Voice Activity Detection (VAD)
Voice Activity Detection (VAD) automatically identifies when human speech is present in an audio stream, distinguishing it from background noise, silence, or other non-speech sounds. It enables applications to process audio more efficiently by focusing computational resources only on segments that contain actual speech, improving both performance and accuracy of voice-based features.
How does voice activity detection work?
Here’s what happens when audio flows through a VAD system:
Audio Input: Raw audio data enters the VAD system for processing.
AI VAD Model: The audio is processed through an AI model that contains the core VAD engine.
AI VAD Engine: This engine performs three key functions:
- Audio Understanding: Analyzes the audio stream for patterns and characteristics that indicate human speech
- Pattern Recognition: Uses neural processing to distinguish human speech from background noise, music, or silence
- Decision Making: Makes real-time decisions about whether speech is present, often with configurable sensitivity levels
Speech Detection: The final output indicates whether speech has been detected or not.
Modern VAD systems learn directly from audio data, making them incredibly accurate at distinguishing speech from various types of background noise, even in challenging environments.

How does it work with Stream?
Instead of building complex audio analysis pipelines, with the Stream Python AI SDK you get a streamlined system that handles all the detection logic for you.
Here’s how it works in your Stream calls:
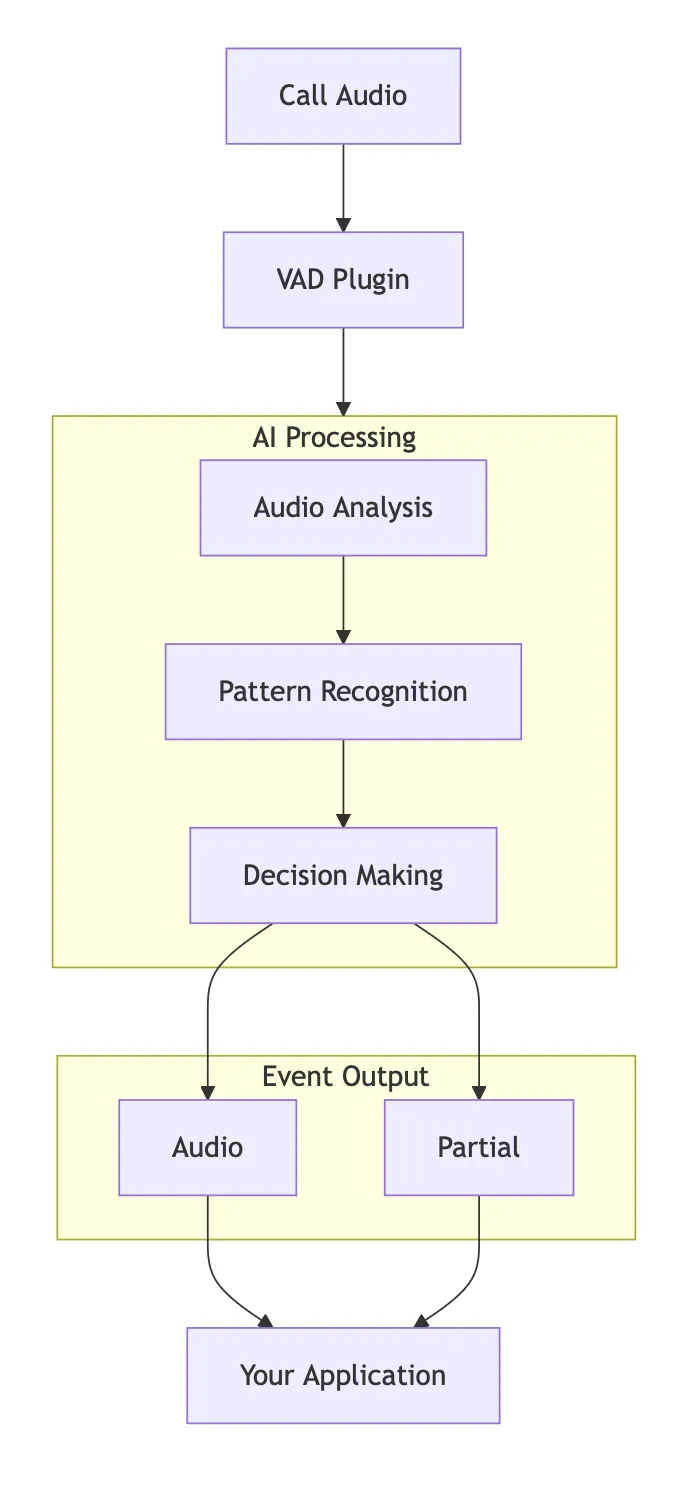
Call Audio: Audio from your Stream video call enters the system.
VAD Plugin: The VAD plugin processes the incoming audio through the AI processing pipeline.
AI Processing: The system performs three key functions:
- Audio Analysis: Analyzes the audio stream for speech patterns
- Pattern Recognition: Identifies speech characteristics and distinguishes them from noise
- Decision Making: Determines when speech starts and stops
Event Output: The system generates two types of outputs:
- Audio: Processed audio data when speech is detected
- Partial: Partial results or intermediate processing data
Your Application: Your application receives both the processed audio and partial data to respond appropriately—starting transcription, managing conversation flow, or optimizing performance.
Worked example
Let’s walk through a real-world scenario to see how VAD transforms your application’s intelligence.
Imagine you’re building a smart meeting assistant that automatically transcribes conversations. Here’s how VAD makes this system work efficiently:
The Scenario: A team meeting with 6 participants in a room with some background noise.
What Happens:
The VAD system continuously monitors all audio from the call, analyzing patterns in real-time.
When someone starts speaking, VAD immediately detects the speech and triggers an “audio” event.
Your application receives this event and starts the transcription process only for that speaker, saving resources by not processing silence or background noise.
Your application can then finalize the transcription for that segment and prepare for the next speaker.
Throughout the meeting, VAD helps manage conversation flow by identifying when different people are speaking, enabling features like speaker identification and turn management.
This is just one example—VAD can optimize any application that needs to understand when people are speaking.
What can you do with it?
The possibilities with VAD are incredibly practical! Here are some of the most valuable ways you can use it to make your applications smarter and more efficient:
Intelligent Transcription
Only transcribe audio when someone is actually speaking, saving processing power and improving accuracy. Create more efficient transcription systems that focus on meaningful content.
Conversation Management
Detect when different people are speaking to manage turn-taking, identify speakers, or create more natural conversation flows in your applications.
Audio Processing Optimization
Save computational resources by only processing audio during speech segments. Reduce costs and improve performance in applications that handle large amounts of audio data.
Noise Reduction and Filtering
Automatically filter out background noise, music, or other non-speech audio to improve the quality of your audio processing pipeline.
Real-time Analytics
Track speaking patterns, measure participation levels, or analyze conversation dynamics in meetings, calls, or interactive sessions.
Accessibility Features
Create applications that respond to voice commands more reliably by only listening when someone is actually speaking, reducing false triggers and improving user experience.
Recording and Archiving
Automatically start and stop recordings based on speech activity, creating cleaner audio files that focus on actual conversation content.