Architecture & Benchmark
Architecture Overview
APIs should scale with your growth, both from a tech and pricing perspective. Here we explain the architecture that allows the activity feed API to scale to apps with hundreds of millions of users.
Activity feeds are notoriously hard to scale. When you follow users or other areas of interest you create a feed that's unique to you. At scale this means it's hard to distribute the load across servers.
Benchmark at a glance
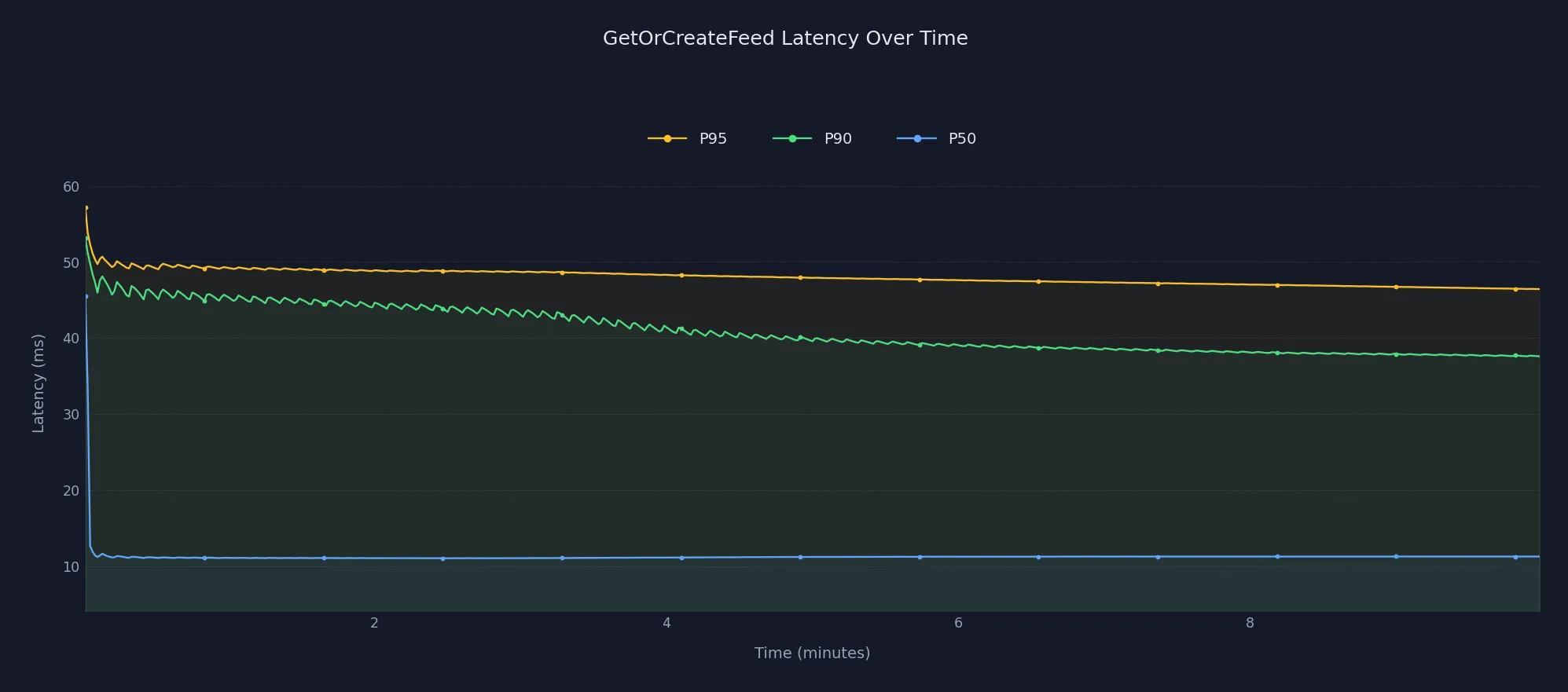
Stream Activity Feeds is regularly benchmarked to ensure its performance stays consistent. As you can see in the chart below, latency remains extremely fast and stable even at 100M users (~11ms p50).
