Architecture & Benchmark
Architecture Overview
The chat API works for apps with hundreds of millions of users. A few key things about the architecture:
- Edge network: We run an edge network of servers around the world
- Offline storage & optimistic UI updates: The SDKs handle offline storage, and update the UI optimistically, which makes everything fast.
- Excellent performance: Scale to 5m users online in a channel, with <40ms latency
- Highly redundant infra
On the SDKs we provide both a low level client and UI components. This gives you the flexibility to build any type of chat or messaging UI.
Benchmark at a glance
Stream Chat is regularly benchmarked to ensure its performance stays consistent. As you can see in the chart, we are able to connect 5 million users to the same channel.
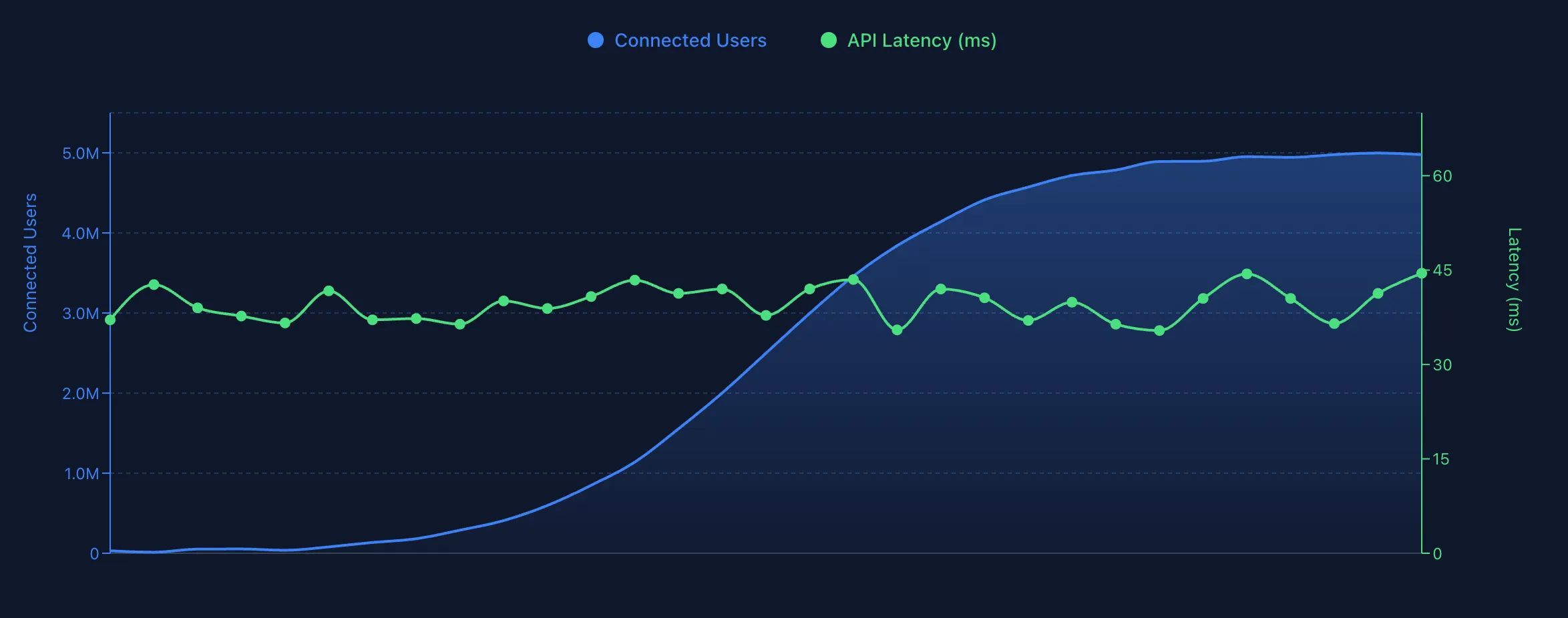
API Latency stays consistent for the benchmark and there is no performance degradation.
The tech behind the Stream chat API
Stream uses Golang as the backend language for chat.
Edge network
When using Stream API, the end-user connects to the nearest API edge server, this is similar to how CDN works but it is more sophisticated than that.
Edge servers support HTTP/3 and HTTP/2 when available. TLS termination is done at the edge, reducing the handshake time. Traffic between edges and origin servers is fully encrypted and we use long-lived HTTP/2 connections to ensure best latency.
API authentication, rate-limiting and CORS requests are also performed at the edge.
For increased resilience we also build circuit breakers, API request retry mechanism, consistent hash routing and locality-aware load balancing with fallback to other AZs if necessary to our edge infrastructure.
Websockets
To get to 5m concurrent online users on a single channel we have a few optimizations in place. First we use cuckoo filters to have a quick way to check if a user might be online on a given server. There are also optimizations in place with skip lists and smart locking to prevent slowdowns at high traffic.
Deflate compression is negotiated with API clients to minimize event payloads, vectored I/O using the writev syscall is leveraged to optimize the delivery of WS events to many clients.
We extensively use sync.Pool to minimize GC pressure and implement our own reference-counted messages that allow us to serialize once and deliver to many clients via atomic ref counting (zero-copy cloning).
Long-polling fallback mechanism: sometimes users connect from networks that do not handle websockets well, in that case we automatically fallback to the old-school HTTP long-polling connection mechanism to retrieve real-time events.
API performance
The API often responds in <50ms. This is achieved using a combination of denormalization, caching and Redis client-side caching.
Commonly accessed entities like users, channels and messages are heavily cached on the API memory directly as well as in Redis, using a cache-flow pattern.
Redis ZSET and HSET are used to replicate some data structures and have a lock-free/atomic write path (eg. updating user.last_active_at).
Redis cluster is used to store terabytes of data and scale horizontally. Lua scripting is used to have atomicity and consistency for data stored across multiple keys.
Redis client-side caching is used to synchronize in-memory caches across different servers/processes.
Offline storage and Optimistic UI
All SDKs come with offline storage and optimistic UI support. This allows the UI to always feel very responsive and snappy even if the user is on a very slow network.
When the SDK starts, it instantly loads existing channels and messages from offline storage and runs a synchronization task in the background to fetch all deltas like new/updated/deleted messages, users and channels. This guarantees great startup performance and makes it possible to perform optimistic UI updates without the risk of data-loss.
Optimistic UI: when a user sends a message, the message shows in the UI instantly without waiting for network requests to complete. The SDK takes care of sending the request to the API and performs all the asynchronous work with the offline storage.
The offline storage uses the best database tech available for each platform: Core Data on iOS, Room (Jetpack) on Android and SQLite for React Native and Flutter.
Members & Limits
There are no limits on the number of concurrent users, the number of members, the number of messages or the number of channels.
Performing read operations with stable performance requires careful data denormalization to avoid joining/ordering large amounts of data.
Infra & testing
There is a large Go integration test suite, a set of smoketests in production and a JS QA suite. Sometimes things can slip through, but in general this approach is very effective at preventing issues.
The infra runs on AWS and is highly available.
Benchmark
We built an extensive benchmark infrastructure to measure the scalability and performance of our API. Performing realistic benchmarks at large scale is a small challenge on its own that we solved by building our own distributed system with separate control-plane, workers and data plane to run large workloads and capture all relevant telemetry from probes.
The benchmark result up to 5m users can be found here https://getstream.io/blog/scaling-chat-5-million-concurrent-connections/