Blocklists and Regex Filters
Moderation supports several types of filtering:

Configuration
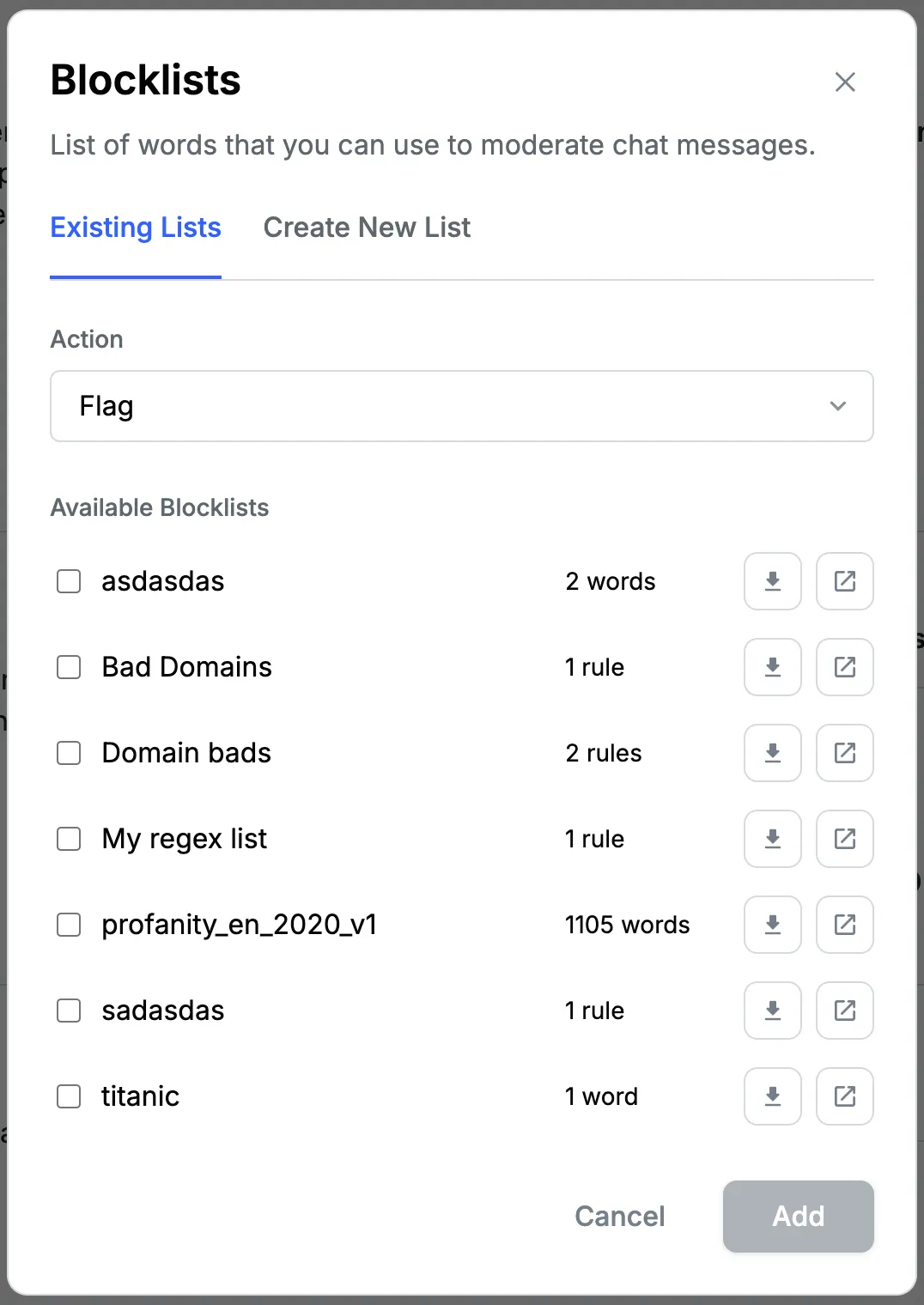
To create a blocklist, simply press the "+ Add New" button under the "Block Lists and Regex Filters" section.
Here you can either assign any existing blocklist (which you may have created in the past) to the current policy, or you can create a new blocklist and assign it to the current policy.