We'll cover the following topics to show how Stream achieves this performance:
- Tech deep dive / architecture
- Benchmark results
- For you style personalization
The tech behind the Stream Activity Feeds API
Stream uses Golang as the backend language for activity feeds. Go is an extremely good fit for activity feeds. It handles aggregation, ranking, push and websockets very well. The websocket implementation uses cuckoo filters, so it has a lightweight way to validate if a user is active on a given server.
Push/Pull & Fanout - Materialized Feed
Activity feeds are typically powered using push (fanout on write) or pull (fanout on read). As we started building feeds we worked through many iterations of pull and push based architectures on various databases. We've found the best results come from using a combination of these approaches and building what we call a Materialized Feed.
| Aspect | Push (Fanout on Write) | Pull (Fanout on Read) | Materialized Feed |
|---|---|---|---|
| Write cost | High - copies to all followers | Low - single write | Low - single write with selective updates |
| Read cost | Low - feed is precomputed | High - aggregates at read time | Low - precomputed with delta fetching |
| Celebrity problem | Severe - millions of writes per activity | None | Handled - prioritizes active feeds |
| Inactive users | Wasteful - updates feeds never read | Efficient | Efficient - skips inactive feeds |
| Read latency | ~1-5ms | ~100-500ms+ | ~10ms |
| Storage | High - duplicated across feeds | Low - single copy | Medium - smart deduplication |
| Consistency | Eventual (fanout delay) | Strong | Near-real-time with delta sync |
| Best for | Small follower counts, read-heavy | Write-heavy, few reads | General purpose, large scale |
The materialized feed combines the read performance of push with the write efficiency of pull. It achieves this by selectively updating feeds based on user activity patterns rather than blindly fanning out to all followers.
The concept of the materialized feed is similar to what a database does when creating a materialized view. If a user follows 100 other users it will take these activities and store them. The next time you open your feed it will fetch the changes/delta of new activities by those users. There are a few clever tricks that speed it up:
- In most apps many users/feeds are inactive. The algorithm for updating feeds prioritizes recently active feeds
- As it builds the top X items in the feed in a heap, it keeps track of which feeds don't have recent enough content / can't contribute to this feed
- At first we used RocksDB/raft for this. The most recent iteration uses TiKV, which is a slightly higher level of abstraction than RocksDB. TiKV is nice since it's low level enough that you can reach excellent feed performance, but high level enough that you don't have to deal with the complexities of building multi-raft clusters (and rebalancing).
- Column denormalization. The fields used for ranking or aggregation are denormalized. This allows you to rank feeds before loading the full activity
The end result is a feed that can load in less than 10ms.
Client Side Caching & Cache Stampede Protection
We use Redis client side caching for optimal performance. For high traffic feeds, this client side caching approach saves you a roundtrip to Redis. A combination of ristretto and singleflight help prevent cache stampedes.
Filtering
Many social apps allow some level of filtering on your activity feed. For instance only showing images, or only videos, or only posts in a certain language. To enable filtering and also keep the activity feed fast, we create a temporary materialized feed for your filter pattern. So if you filter on all posts tagged with english, we'll build up a materialized feed with just the english posts.
To ensure that it's possible to build up this feed with the best possible performance we've put a few constraints in place. At read time you cannot specify more than 10 tags. You can filter on equal or IN, but you are not allowed to use "not in". This ensures the filtered feed runs at a performance level that's very close to a regular feed.
Aggregation & Ranking
Aggregation keys are precomputed on write. This ensures that opening up an aggregated feed is extremely fast.
Ranked feeds are more dynamic in nature and can't be precomputed. Feeds includes a fast expression parsing library that enables us to rerank feeds quickly.
