AI Text Harm Detection (LLM)
This engine harnesses the power of LLMs to detect harmful content not just by scanning abusive words, but by understanding the context of the content and the intent of the user.

- Describe in plain language what you want the system to detect, and the engine will handle the rest.
- Share context about your application so the LLM can better understand the context in which users are interacting.
- Moderation considers both the message and its context, focusing on user intent rather than just keywords.
- Detects and blocks attempts to bypass moderation by splitting harmful content across multiple messages.
Language Support
No language limits.
How it works
The LLM moderation engine classifies content based on your configuration and recent conversation history. To set it up, you'll provide two key inputs:
App Context: A short description of your application and how users interact. This helps the LLM understand your platform's environment (e.g., casual chat, professional tone, teen audience).
LLM Rules: Clear harm categories written in plain language. For example, you might define what counts as SCAM, HATE SPEECH, or SEXUAL HARASSMENT in your community.
When a new message is sent, the engine considers:
- Your defined app context
- Your LLM rules
- The last few messages in the conversation
It then passes this information to the LLM, which classifies the message against your rule set and applies the configured moderation action (flag, block, review, etc.).
Configuration
You can set up the LLM moderation engine directly in the dashboard.
- In the dashboard, navigate to Moderation → Policies.
- Select the policy you want to update.
- Navigate to AI (LLM) Text.
- Add your app context and harm labels, then define prompts for each label.
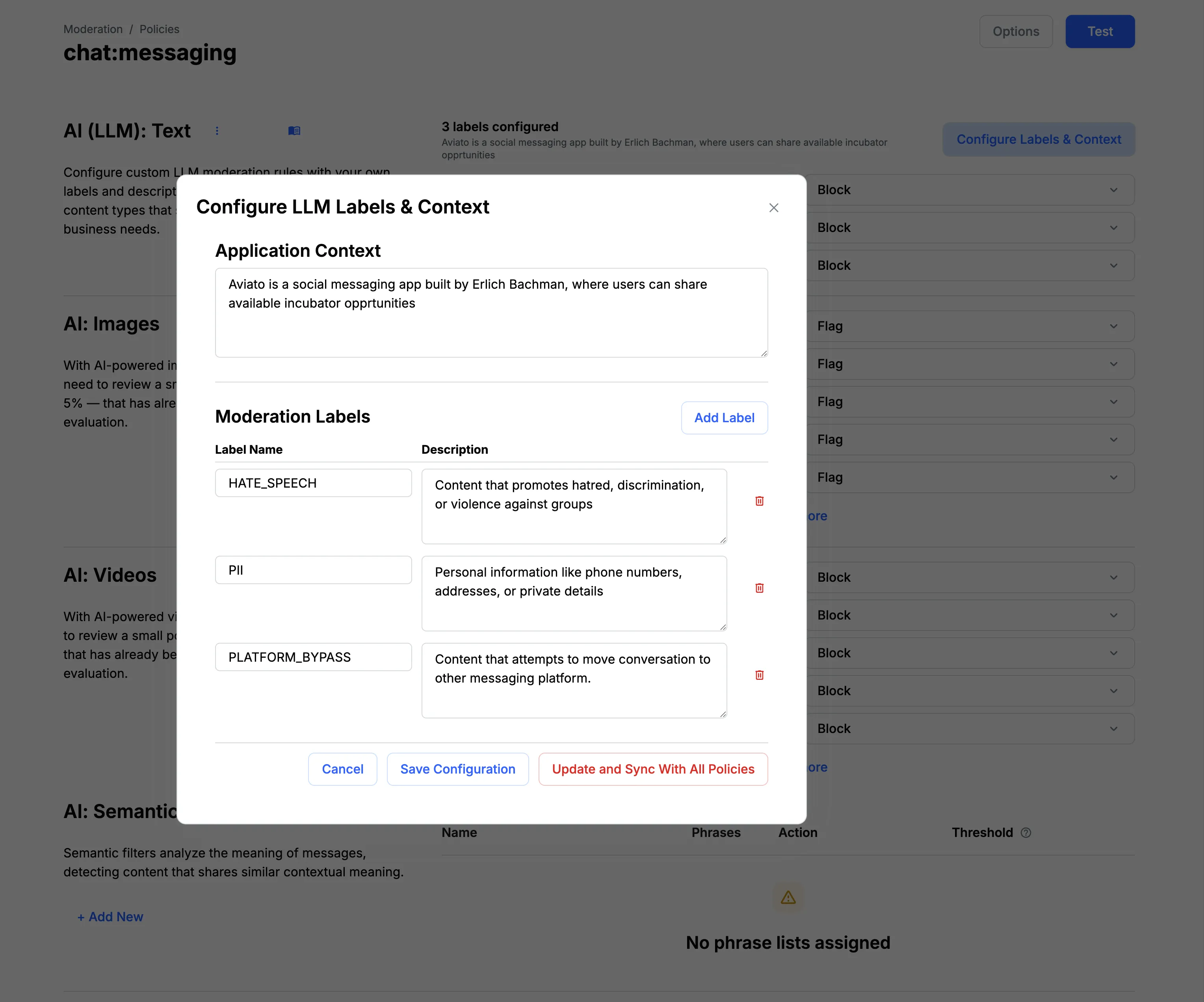
We provide starter rules like SCAM, HATE SPEECH, SEXUAL HARASSMENT, PII, and PLATFORM BYPASS to help you get started. You can edit or remove these if they're not needed.