Stream provides a built-in blocklist called
profanity_en_2020_v1, which contains over a thousand of the most common profane words.
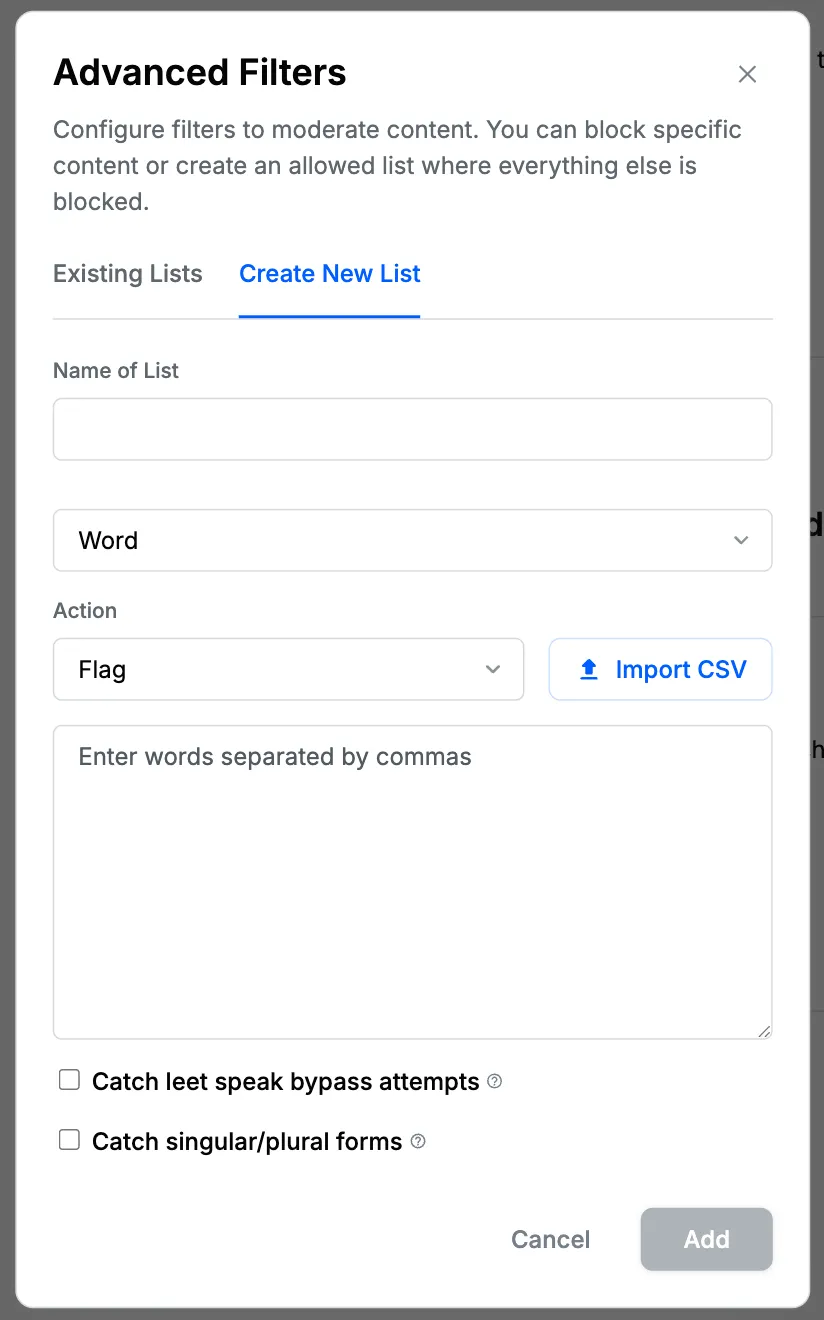
To create a new blocklist:
- Give your blocklist a name.
- Choose the type of blocklist you want to create: Word, Regex, Email, Domain.
- Add words/regex/emails/domains you want to block.
- For Word blocklists, optionally enable advanced detection features:
- Catch leet speak bypass attempts: Detects common character substitutions of blocked words.
- Catch singular/plural forms: Detects singular/plural variations of blocked words.
- Choose the action to be taken when content matches these words/regex/emails/domains: Flag, Block, Shadow Block.
- Click "Add" to activate your new blocklist.