Infra & testing
An extensive test suite, monitoring and production smoke tests ensure a high uptime. (100% over the last 12 months at the time this was written.) We also offer a 99.999% uptime SLA with acceleration.
Benchmark
We built an extensive benchmark infrastructure to measure the scalability and performance of our API. Performing realistic benchmarks at large scale is a small challenge on its own that we solved by building our own distributed system with separate control-plane, workers and data plane to run large workloads and capture all relevant telemetry from probes.
Methodology
The benchmark has been set up to simulate an app with 100 million users with the following assumptions:
- 10-30% daily active users
- Peak concurrent users (PCU): 5-15% of daily active users
This leads to the following 3 scenarios being simulated:
- Low estimate: 500k peak concurrent users (10% DAU, 5% PCU)
- Medium estimate: 2M peak concurrent users (20% DAU, 10% PCU)
- High estimate: 4.5M peak concurrent users (30% DAU, 15% PCU)
The timeline feed group was set up with a single following activity selector. This so the benchmark imitates the v2 API behavior and make the results comparable across API versions.
Results
The benchmark processed over 37 million operations with a 10% write / 90% read workload distribution across a dataset of 100M users, 500M activities, and 200M follow relationships. Each scenario was tested at 500, 1000, and 1500 requests per second to measure performance under increasing load.
500K Peak Concurrent Users (Low)
| RPS | Read Latency (p50) | Write Latency (p50) | Read Latency (p99) | Write Latency (p99) | Success Rate |
|---|---|---|---|---|---|
| 500 | 14.33ms | 29.53ms | 68.31ms | 44.20ms | 100% |
| 1000 | 14.67ms | 29.11ms | 62.35ms | 44.76ms | 100% |
| 1500 | 15.10ms | 30.38ms | 62.13ms | 52.81ms | 100% |
2M Peak Concurrent Users (Medium)
| RPS | Read Latency (p50) | Write Latency (p50) | Read Latency (p99) | Write Latency (p99) | Success Rate |
|---|---|---|---|---|---|
| 500 | 14.94ms | 29.87ms | 73.14ms | 45.73ms | 100% |
| 1000 | 14.96ms | 30.13ms | 71.59ms | 52.17ms | 100% |
| 1500 | 15.11ms | 30.67ms | 83.04ms | 68.04ms | 100% |
4.5M Peak Concurrent Users (High)
| RPS | Read Latency (p50) | Write Latency (p50) | Read Latency (p99) | Write Latency (p99) | Success Rate |
|---|---|---|---|---|---|
| 500 | 14.89ms | 30.13ms | 73.10ms | 45.95ms | 100% |
| 1000 | 14.97ms | 30.53ms | 76.04ms | 52.46ms | 100% |
| 1500 | 15.30ms | 31.40ms | 135.84ms | 134.02ms | 100% |
Key takeaways:
- Read latency stays consistent at ~15ms p50 regardless of user scale or RPS
- Write latency remains under 32ms p50 across all scenarios
- 100% success rate maintained even at 4.5M concurrent users and 1500 RPS
- p99 latency remains stable up to 1000 RPS; at 1500 RPS with 4.5M users, tail latency increases but still stays under 140ms
For You Feeds & Personalization
A for you style feed is key for user engagement. Out of the box we ship with the following activity selectors:
- Following
- Popularity
- Location
- Interest
- Activities from people in your follower suggestions
- Query activities (anything you can query on)
You can add up to 10 different ways to select activities and rank the end result with any of our ranking methods.
You can also enrich activities as they are added. The AI/LLM based enrichers can add topics for further improvements to interest based ranking.
We're always expanding the list of built-in capabilities for ranking / for you style feeds. Be sure to reach out if you have suggestions.
Transparency & Tech
When you select an API you want to know it can scale and will be reliable. So instead of just claiming that Stream works for large apps, we like to share these details on how we achieve the performance and scalability. If you'd like to learn more about Stream be sure to check out the docs or contact our team.