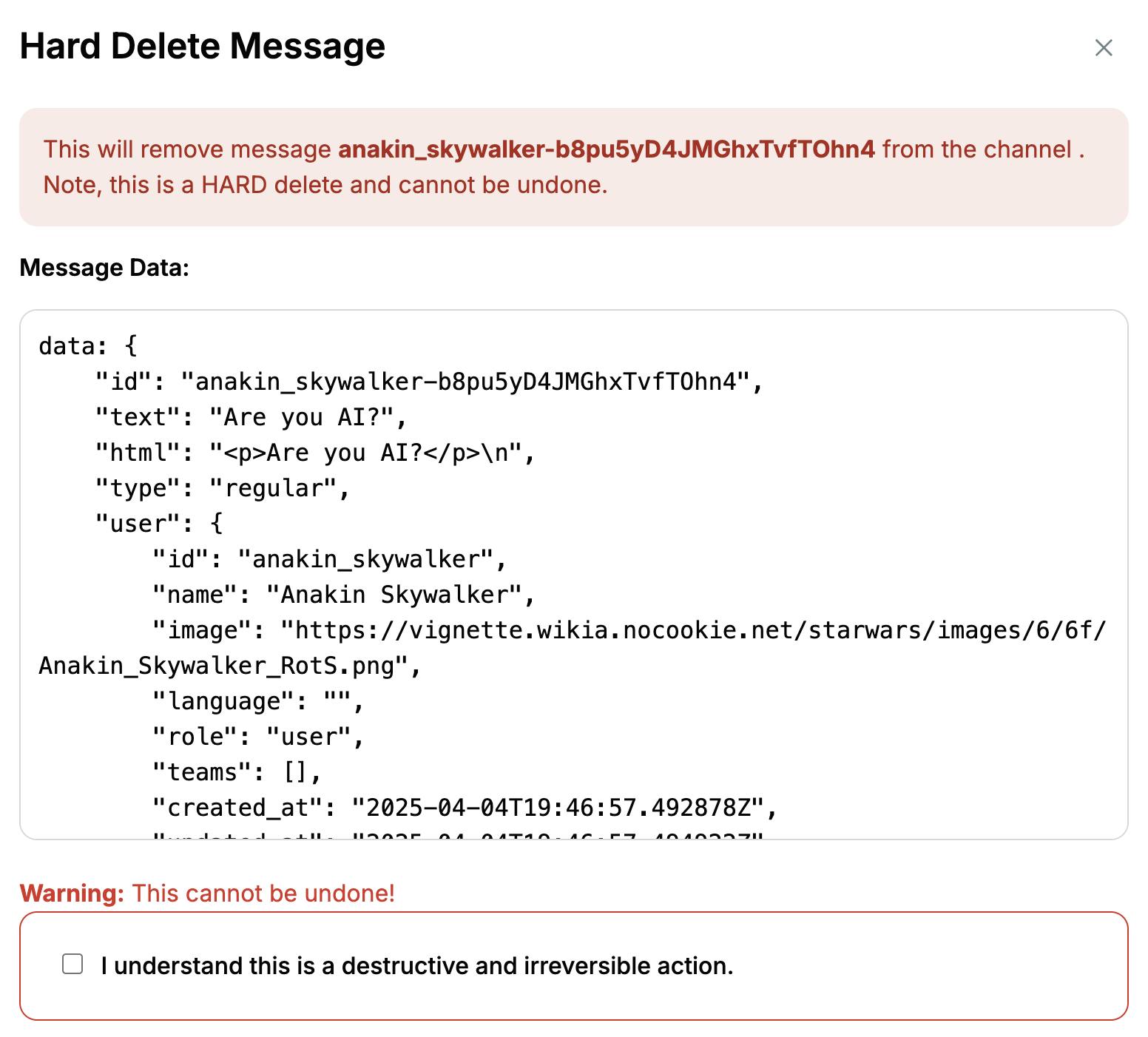
If we then continue in the same message thread, the AI has lost all context:
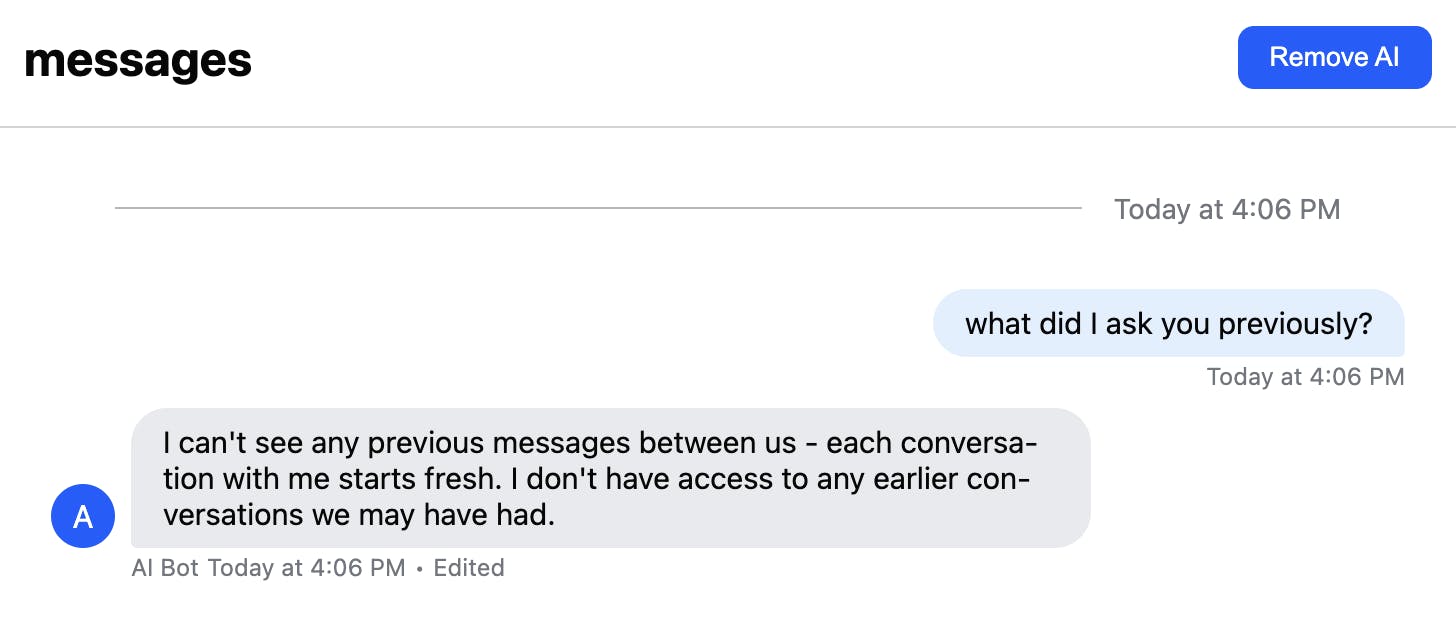
If the LLM were maintaining its history, it would still have access to the previous messages. But as we’ve deleted them in Stream, we can see the API is truly stateless, and only our message “memory” code can allow us to give the AI the context it needs.
Tuning Our Message History Context Window
You can hardcode a message history, such as “5,” to give the LLM the most recent messages. But when you use the chat interface of Claude or ChatGPT, it remembers everything within the current chat. The interface sends all previous messages up to the LLM's maximum context window size.
The context window for an LLM is the maximum amount of text (tokens) that the model can process in a single API call, including both the input (prompt/history) and the generated output.
Instead of hardcoding our message history, we can dynamically decide how much of our history to send by computing whether all the messages will fit within the context window. The context window for Claude 3.5 (the model we’re using here) is 200k tokens.
1234567891011121314151617181920212223242526272829303132333435363738function constructMessageHistory() { const MAX_TOKENS = 200000; // Claude 3.5 Sonnet's limit const RESERVE_FOR_RESPONSE = 2000; // Space for AI's reply const AVAILABLE_TOKENS = MAX_TOKENS - RESERVE_FOR_RESPONSE; // Simple token estimation (4 chars ≈ 1 token for English) function estimateTokens(text) { return Math.ceil(text.length / 4); } // Get all messages in chronological order const allMessages = this.channel.state.messages .filter(msg => msg.text && msg.text.trim() !== '') .map(message => ({ role: message.user?.id.startsWith('ai-bot') ? 'assistant' : 'user', content: message.text || '', tokens: estimateTokens(message.text || '') })); // Work backwards from most recent, adding messages until we approach the limit let tokenCount = 0; const messages = []; for (let i = allMessages.length - 1; i >= 0; i--) { const msg = allMessages[i]; if (tokenCount + msg.tokens <= AVAILABLE_TOKENS) { messages.unshift(msg); // Add to beginning to maintain order tokenCount += msg.tokens; } else { break; // Stop once we'd exceed the limit } } console.log(`Using ${tokenCount} tokens out of ${AVAILABLE_TOKENS} available`); return messages.map(({ role, content }) => ({ role, content })); }