Word filters (aka Blocklists)
- Regular blocklists support filtering of single words.
- Whitespace, punctuation, and partial matches are not supported. Only exact matches will be filtered.
However, the matching is case-insensitive, and content containing blocklist words with adjacent punctuation, i.e., a period or a comma, will match.
For example, a blocklist consisting of the words: dogs, house, woman
Will match content like:
The woman walks the street.- matching woman
I live in a house.- matching house, regardless of the adjacent period
Dogs, are a man's best friend- matching dogs, regardless of upper-case D and adjacent comma
Will not match content like:
I live in a lighthouse- won't partially match house in lighthouse
Advanced Detection Options
When creating a word blocklist, you can enable the following advanced detection features:
- Catch leet speak bypass attempts: Detects common character substitutions (e.g., h4ck3r instead of hacker) of blocked words.
- Catch singular/plural forms: Detects singular/plural variations of blocked words (e.g., cat and cats).
When the Catch singular/plural forms option is enabled, the blocklist will also match:
They live in big houses- matching houses (plural of house)
The dog is sleeping- matching dog (singular of dogs)
When the Catch leet speak bypass attempts option is enabled, the blocklist will also match:
What breed is your d0g?- matching d0g (leet speak for dog)
I know this w0m@n- matching w0m@n (leet speak for woman)
Domain Blocklist Filters
Domain blocklist filters support the filtering of domains by partially matching the suffix of URLs found in the content. When a domain is added to the blocklist, any content containing that domain will be blocked.
The URL scheme, e.g., http or https, or any part of the URL after the domain name is ignored.
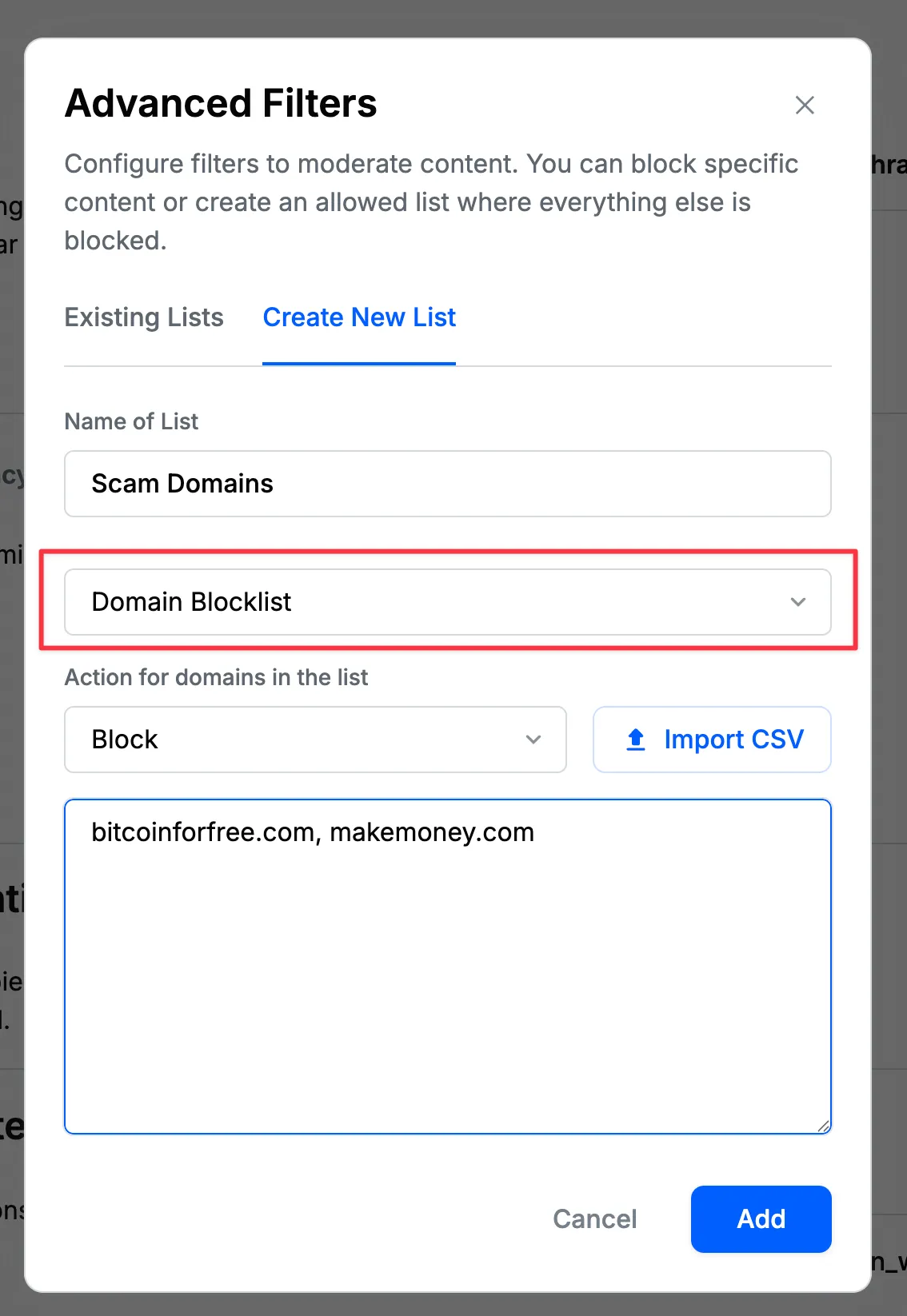
For example, a domain blocklist filter such as gmail.com, will match:
http://www.gmail.com/https://gmail.com/index.htmlhttp://support.gmail.com/docs?language=englishhttps://yet.another.subdomain.gmail.com/
Note: For convenience, a domain filter like www.gmail.com will match both* http://www.gmail.comand http://gmail.com
A more narrowed-down domain filter containing one or more sub-domains, such as messenger.facebook.com, will match:
https://messenger.facebook.com/index.htmlhttp://download.messenger.facebook.com/
But won't match:
http://facebook.com/http://www.facebook.com/index.html
Domain Allowlist Filters
You should never use a domain whitelist filter in conjunction with a domain blocklist filter, since it may not produce the desired results.
Domain allowlist filters work in the opposite way of domain blocklists. When using a domain allowlist, you specify which domains are allowed, and any content containing domains that are not in the allowlist will be blocked.
