Speech To Text (STT)
Speech-to-Text (STT) converts spoken audio into structured text data that enables your applications to process and understand human speech input.
How does speech to text work?
- Capture audio
- Recognize speech patterns
- Convert to text

How does it work with Stream?
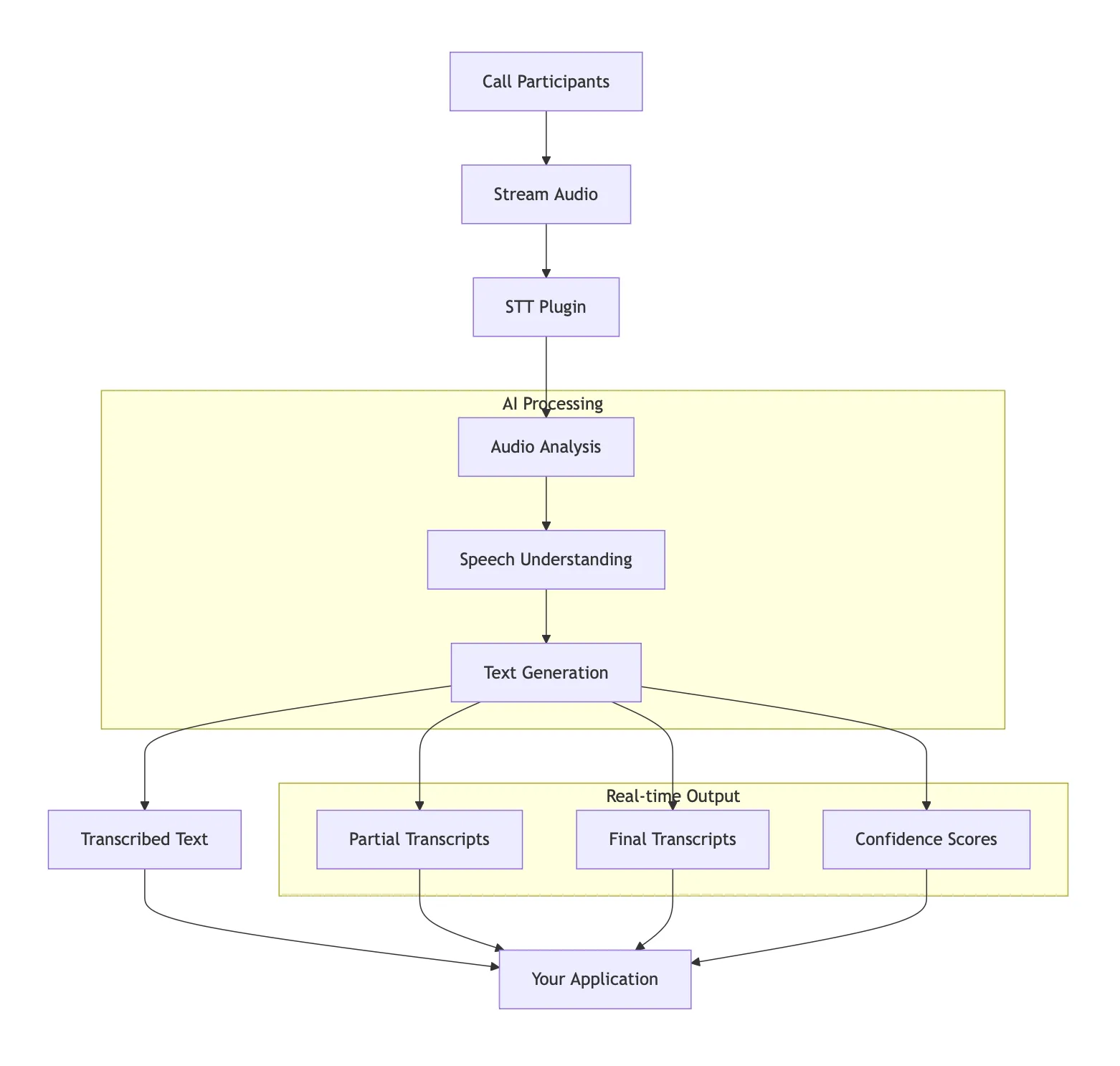
The Stream Python AI SDK simplifies real-time speech recognition. It handles the whole pipeline, from audio capture to text output.
Here’s how it works in your Stream calls:
Choose Your Provider: Pick from powerful STT services like Deepgram (for high accuracy and multiple languages) or Moonshine (for fast, local processing).
Listen to Audio: The SDK automatically captures audio from your Stream call and feeds it to your chosen STT provider in real-time.
Get Live Transcripts: As people speak, you receive live transcripts.
Process the Text: Use the transcribed text however you need: store it, analyze it, or feed it to other AI systems for further processing.
Real-time Integration: The entire process happens seamlessly within your existing Stream call.
Worked example
Let’s walk through a real-world scenario to see how STT transforms your application experience.
Imagine you’re building a meeting assistant that automatically creates meeting notes and action items. Here’s how STT makes this possible:
The Scenario: A team meeting with 5 participants discussing a new product launch.
What Happens:
As each person speaks, the STT system captures their audio and converts it to text in real-time.
You receive transcript events after each utterance such as “We need to launch the new product by Q3”.
Your application can immediately process this text to identify key topics, extract action items, or trigger follow-up tasks.
When someone says “I’ll handle the marketing campaign,” your system can automatically create a task assignment.
At the end of the meeting, you have a complete, searchable transcript that captures every detail discussed.
The Result: You get a comprehensive, accurate record of the entire conversation that can be analyzed, searched, and acted upon.
STT can transform any voice interaction into actionable data.