This approach:
- Uses a simple character-to-token ratio (sufficient for getting started)
- Prioritizes recent messages (most relevant to current context)
- Automatically adjusts to different message lengths
- Stops adding messages when approaching the token limit
- Logs usage so you can monitor and adjust as needed
For better accuracy in production, you can replace the estimateTokens function with a proper tokenizer library. Still, this simple approach will get you started with dynamic context management without much complexity.
Fake Your LLM Memories
Implementing the “memory facade” with Stream and Anthropic is relatively straightforward. By leveraging Stream's built-in message history capabilities, we can easily maintain conversation context for our AI agent without building custom storage solutions. This approach eliminates the need to create your own database schema or message retrieval logic, allowing you to focus on the AI experience rather than infrastructure concerns.
Following this pattern, you can create AI chatbot experiences that maintain context over time, making interactions feel natural and coherent to your users. The simplicity of this implementation belies its power–it's the same technique used by major AI platforms to create the illusion of continuous conversation. Yet, it's accessible enough for developers to implement in their applications with minimal overhead.
Stream's built-in message history and event system make this straightforward. Instead of building custom databases and complex state management, developers can focus on unique features rather than infrastructure concerns. As AI continues evolving, this foundation of conversation context remains essential, and with Stream and Claude working together, you can build sophisticated, memory-aware chat applications that feel intelligent and responsive without reinventing the wheel.