This is particularly useful when you want to:
- Restrict URLs to a specific set of trusted domains
- Block all domains except for a few approved ones
- Create a more restrictive environment where only certain domains are permitted
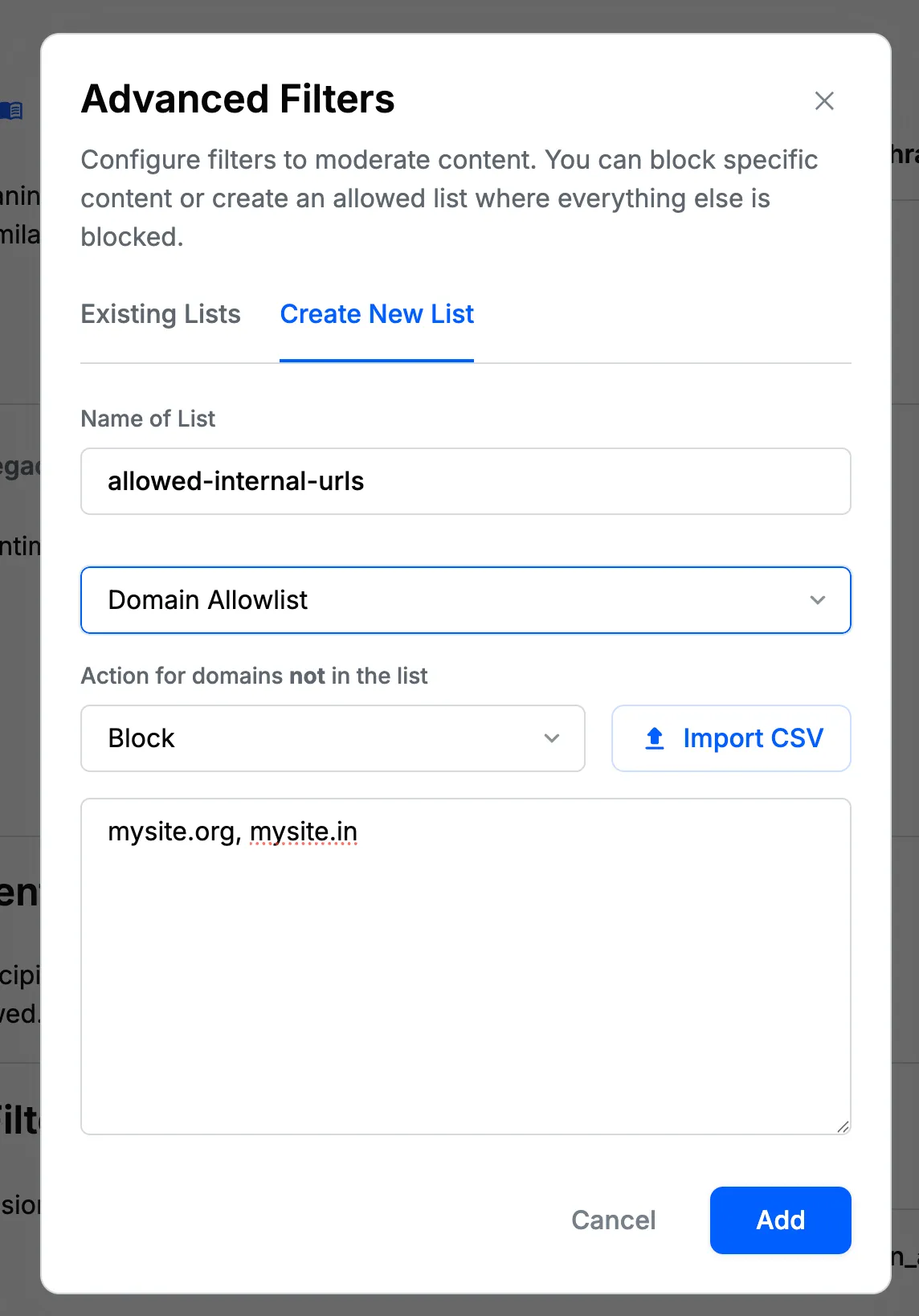
The matching rules for whitelisted domains follow the same pattern as domain blocklists. For example, if trusted-domain.com is in the allowlist:
Will allow:
http://trusted-domain.comhttps://www.trusted-domain.comhttps://subdomain.trusted-domain.com
Will block:
- Any URLs containing domains not in the allowlist
- Any content with links to non-allowlisted domains
Email Blocklist Filters
Email blocklist filters support the filtering of email addresses by matching exact email addresses. When an email address is added to the blocklist, any content containing that exact email address will be blocked.
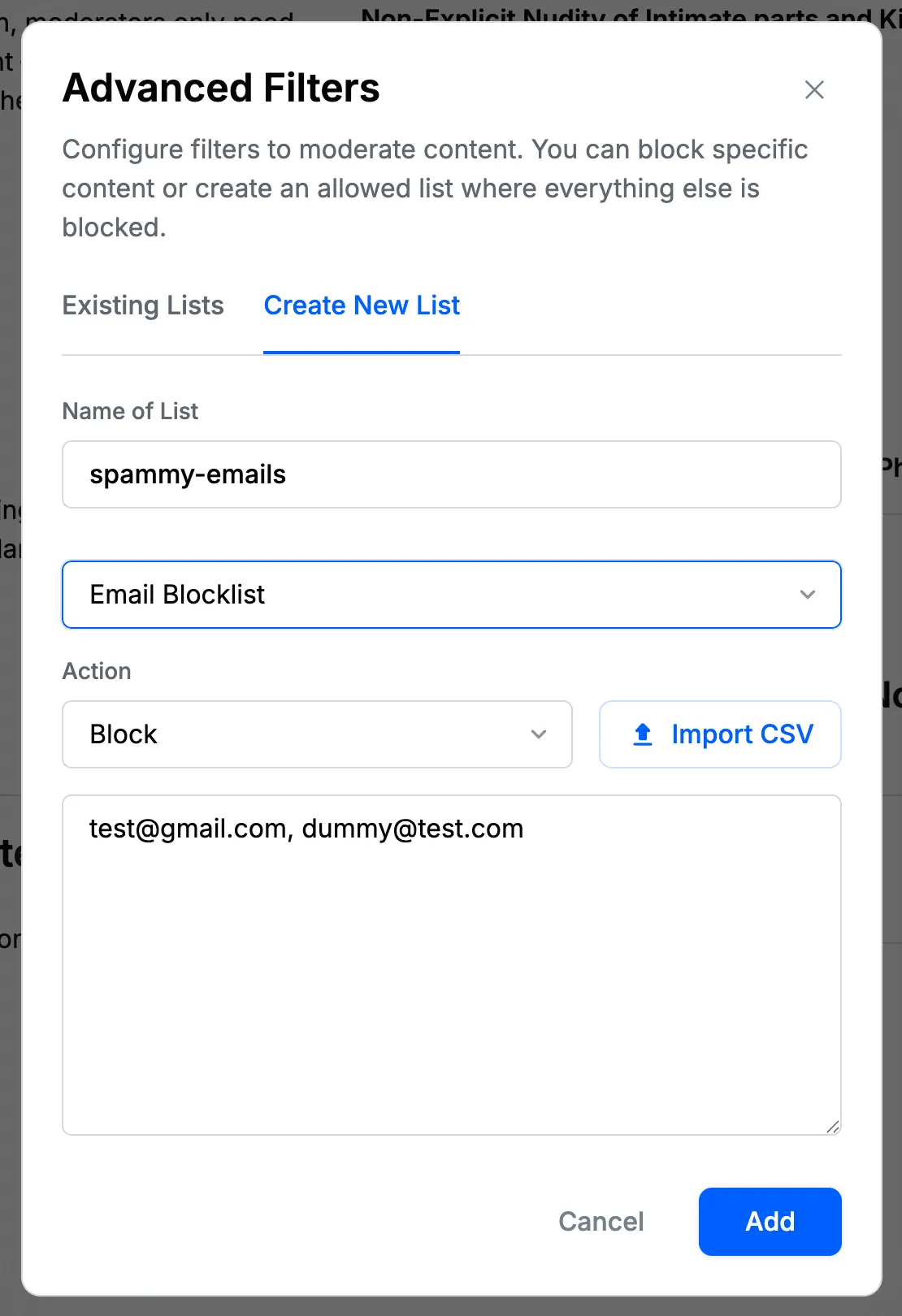
The filter matches exact email addresses only. For example, an email blocklist filter such as spam@example.com, will match:
- Content containing the exact email address
spam@example.com
But won't match:
other@example.com(different username)spam@different.com(different domain)- Any other email addresses
Note: Email blocklist filters work on valid email addresses only. To filter domains in URLs, use Domain Blocklist Filters instead.