Moderation Prompt Guide
When you set up a harm label in the dashboard, you're talking directly to the LLM, telling it what to look for. You will need two things:
Harm Label — a short, descriptive name you'll use to track this category.
Prompt — a clear instruction for the LLM to follow when deciding whether content matches that label.
Writing with Clarity & Precision
Harm Label
- Keep it short and descriptive.
- Examples:
- Scam
- Sexual Harassment
- Bullying
- Hate Speech
Prompt
- Write prompts like commands so the LLM knows exactly what to detect.
- Examples of good prompts:
- Messages where recruiters are trying to headhunt or share job descriptions.
- Fraudulent content, phishing attempts, or deceptive practices.
- Content that promotes hatred, discrimination, or violence against groups.
Best Practices: Do's and Don'ts
Do:
- Write in plain, directive language.
- Specify exactly what behaviors or content to act on.
- Keep each label focused on a single harm type.
- Periodically review and refine prompts based on fundamental user interactions.
Don't:
- Use vague, generalized terms like "bad," "inappropriate," or "offensive."
- Attempt to cover multiple harms in one label or prompt.
- Overload the prompt with too much nuance, if it's too long, break it into multiple labels.
Prompt Debugging Checklist
If something doesn't seem to work or the LLM is flagging the wrong content run through this quick checklist:
- Clarity – Is the prompt easy to understand and unambiguous?
- Scope – Is the label targeting just one type of harm?
- Context – Did you include platform-specific norms or boundaries (e.g., "casual chat", "professional tone", "teen audience")?
- Human-level testability – Would a person easily know what to flag based on your text?
- Avoid Over-censoring – Am I flagging harmless content (like jokes or slang) mistakenly?
- One-change-at-a-time – When testing, adjust only one variable so it's easier to see what worked.
- Real-conversation testing – Have you tested it on actual messages to balance what it catches vs. what it miss?
Iterate & Improve
Follow these steps to refine your prompts over time:
- Start Simple: Begin with the most important harm types.
- Test Prompts: Collect real examples and check what gets flagged or missed.
- Split When Needed: If a prompt is too broad, break it into narrower labels.
- Review & Document: Keep track of changes to know what's working (or not).
- Share Learnings: Document successful prompts in an internal library so your team can reuse proven approaches.
Why It Matters
By providing clear labels and prompts:
- The LLM can operate consistently and accurately.
- You build a safer and more trustworthy experience for your users.
- You reduce false positives, missed issues, and make moderation more efficient for your team.
Starter Prompt Library
Use these pre-made harm labels and prompts as a baseline. You can copy them directly into your dashboard and adapt them to fit your community's needs.
BULLYING Insults, threats, or repeated targeting of another user intended to cause harm.
SELF_HARM Messages where a user expresses intent to harm themselves, commit suicide, or encourages others to do so.
CHILD_SAFETY Sexual content involving minors, attempts to exploit children, or discussions of child sexual abuse material (CSAM).
TERRORISM Content that promotes or glorifies terrorism, violent extremism, or recruitment to extremist groups.
Tip: Keep prompts about detection only. Let the moderation action (flag, block, review, etc.) be configured separately in the dashboard.