Email Allowlist Filters
You should never use an email allowlist filter in conjunction with an email blocklist filter, since it may not produce the desired results.
Email allowlist filters work in the opposite way of email blocklists. When using an email allowlist, you specify which email addresses are allowed, and any content containing email addresses that are not in the allowlist will be blocked.
This is particularly useful when you want to:
- Block all email addresses except for a few approved ones
- Create a more restrictive environment where only certain email addresses are permitted
- Restrict email sharing to a specific set of trusted email addresses
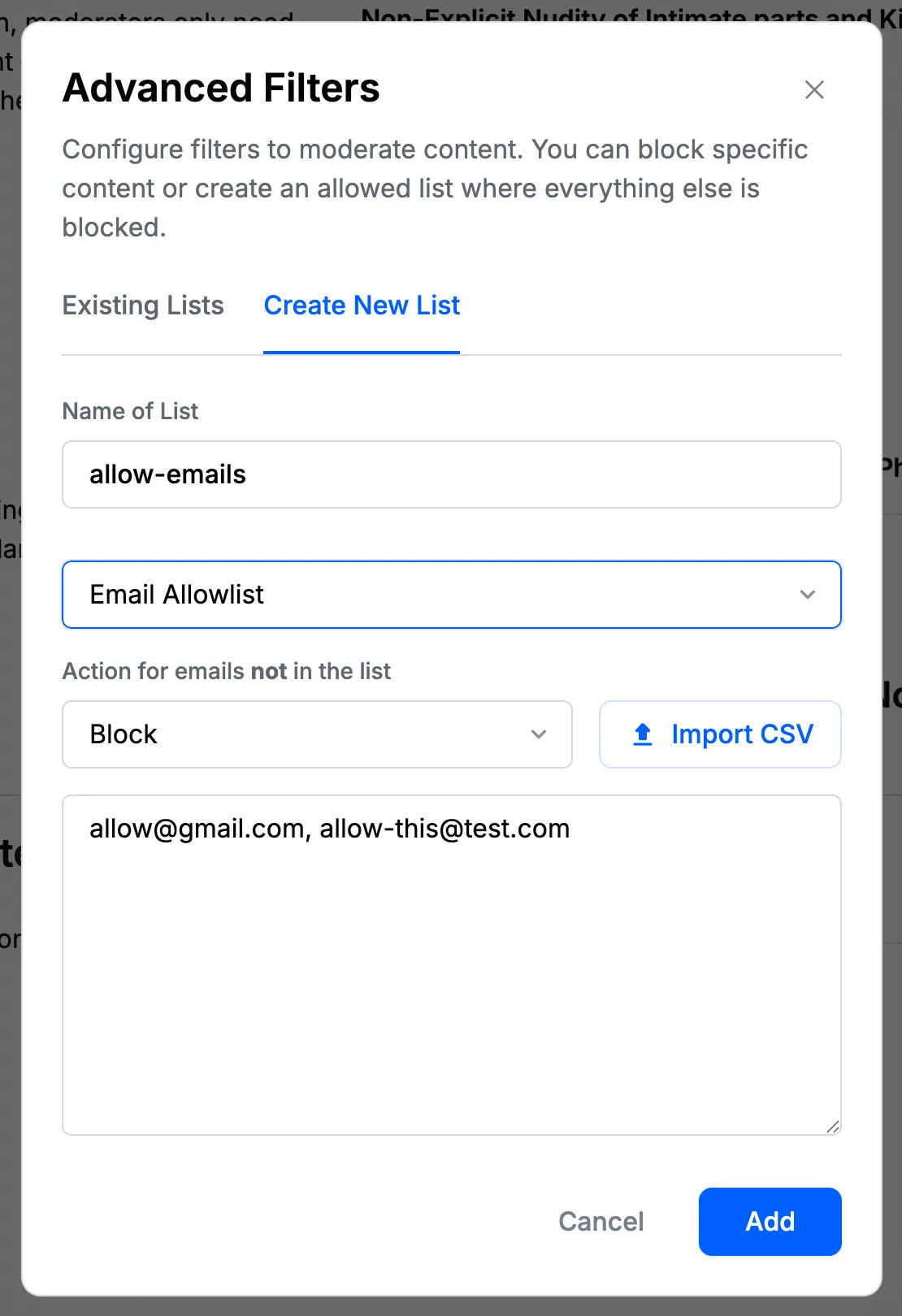
The filter matches exact email addresses only. For example, if a specific email address like info@getstream.io is in the allowlist:
Will allow:
- Content containing the exact email address
info@getstream.io
Will block:
- Any other email addresses, including
support@getstream.ioor emails from other domains - Any content with email addresses not explicitly in the allowlist
Note: Email allowlist filters work on valid email addresses only. To filter domains in URLs, use Domain Allowlist Filters instead.
Regex Filters
Regular Expression Filters empower users to create custom filters by defining rules based on complex patterns. Unlike traditional blocklists, regex filters allow for precise and versatile matching of textual input. Here are best practices and considerations to maximize the effectiveness of your regex filters. Our regex filters work by pattern-matching, enabling users to define rules that go beyond simple word matching found in regular blocklists. By controlling regular expressions, users can capture nuanced patterns in the text, providing a high level of customization.
When creating regex filters, keep the following considerations in mind to ensure optimal performance.
For example, a regex filter such as (?i)stream, will match:
best chat company provider in the world is getstream for sure!I heard strava started using stream's chat messaging systemI will StReaM my gaming content tonight on twitchstream's ai moderation feature is neat
Considerations when building regex filters
- Expression Clarity: Crafting regex expressions should prioritize clarity to avoid confusion. Complex or overly cryptic expressions may be challenging to understand and maintain. Aim for expressive yet concise regex patterns.
- Handling Variable Length Text: Regex filters can efficiently handle variable-length text, making them suitable for scenarios where the length of the matched content may vary. This flexibility allows for capturing diverse patterns within the content.
- Managing Escaping Characters:
Special characters within regex patterns require escaping with
\prior to them to ensure accurate matching. Special characters that require escaping are:.,+,*,?,^,$,(,),[,],{,},|,\To match a character having special meaning in regex, an escape sequence prefixed with a backslash (\) is needed. For example,\.matches".", regex\+matches"+", and regex\(matches"(". To escape\, the same principle applies, meaning\\ - Balancing Specificity and Generality:
Achieving the right balance between a specific and general regex pattern is crucial. Overly specific patterns may miss variations, while overly general patterns may result in false positives. Broad regex rules like
.*(match all characters),.a(match all "a" characters), andah*(will match both "a" and "ahhhhh") can increase the chances of matching false positives due to the fact that.a, for example, will match all words containing the letter "a". - Optimizing for Performance:
Complex regex patterns may impact processing speed. The more knowledge around the data that is being searched through, the better the ability to optimize the regex for performance and success criteria. Consider the following tips as general guidelines when optimizing the regex rules:
- Order of alternations:
- Place the most likely regex matches first. For example, if web address domains are to be matched, instead of
\.(?:biz|net|com)\b,\.(?:com|net|biz)\bshould be used, ascomwill be the most likely match from the list.
- Place the most likely regex matches first. For example, if web address domains are to be matched, instead of
- Usage of anchors:
- Anchors should be used when possible, particularly at the start and end of line or string anchors. The beginning and end-of-string anchors
^and$can save your regex a lot of backtracking in cases where the match is bound to fail. If the entire string does not match the pattern, and the anchor characters indicate the pattern must be found at the beginning or end, then the regex engine can quickly "fail" if the expected pattern is not found at the anchor position. Example:^(?:word1|word2)is preferred to^word1|^word2
- Anchors should be used when possible, particularly at the start and end of line or string anchors. The beginning and end-of-string anchors
- Usage of non-capturing groups:
- Groups multiple tokens together without creating a capture group.
- Lazy quantifiers:
- Greedy quantifiers can be safely replaced using lazy quantifiers which gives the regex a performance boost without altering the result. Greedy Quantifier (
*):- Matches as much as possible.
- May lead to backtracking if the subsequent part of the pattern doesn't match immediately.
Lazy Quantifier (
*?): - Matches as little as possible.
- Tries to satisfy the overall pattern with minimal consumption.
- In scenarios where the matched content is relatively small or close to the beginning of the text, using a lazy quantifier can avoid unnecessary processing and potentially result in faster regex execution.
Example: let's say a spam post
Heyyyyyyyyyyyy! Check out this amazinggggggggggg offer!!!!!!has been posted a lot, trying to bypass the filters by adding moreyyyyyyandgggggg.- Greedy:
(.)\1+- will match "yyyyyyyyyyy" and "ggggggggggg" - Lazy:
(.)\1+?- will match "yy" and "gg" By using the lazy quantifier, unnecessary flagging of longer repeated sequences can be avoided, making the spam detection more precise and less prone to false positives.
- Greedy:
- Greedy quantifiers can be safely replaced using lazy quantifiers which gives the regex a performance boost without altering the result. Greedy Quantifier (
- Order of alternations:
Building Effective Custom Regex Filters
- Specific Patterns and Context:
Develop regex filters with specific patterns in mind, tailoring them to focus on distinct content types or language patterns that are pertinent to your community. Examples include:
\bprofit\b: Matches the word "profit" as a whole word.@[A-Za-z0-9_]+: Matches Twitter-like usernames.(?i)hate: Matches the word "hate" (case insensitive). Strive for patterns that align with specific use cases, which can lead to effectively capturing potential violations.
- Exploring Variations with Regex:
Regex filters provide flexibility to account for variations in content. Include variations in your regex rules to enhance coverage. For example:
(earn|make) money fast(\d{1,3},)*\d{3}: Matches numbers with or without commas (e.g., 1,000 or 1000).
- Combine with other Filters or Harm Engines: Enhance your filtering strategy by combining regex filters with some of our other filters. This allows addressing a broader range of content while maintaining precision. For instance, specific words, emails, or domains can be added to the Advanced Filters in conjunction with regex rules, or any of our harm engines in combination with well-crafted regex patterns will significantly increase the number of moderated items.
For any assistance or questions regarding configuring and optimizing regex filters, feel free to reach out to our support team.